大家好,我是白泽,最近学校有点事Redis知识点的更新就放缓了,趁着周六赶紧补一补,我们开始吧~
对于有序列表的查找来说,无法找到类似用在有序数组上的二分查找这样的查找算法,因此遍历的效率比较低,跳跃表的出现就是为了提高有序链表的遍历效率
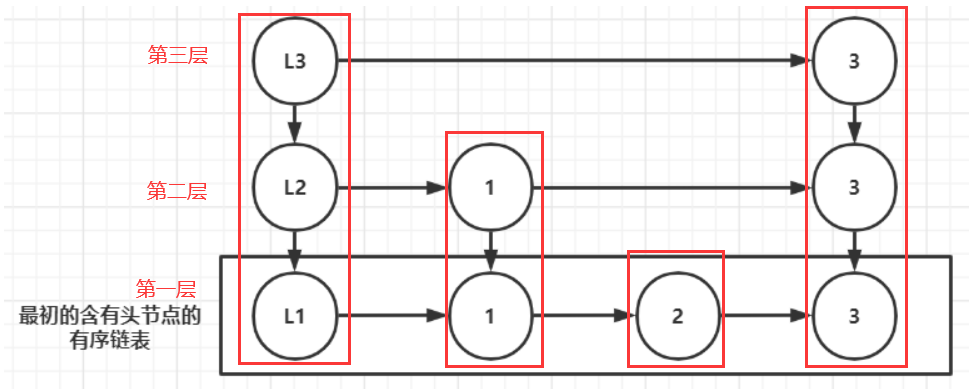
下图是概念上的跳跃表,框中的部分是原始的有序链表,我们将其进行改造,抽离成多层,属于同一列的节点的值相同,这就是一个跳跃表的雏形了(L1、L2、L3是每层对应的头节点,此时共3层),然后我们就能用跳跃表来简化我们的有序链表的查询操作
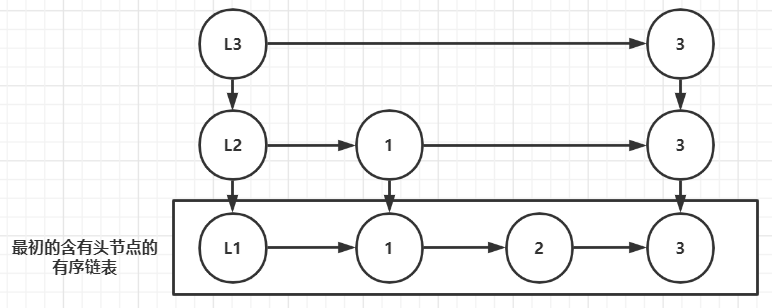
此时你应该很疑惑,跳跃表是如何从一个有序单列表抽离成很多层的从而得到跳跃表的,很遗憾,跳跃表的建立将设计概率论的一些知识,我认为现在讲解这部分并不合适,所以请假设跳跃表已经由一个有序单列表出发并建立成功了,接下来我们来看看跳跃表是如何简化有序链表的查询操作的
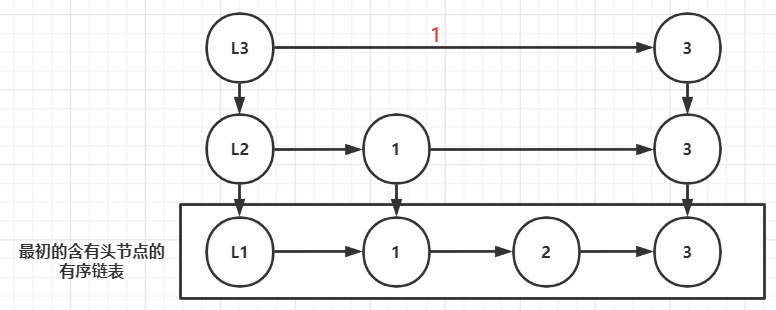
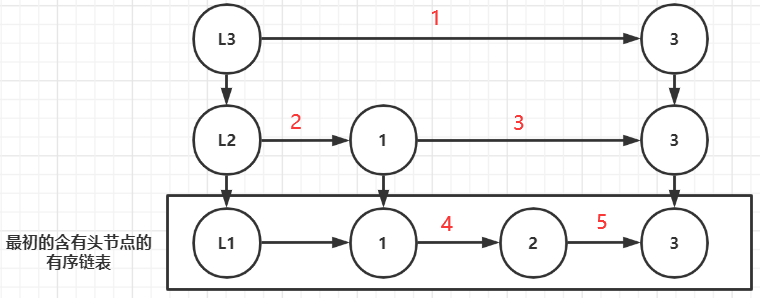
查询规则:如果查询目标大于当前值,查当前节点的后一个(同层),如果小于当前值,则下降到当前节点的前一个节点的正下方,并从该节点的后一个开始查询(正下方节点不用查),如果已经下降到第一层,且查到某个值已经大于查询目标的值,则表示目标表示不存在,无需继续查询
Redis的跳跃表本质上就是上面我们提到的跳跃表,它由一个个跳跃表Node节点组成,而整体由一个list表示,由list表示是因为list记录了listNode网络的头指针,尾指针,层数,长度信息,有了list就可以操作跳跃表,这种list的用法出现在绝大多数Redis的数据结构中
光看下面这张图你可能很疑惑,这和上面的跳跃表结构图并不相同,别急,往下看~
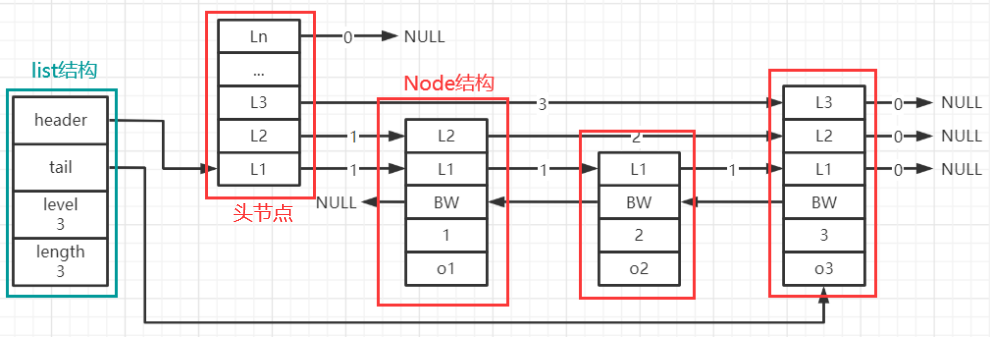
跳跃表的list结构实现
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//表头节点和表尾节点
unsigned long length; //表中的节点数量
int level; //表中层数最大的节点数量
}
跳跃表的Node节点实现
typedef struct zskiplistNode {
//后退指针,指向前一个节点的位置,用于逆向遍历顺序链表
struct zskiplistNode *backward;
//分值,因为需要建立有序链表,因此需要一个值去度量顺序
double score;
//成员对象,用于存放可能需要保存的对象
robj *obj;
//层
struct zskiplistLevel {
//前进指针
struct zskiplistNode *forward;
//跨度(上图箭头上的数值表示跨过了几个节点)
unsigned int span;
} level[];
} zskiplistNode;
listNode中最重要的是level[]数组,这个数组就是图上每个Node节点的L1~Ln的部分,它的作用就是虽然我们整个Redis跳跃表只有n个节点,但是我们在逻辑上将其抽离成了多层:同一列上节点,各个层其实共用一个节点,并没有新创建多余的节点
上面整个跳跃表在Redis中只要4个listNode节点就能组成,且用一个list结构表示,如下:
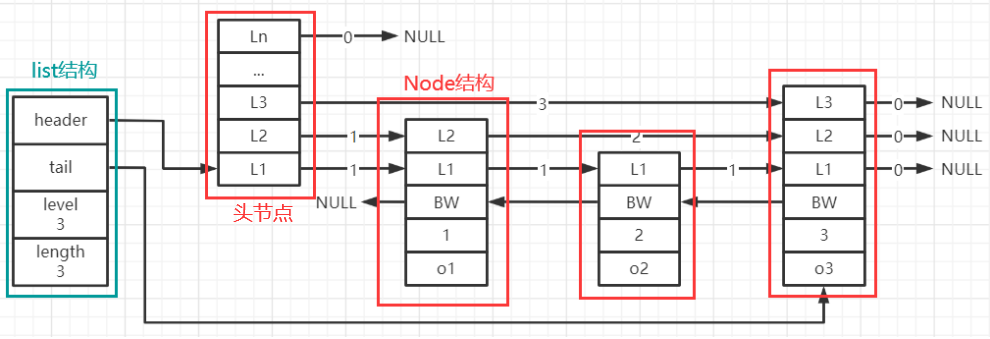
再说一遍:每个红框只代表一个listNode节点,而它内部的level[]数组,举个例子:
节点A的level[1]的forward属性表示:如果将节点A当作在第一层上,该节点的后一个节点的指针
同理,节点A的level[2]的forward属性表示:如果将节点A当作在第二层,该节点的后一个节点的指针
你一定要好好理解:level[i]中存放的是第i层上,当前节点的下一个节点的地址,每个节点是被各层共享的,不同的是在各层上,它指向的下一个节点的地址不同
每层形成长短不一的有序链表,配合下降层数进行有序链表的查询,效率更高
原文:https://www.cnblogs.com/YLTFY1998/p/14771977.html