Linux内核主要由以下模块组成:进程管理、中断处理、内存管理、文件系统。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
所有运行在Linux操作系统中的进程都被task_struct结构管理,该结构同时被叫作进程描述。一个进程描述包含一个运行进程所有的必要信息,例如进程标识、进程属性和构建进程的资源。每一个进程都有其生命周期,例如创建、运行、终止和消除。这些阶段会在系统启动和运行中重复无数次。
fork系统调用用于从已存在进程中创建一个新进程,新进程称为子进程,而原进程称为父进程。fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的进程号,而子进程中的返回值则返回 0。因此,可以通过返回值来判定该进程是父进程还是子进程。
exec系统调用是以新的进程去代替原来的进程,但进程的PID保持不变。因此,可以这样认为,exec系统调用并没有创建新的进程,只是替换了原来进程上下文的内容。原进程的代码段,数据段,堆栈段被新的进程所代替。
中断处理是优先级最高的任务之一。中断通常由I/O设备产生。中断处理器通过一个事件通知内核,它让内核中断进程的执行,并尽可能快地执行中断处理,因为一些设备需要快速的响应。当一个中断信号到达内核,内核必须切换当前的进程到一个新的中断处理进程。这意味着中断引起了上下文切换,因此大量的中断将会引起性能的下降。
在Linux的实现中,有两种类型的中断:硬中断是由请求响应的设备发出的(磁盘I/O中断、网络适配器中断、键盘中断、鼠标中断);软中断被用于处理可以延迟的任务(TCP/IP操作,SCSI协议操作等等)。
Linux采用虚拟内存管理技术,每个进程都有独立的进程地址空间。虚拟内存技术是基于交换技术(swap)的,只不过交换的是页或者段。
当进程要求运行的时,不是将他的全部信息装入内存,而是将其一部分先装入内存,另一部分暂时留在外存,进程在运行过程中,要使用信息不在内存时,发生中断,由操作系统将他们调如内存,以保证进程的正常运行。内核使用一个内存管理程序来检测最近没有使用的内存块(内存页)。内存管理程序将这些相对不经常使用的内存页交换到硬盘上专门指定用于“分页”或交换的特殊分区。那些换出到硬盘的内存页面被内核的内存管理代码跟踪,如果需要,可以被分页回 RAM。
在Linux内部的地址的映射过程为逻辑地址–>线性地址–>物理地址,逻辑地址经段机制转化成线性地址;线性地址又经过页机制转化为物理地址。
Linux以文件的形式对计算机中的数据和硬件资源进行管理,也就是一切皆文件。反映在Linux的文件类型上就是:普通文件、目录文件(也就是文件夹)、设备文件、链接文件、管道文件、套接字文件(数据通信的接口)等等。这些种类繁多的文件被Linux使用目录树进行管理, 所谓的目录树就是以根目录(/)为主,向下呈现分支状的一种文件结构。
首先调用系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个缓冲区,将多次小数据量相邻写操作先缓存起来,合并,最终调用write函数一次性写入。Write函数通过调用系统调用接口,将数据从应用层复制到内核层,所以write会触发内核态/用户态切换。当数据到达页缓存后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write是一个异步调用。read调用是先检查页缓存里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。
Linux系统下影响程序性能表现的因素主要可以分为以下4点:
(1)CPU:CPU 的速度与性能很大一部分决定了系统整体的性能,CPU的调度策略和代码优化策略也会对程序执行产生影响。
(2)内存:Linux虚拟内存虽然可以缓解物理内存的不足,但是占用过多的虚拟内存,应用程序的性能将明显下降,要保证应用程序的高性能运行,物理内存也要足够。
(3)磁盘读写(I/O)能力:磁盘的 I/O 能力会直接影响应用程序的性能。比如说,在一个需要频繁读写的应用中,如果磁盘 I/O 性能得不到满足,就会导致应用的停滞。
(4)网络带宽:低速的、不稳定的网络将导致网络应用程序的访问阻塞;而稳定、高速的带宽,可以保证应用程序在网络上畅通无阻地运行。
由于CPU会采用程序先前运行的历史记录来判断下一步分支的走向,如果猜对了,处理器不需要暂停,继续往下执行;如果猜错了,只能暂停运行,等待之前的指令运行结束。然后才能继续沿着正确地路径往下走,由此就会带来程序执行性能的下降。
以下为测试代码:首先对随机产生的数组不排序编译执行,然后对随机数组排序后编译执行。
1 #include <algorithm> 2 #include <ctime> 3 #include <iostream> 4 5 int main() 6 { 7 //测试用的数组 8 const int arr_len = 32768; 9 int data[arr_len]; 10 11 for (int c = 0; c < arr_len; ++c) 12 data[c] = std::rand() % 256; 13 14 //std::sort(data, data + arr_len); // 是否排序 15 16 long long sum = 0; 17 18 for (int i = 0; i < 30000; ++i) 19 { 20 for (int c = 0; c < arr_len; ++c) 21 { 22 if (data[c] >= 128) { // 故意选 256 一半 23 sum += data[c]; 24 } 25 } 26 } 27 28 std::cout << "sum = " << sum << std::endl; 29 }
使用perf进行性能分析如下:
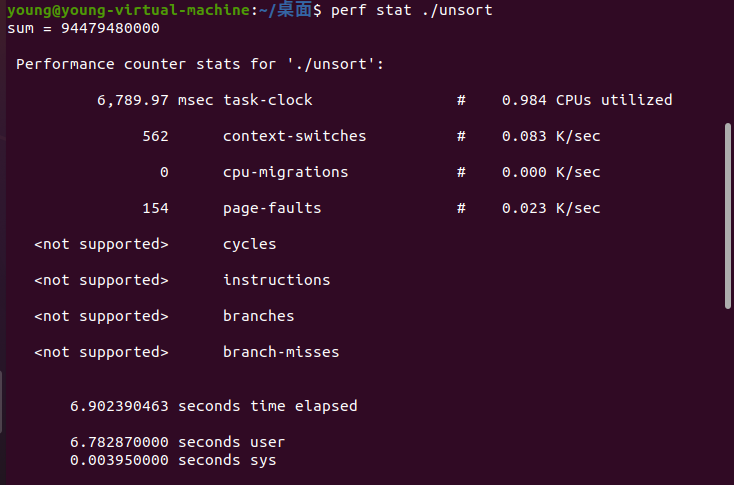
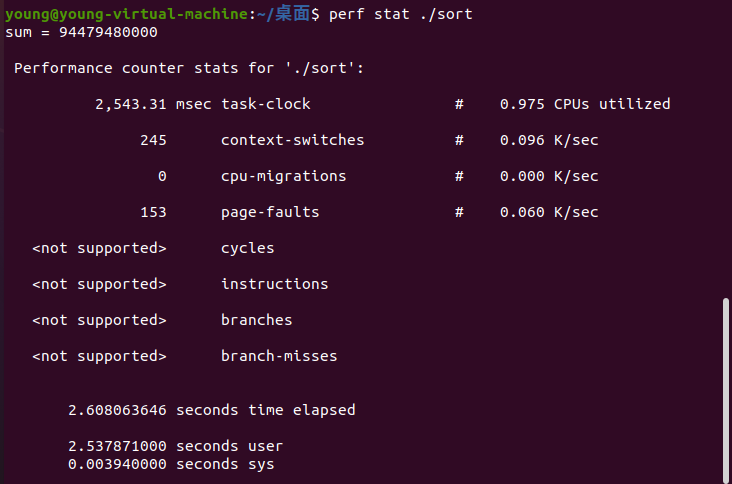
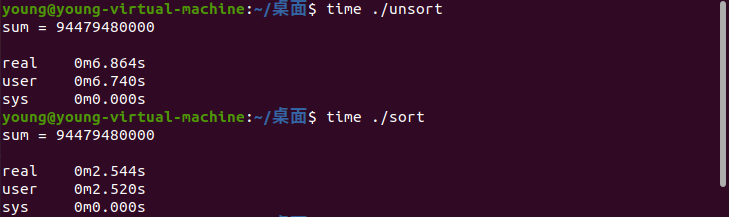
由分析结果可知,即便经过了额外的排序消耗,排序后的程序执行时间依然比未排序的程序快了将近2.7倍。
原因分析:对随机产生的数组不排序编译执行,那么分支预测的结果就具有随机性;对随机数组排序后编译执行,那么分支预测的结果就大部分情况会命中。
说明CPU的分支预测是影响分支程序执行性能的重要因素。
原文:https://www.cnblogs.com/stelo/p/14772351.html