关键词分两种:
可以从标题中提取,也可从正文中提取。
从人的认知来理解什么是关键词,关键词一般具有以下特征:
由此我们找到了一种方法,在全量文章中,计算每个词的Tf*Idf值,值越大,这个词为关键词的可能性越高,取Top5为关键词。
关键词得分 = Tf * Idf
这提取关键词的方法缺点:
1.没有考虑词的搭配。分词的时候可能吧关键词拆分成两个词。比如说:人工 + 智能。
2.单纯从词频考虑,的,了这些词的频率也很高。而他们几乎不可能称为关键词。
缺点2:单纯从词频考虑,的,了这些词的频率也很高。而他们几乎不可能称为关键词。
怎么优化呢?
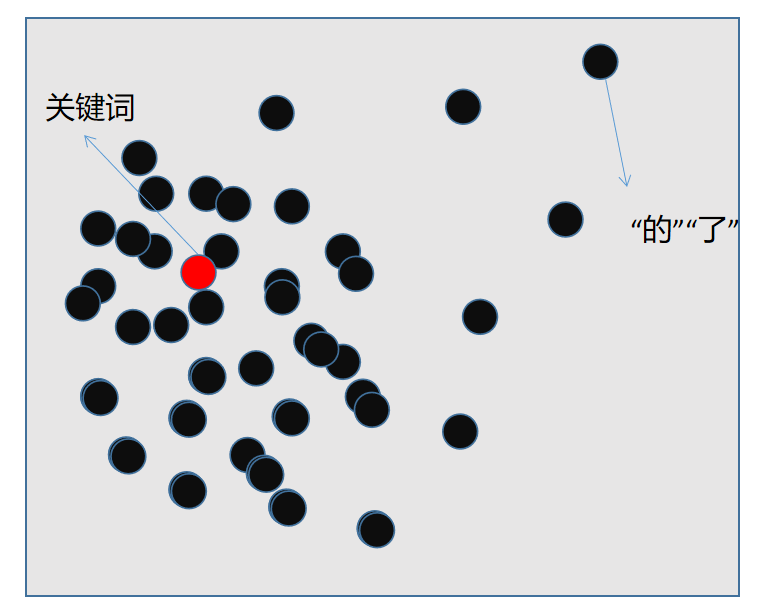 在词向量空间中,的了这些词往往和其他词距离较大。根绝这个特征找到了一种替代词频的方法:
在词向量空间中,的了这些词往往和其他词距离较大。根绝这个特征找到了一种替代词频的方法:
对每个词,计算其他所有词和他的距离,求和之后除以总词数。得到中心度X
优化后的关键词得分为: X * Idf。
通过这种方法处理之后得到的关键词,仍然会有Badcase:
企业解决方案:
产品或者业务经理会根据业务领域,或者按领域制定 关键词表 。词数大概在20w-30w之间。
新词发现:这个词表是动态的,每天更新。
每天都会处理一些新文章,算法提取出来关键词之后,统计每个关键词出现的文章数。-->
过滤掉在关键词表中的词。-->
b把不在关键词表里的 词 -词频 交给产品经理审核。
1.对标题提取关键词集合A = { x1, x2, ...}
2.对正文提取关键词集合B = {y1, y2, ...}
硬方法:直接取交集
软方法:a. 增加提取词数 b.加权求和正文和标题关键词。
| 关键词出现在 | 权重 | 马云 | 马化腾 | 无人机 | 人工智能 | 马斯克 |
| 标题关键词得分 | 2.0 | 0.3 | 0.3 | 0.1 | 0.2 | 0.3 |
| 正文关键词得分 | 1.0 | 0.4 | 0.4 | 0.5 | 0.3 | 0.3 |
| 加权求和 | 0.7 | 0.7 | 0.6 | 0.5 | 0.6 | |
| 结论:关键词取 马云、 马化腾 | ||||||
原文:https://www.cnblogs.com/gl0520/p/14764132.html