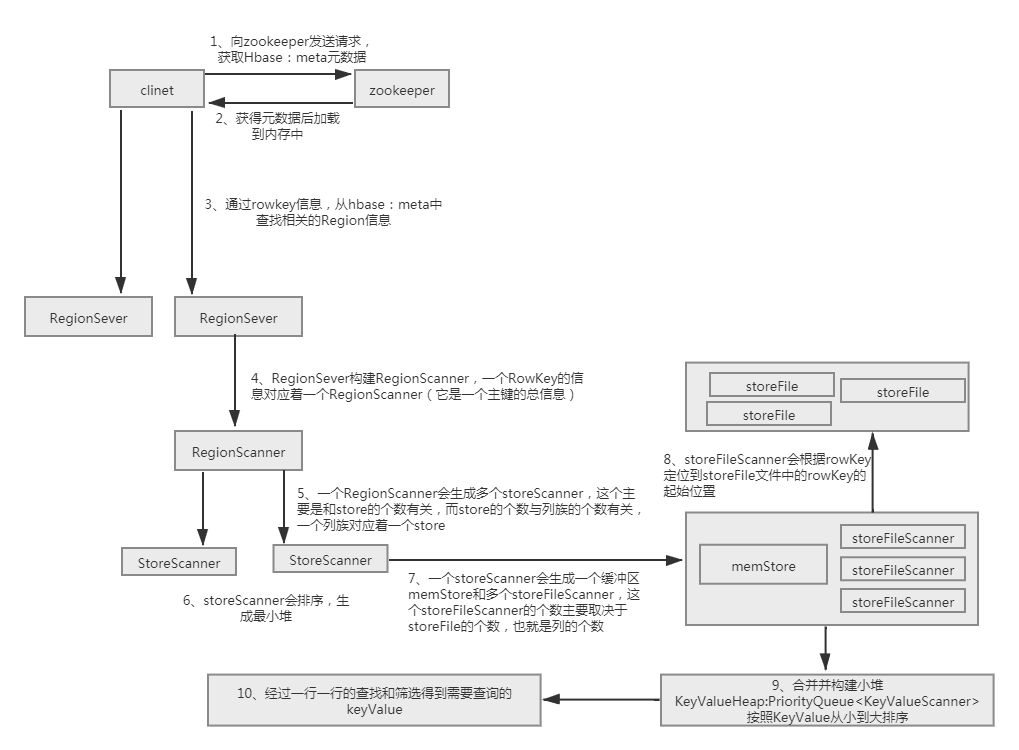
1、客户端向zookeeper发送请求,获取hbase:meta元数据
2、元数据获取后加载到内存当中
3、通过rowKey信息,从元数据中查找Region相关信息
4、RegionServer构建RegionScanner,一个RowKey的信息对应着一个RegionScanner(它是一个主键的总信息)
5、一个RegionScanner会生成多个storeScanner,这个主要和store的个数有关,而store的个数与列族的个数有关
一个列族对应着一个store
6、storeScanner会排序,生成最小堆StoreHeap:PriorityQueue<StoreScanner>
7、一个storeScanner会生成一个缓冲区memStore和多个storeFileScanner,这个storeFileScanner的个数主要取决于storeFile的个数,也就是列的个数。
8、storeFileScanner会根据rowKey定位到storeFile文件中的rowKey的起始位置
9、合并并构建小堆KeyValueHeap:PriorityQueue<KeyValueScanner>,排序规则按照keyValue从小到大排序
10、经过一行一行的查找和筛选得到需要查询的keyValue值
原文:https://www.cnblogs.com/huangwenchao0821/p/14752589.html