基于高斯分布的方法
一元检测的代码
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
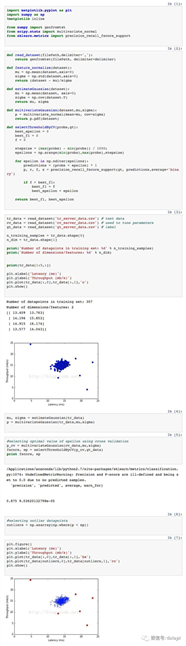
# 随机生成的数据
data = np.random.randn(50000)*50 + 20
sns.boxplot(data=data)
简单来说就是降维,先求每个维度的概率,再合并,降到一维,最终目的是求样本的概率密度
利用generate_data函数生成异常值占比为10%的toy set
from pyod.utils.data import generate_data,evaluate_print
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
X_train, y_train, X_test, y_test = generate_data(
n_train=n_train, n_test=n_test, contamination=contamination)
导入hbos,生成一个HBOS的异常检测器对象。 用fit()方法拟合数据
from pyod.models import hbos
from pyod.utils.example import visualize
clf = hbos.HBOS()
clf.fit(X_train)
y_train_pred = clf.labels_
y_train_socres = clf.decision_scores_
y_test_pred = clf.predict(X_test) # 返回未知数据上的分类标签 (0: 正常值, 1: 异常值)
y_test_scores = clf.decision_function(X_test) # 返回未知数据上的异常值 (分值越大越异常)
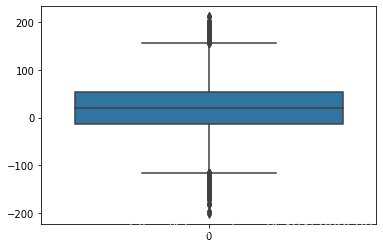
获得结果并进行可视化观察
clf_name = ‘HBOS‘
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
在异常检测的非参数方法中,正常数据的模型从输入数据进行学习,而非假定一个先验,非参数方法通常对数据做较少的假定,因此在很多场景下可以使用,如采用直方图进行异常检测:
采用直方图的方法是一种非参数方法(不需要对数据的分布进行假定),但是缺点在于需要指定直方图的相关参数(如箱子是等宽还是等深的,直方图中每个箱子的大小等),如果箱子太小,则许多正常对象会被误认为异常点,而箱子太大时许多异常点会被认为是正常的。
原文:https://www.cnblogs.com/Vincy-BLOG/p/14768058.html