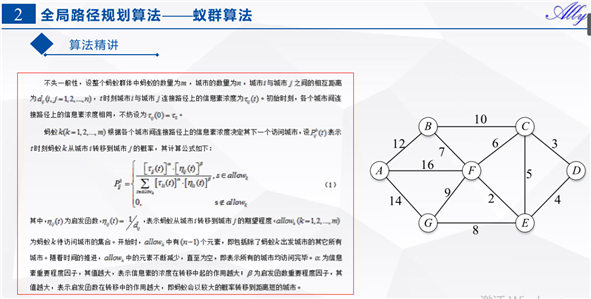
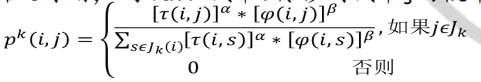
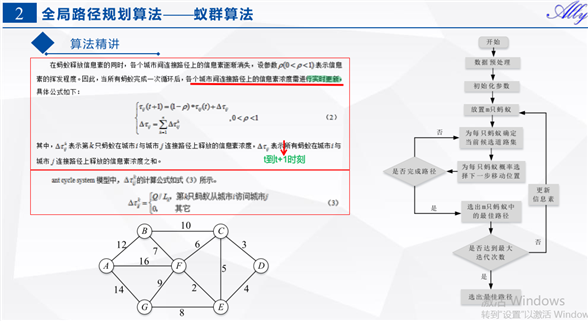
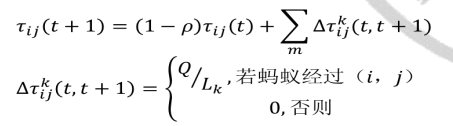
clc clear close all %% 初始化参数 % 构造图结构,根据节点的邻近节点表及字母节点-数字节点对应表,构造节点元胞数组 nodes_data = cell(0); nodes_data(1,:) = {1, [2, 6, 7], [12, 16, 14]}; nodes_data(2,:) = {2, [1, 3, 6], [12, 10, 7]}; nodes_data(3,:) = {3, [2, 4, 5, 6], [10, 3, 5, 6]}; nodes_data(4,:) = {4, [3, 5], [3, 4]}; nodes_data(5,:) = {5, [3, 4, 6, 7], [5, 4, 2, 8]}; nodes_data(6,:) = {6, [1, 2, 3, 5, 7], [16, 7, 6, 2, 9]}; nodes_data(7,:) = {7, [1, 5, 6], [14, 8, 9]}; % 始末节点 node_start = 4; % 初始源节点 node_end = 1; % 终节点 % 蚁群相关定义 m = 50; % 蚂蚁数量 n = size(nodes_data,1); % 节点数量 alpha = 1; % 信息素重要程度因子 beta = 5; % 启发函数重要程度因子 rho = 0.1; % 信息素挥发因子 Q = 1; % 常数 % 迭代过程中,相关参数初始化定义 iter = 1; % 迭代次数初值 iter_max = 100; % 最大迭代次数 Route_best = cell(iter_max,1); % 各代最佳路径 Length_best = zeros(iter_max,1); % 各代最短路径的长度 Length_ave = zeros(iter_max,1); % 各代路径的平均长度 % 将信息素、挥发因子一并放入nodes_data中 %nodes_data中存放信息 %1:节点, 2:对应节点的邻接点 3:对应节点的所有邻接点距离 %4:对应节点到各邻接点的信息素(考虑挥发因子的)5:对应节点到各邻接点的挥发因子 %Delta_Tau_initial中存放信息, %1:节点, 2:对应节点的邻接点 3:存放每一代蚂蚁从i到j释放信息素浓度累加和对应公式中DetaTao(ij) Delta_Tau_initial = nodes_data(:,1:2); for i = 1:size(nodes_data,1) nodes_data{i,4} = ones(1, length(nodes_data{i,3})); % 各结点所有邻接点信息素初始化 nodes_data{i,5} = 1./nodes_data{i,3}; % 挥发因子 Delta_Tau_initial{i,3} = zeros(1, length(nodes_data{i,3})); end %% 迭代寻找最佳路径 while iter <= iter_max route = cell(0); %% 逐个蚂蚁路径选择 for i = 1:m % 逐个节点路径选择 neighbor = cell(0); node_step = node_start; path = node_step; dist = 0; while ~ismember(node_end, path) %当路径表里面包含了终节点时,该蚂蚁完成路径寻优,跳出循环 % 寻找邻近节点 neighbor = nodes_data{node_step,2}; % 删除已经访问过的临近节点 idx = []; for k = 1:length(neighbor) if ismember(neighbor(k), path) idx(end+1) = k; end end neighbor(idx) = []; % 判断是否进入死胡同, 若是,直接返回到起点,重新寻路 if isempty(neighbor) neighbor = cell(0); node_step = node_start; path = node_step; dist = 0; continue end %计算此结点到各邻结点的访问概率 P = neighbor; for k=1:length(P) P(2,k) = nodes_data{node_step, 4}(k)^alpha * ... nodes_data{node_step, 5}(k)^beta; %对应公式(1)分子部分 end P(2,:) = P(2,:)/sum(P(2,:)); %此结点到各邻结点的概率 % 轮盘赌法选择下一个访问节点 %随机选取访问的下一个节点,访问节点的概率越大,被选中的几率越大 Pc = cumsum(P(2,:)); Pc = [0, Pc]; randnum = rand; for k = 1:length(Pc)-1 if randnum > Pc(k) && randnum < Pc(k+1) target_node = neighbor(k); end end % 计算单步距离 idx_temp = find(nodes_data{node_step, 2} == target_node); %寻找目标节点在此节点数据第二列中的下指标 dist = dist + nodes_data{node_step, 3}(idx_temp); % 将目标节点作为下一个‘起始’节点,保存行驶路径 node_step = target_node; path(end+1) = node_step; end % ***存放第i只蚂蚁的累计距离及对应路径 Length(i,1) = dist; route{i,1} = path; end %% 计算这一代的m只蚂蚁中最短距离及对应路径 if iter == 1 [min_Length,min_index] = min(Length); Length_best(iter) = min_Length; %第一代的最短路径长度 Length_ave(iter) = mean(Length); %第一代蚂蚁所走路径的均值 Route_best{iter,1} = route{min_index,1}; else [min_Length,min_index] = min(Length); Length_best(iter) = min(Length_best(iter - 1),min_Length); %与之前几代相比,得到达这一代时,最短路径长度 Length_ave(iter) = mean(Length); %每一代蚂蚁所走路径的均值 if Length_best(iter) == min_Length %如果最短路径长度是来自这一代的话,将这一代最短路径设置为这一代的最短路径 Route_best{iter,1} = route{min_index,1}; %否则设置为上一代最短路径 else Route_best{iter,1} = Route_best{iter-1,1}; end end %% 更新信息素 % 计算每一条路径上的经过的蚂蚁留下的信息素 Delta_Tau = Delta_Tau_initial; % 逐个蚂蚁计算 for i = 1:m % 逐个节点间计算 for j = 1:length(route{i,1})-1 node_start_temp = route{i,1}(j); node_end_temp = route{i,1}(j+1); idx = find(Delta_Tau{node_start_temp, 2} == node_end_temp); Delta_Tau{node_start_temp,3}(idx) = Delta_Tau{node_start_temp,3}(idx) + Q/Length(i);%对应公式(3)以及公式(2)下面式子 end end % 考虑挥发因子,更新信息素 for i = 1:size(nodes_data, 1) nodes_data{i, 4} = (1-rho) * nodes_data{i, 4} + Delta_Tau{i, 3}; %对应公式(2)上面部分 end % 更新迭代次数 iter = iter + 1; end %% 绘图、结果 figure plot(1:iter_max,Length_best,‘b‘,1:iter_max,Length_ave,‘r‘) legend(‘最短距离‘,‘平均距离‘) xlabel(‘迭代次数‘) ylabel(‘距离‘) title(‘各代最短距离与平均距离对比‘) % 最优路径 [dist_min, idx] = min(Length_best); path_opt = Route_best{idx,1};
原文:https://www.cnblogs.com/zhjblogs/p/14760436.html