事务参与者:每个数据库就是一个事务参与者
事务协调者:访问多个数据源的服务程序,就是事务协调者
RM:资源管理器,通常与事务参与者同义
TM:事务管理器,通常与事务协调者同义
二阶段提交
2PC是跨数据库层面的。
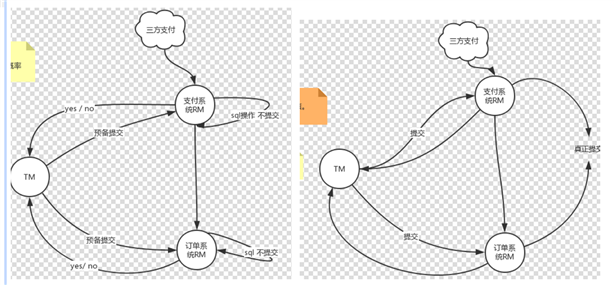
- 准备阶段:事务协调者通知所有事务参与者预备提交,事务参与者收到通知后执行 sql,并将执行结果反馈给事务协调者
- 提交阶段:如果事务协调者收到的反馈都是 yes,事务协调者通知所有事务参与者提交事务;若有任意一个事务参与者反馈为 no 或超时未反馈,事务协调者通知所有事务参与者操作回滚
优点:强一致性、成本低
缺点:
- 资源阻塞,事务参与者在执行SQL与提交事务的时间窗口内会锁住资源,想要使用这些资源的事务只能等待
- 单点问题:如果事务协调者宕机,事务可能永远无法完成,资源将会一直阻塞
- 数据不一致:事务协调者通知事务参与者提交,如果因为网络原因只有一部分事务参与者收到了消息,就会造成数据不一致
三阶段提交
- 在二阶段提交基础上增加了一个询问过程,事务协调者先询问事务参与者能否执行事务。能够降低资源锁定的概率
- 加入超时机制(事务参与者):若事务参与者向事务协调者发送了 yes 之后一直得不到协调者的响应,事务参与者就默认将超时的事务提交。避免资源被永久锁定
但是依然无法解决一致性问题:事务协调者通知所有事务参与者回滚,部分参与者因网络原因未收到消息提交了。
TCC
try、confirm、cancel 的缩写,其本质为应用层面的2PC,需要通过业务逻辑实现,原理基本与2PC一致:
- 准备阶段:事务协调者调用每个微服务提供的 try 接口,将整个事务涉及到的资源全锁住,若锁定成功返回 yes
- 提交阶段:若所有微服务 try 接口在阶段一都返回 yes,事务协调者调用所有服务的 confirm 接口提交事务。若任何一个接口反馈 no或超时,则协调者调用所有服务的 cancel 接口
若多次重试未达到最终状态,人工干预。(不要为了极低概率的事件增加研发成本)
优点:
- 强一致性
- 应用自己定义数据库操作的粒度,使得降低锁冲突、提高吞吐量成为可能
缺点:
本地消息表的最终一致性方案
下图如果不带本地消息表,就会存在以下问题:
- 如果插入订单成功了,消息发送失败该怎么办
- 消息重复消费问题
下面给出正确的实现方式:
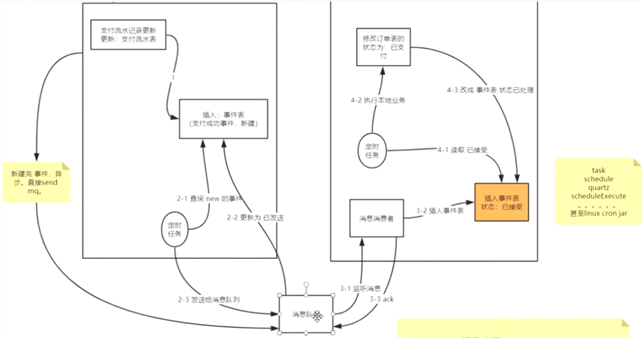
如果右边系统事务多次重试还是失败怎么办?
- 针对应该成功的事务,发送报警由人工补偿
- 针对有失败可能性的事务,要么本地回滚并通知左边系统也回滚,要么发送报警由人工来回滚或补偿。
缺点:定时任务频繁读写数据库是瓶颈。
基于RocketMQ事务消息的最终一致性方案
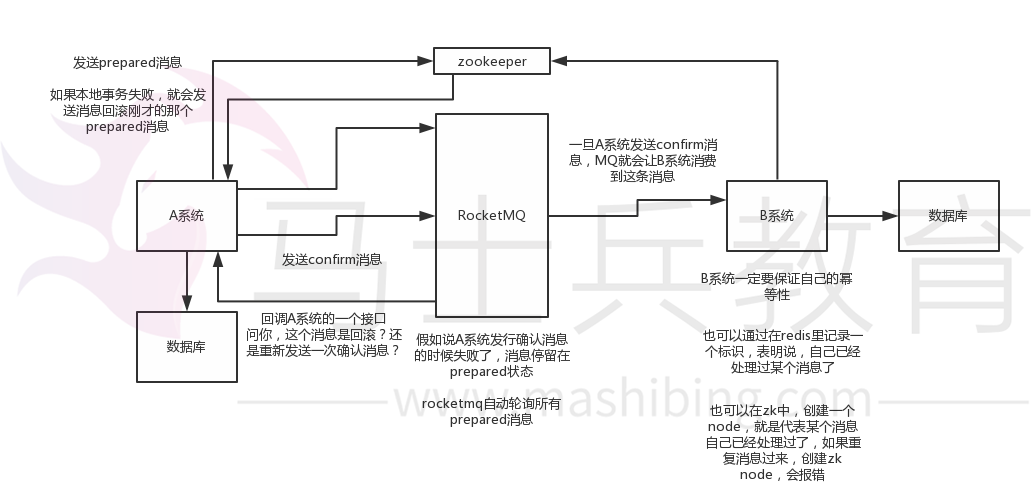
流程:
- A系统先发送一个 prepared 消息到 MQ,如果这个 prepared 消息发送失败那么就直接取消操作别执行了
- 如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉mq发送确认消息,如果失败就告诉 MQ 回滚消息
- 如果发送了确认消息,那么此时B系统会接收到确认消息,然后执行本地的事务
- MQ会自动定时轮询所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认消息?那是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,别确认消息发送失败了
注意:右边系统用 Zookeeper 吧,其高可用能够保证数据不丢。
优点: 最终一致性,不需要依赖本地数据库事务
缺点: RocketMQ事务消息部分代码也未开源,信任阿里吗?
分布式事务方案
原文:https://www.cnblogs.com/felix-1/p/14756571.html