一、概况
1、拓扑图
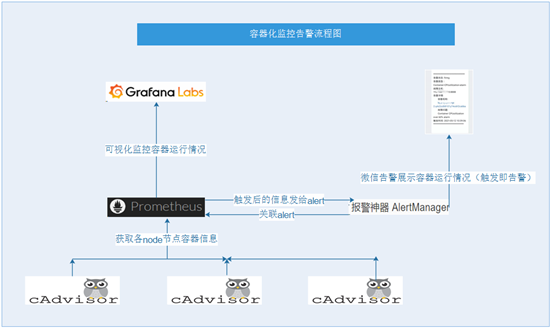
2、名词解释
Grafana 可视化监控容器运行情况 Prometheus: 开源系统监视和警报工具包 Alertmanager 一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息 Cadvisor 不仅可以搜集一台机器上所有运行的容器信息还提供基础查询界面和 http 接口,方便 Prometheus 进行数据抓取。
二、部署grafana
docker run -d -p 5000:3000 -v /home/grafana:/var/lib/grafana --name grafana grafana/grafana:latest
三、部署cadvisor
在监控的节点上部署
docker run -d -v /:/rootfs:ro -v /var/run:/var/run:ro -v /sys:/sys:ro -v /var/lib/docker/:/var/lib/docker:ro -v /dev/disk/:/dev/disk:ro -p 8888:8080 --detach=true --name=cadvisor --restart=always google/cadvisor:latest
四、部署alertmanager
4.1部署
tar xf alertmanager-0.21.0.linux-amd64.tar.gz –C /home/
主目录:/home/alertmanager-0.21.0
4.2创建启动文件
[root@autodeploy alertmanager-0.21.0]# cat start.sh
#!/bin/bash
pid=`ps -ef|grep aler|grep -v grep|awk ‘{print $2}‘`
kill -9 $pid
nohup ./alertmanager --config.file=alertmanager.yml --storage.path=data --log.level=debug &
4.3配置文件
[root@autodeploy alertmanager-0.21.0]# vim alertmanager.yml
global:
resolve_timeout: 5m
templates:
- ‘/home/alertmanager-0.21.0/rules/*.tmpl‘
route:
group_by: [‘alertname‘]
group_wait: 5s
group_interval: 1m
repeat_interval: 1m
receiver: ‘wechat‘
receivers:
- name: ‘wechat‘
wechat_configs:
- corp_id: ‘ww f53808cd2d0‘
agent_id: ‘10 0003‘
api_secret: ‘t6pdo4QRF4z_EyZWDXNlLRq-2Ahmtefu3Wt99uKyw‘
to_user: ‘@all‘
send_resolved: true
4.4报警信息模板
[root@autodeploy alertmanager-0.21.0]# cat rules/weixin.tmpl
{{ define "wechat.default.message" }}
{{ range .Alerts }}
*******************************
告警状态: {{ .Status }}
告警类型:{{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警详情:
容器名称:
{{ .Labels.name }}
故障问题:
{{ .Annotations.description }}
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
******************************
{{ end }}
{{ end }}
4.5启动告警服务
[root@autodeploy alertmanager-0.21.0]# sh start.sh
[root@autodeploy alertmanager-0.21.0]# tail -f nohup.out
4.6访问
http://ip:9093
五、部署prometheus
5.1部署
tar xf prometheus-2.25.2.linux-amd64.tar.gz –C /home/
主目录:/home/prometheus-2.25.2
5.2创建启动命令文件
[root@autodeploy prometheus-2.25.2]# cat start.sh
#!/bin/bash
pid=`ps -ef|grep prometheus|grep -v grep|awk ‘{print $2}‘`
kill -9 $pid
nohup ./prometheus --config.file=prometheus.yml &
5.3修改配置文件
[root@autodeploy prometheus-2.25.2]# vim prometheus.yml #告警关联 # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: [‘10.0.0.189:9093‘] #报警规则目录 rule_files: - "rules/*" #获取各节点数据 scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: ‘prometheus‘ # metrics_path defaults to ‘/metrics‘ # scheme defaults to ‘http‘. - job_name: ‘node_exporter‘ static_configs: - targets: - "10.0.0.194:8888" - "10.0.0.195:8888" - "10.0.0.196:8888"
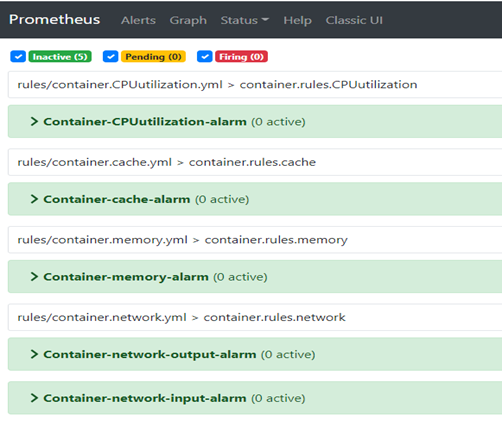
5.4告警触发规则
1、警告容器输出带宽大于50M,警告容器输入带宽大于50M
[root@autodeploy rules]# cat container.network.yml
groups:
- name: container.rules.network
rules:
- alert: Container-network-output-alarm
expr: sum by (name,instance) (irate(container_network_receive_bytes_total{instance=~"10.0.0.*:8888",name=~".+",image!=""}[3m])) /1024/1024 >0
for: 1m
labels:
severity: critical
annotations:
description: "Warning of container output bandwidth greater than 50M"
- alert: Container-network-input-alarm
expr: sum by (name,instance) (irate(container_network_transmit_bytes_total{instance=~"10.0.0.*:8888",name=~".+",image!=""}[3m])) /1024/1024 >0
for: 1m
labels:
severity: critical
annotations:
description: "Warning of container input bandwidth greater than 50M"
2、容器内存超过1000M报警
[root@autodeploy rules]# cat container.memory.yml
groups:
- name: container.rules.memory
rules:
- alert: Container-memory-alarm
expr: sum(container_memory_rss{instance=~"10.0.0.*:8888",name=~".+"}) by (name,instance) > 1000000000
for: 1m
labels:
severity: critical
annotations:
description: "Container memory over 1000M alarm"
3、告警解释容器cpu利用率超过60%
[root@autodeploy rules]# cat container.CPUutilization.yml
groups:
- name: container.rules.CPUutilization
rules:
- alert: Container-CPUutilization-alarm
expr: sum(irate(container_cpu_usage_seconds_total{instance=~"10.0.0.*:8888",name=~".+",image!=""}[1m])) without (cpu)*100>60
for: 1m
labels:
severity: critical
annotations:
description: "Container CPUutilization over 60% alarm"
容器内cpu压测,测试监控
echo "scale=5000; 4*a(1)" | bc -l -q
4、缓存使用超过500M报警
[root@autodeploy rules]# cat container.cache.yml
groups:
- name: container.rules.cache
rules:
- alert: Container-cache-alarm
expr: sum(container_memory_cache{instance=~"10.0.0.*:8888",name=~".+"}) by (name,instance) >500000000
for: 1m
labels:
severity: critical
annotations:
description: "Container cache over 500M alarm"
5.5启动监控服务
[root@autodeploy prometheus-2.25.2]# sh start.sh
[root@autodeploy prometheus-2.25.2]# tail -f nohup.out
5.6访问
http://ip:9090
友情grafana监控模板:11600
cadvisor+prometheus+alertmanager+grafana完成容器化监控告警
原文:https://www.cnblogs.com/zhj5418/p/14759242.html