1.性能: HashTable,Collections.synchronizedMap,无论读或者写操作,都会对整个集合加锁,导致同一时间的其他操作阻塞。
ConcurrentHashMap 在 1.7 版本使用的数据结构是Segment数组 的结构,同 HashMap 类似,Segment 包含一个 HashEntry 数组,数组中每个元素都是一个链表的头结点。可以理解为 ConcurrentHashMap 为一个二级哈希表,在一个总的哈希表的下面,有若干个子哈希表
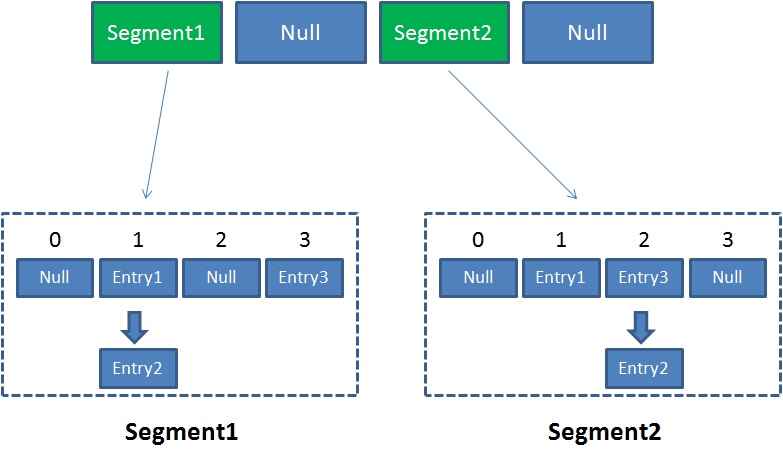
采取 Segment 这种数据结构的好处就在于,可以进行分段加锁。
相较于 HashTable 对整个结合加锁,ConcurrentHashMap 每次加锁的对象都是某个 Segment,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
多线程下,不同线程对不同分段的之间的读写是可以并发的,同时,对同一个分段的读是可以并发的
ConcurrentHashMap get方法的流程如下:
1.对输入的 Key 做 Hash 运算,得到 Hash 值
2.通过 Hash 值,定位到Segment 数组下标
3.获取可重入锁
4.通过 Hash 值,定位到 Segment中 Entry 数组的具体下标
5.插入或者覆盖对象
6.释放锁
读写都需要二次定位
大体的思想:不停的循环,直到某次循环中,Segment 修改次数和上一次相同。如果大于,则再次重新统计。统计次数超过一定阈值后,会对 Segment 加锁进行统计。
ConcurrentHashMap 在1.8 中的数据结构从原有的Segment+HashEntry 变成了 Synchronized+Cas+Node
不再使用 Segment 后,1.8 中的 ConcurrentHashMap 的结构类似 HashMap,变成了数组+链表+红黑树,可以直接定位到数组下标。同时采用 CAS+Synchronized 来保证并发更新安全.
CAS算法:在线程开启的时候,会从主存中给每个线程拷贝一个变量副本到线程各自的运行环境中,CAS算法中包含三个参数(V,E,N),V表示要更新的变量(也就是从主存中拷贝过来的值)、E表示预期的值、N表示新值。
其实就是拿副本中的预期值与主存中的值作比较,如果相等就继续替换新值,如果不相等就说明主存中的值已经被别的线程修改,就继续重试;
CAS(比较并交换)是CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了
只能保证一个共享变量原子操作;
会出现ABA问题;
当添加新元素后,元素的个数达到扩容阈值触发扩容
如何计算量级?
ConcurrentHashMap 内部定义了一个CounterCell 类,用于记录,这个类中的 value 属性使用 volatile 修饰,来保证并发下的可见性
ConcurrentHashMap 实例化了一个CounterCell数组,每当新增元素的时候,CounterCell就会在某个元素上使用 CAS 进行+1。
当需要获取全部元素的时候,统计CounterCell数组每个元素的合即可
扩容时会对每个头结点上锁,防止插入。然后在新申请的数组上进行 rehash。分配结束后将新的内存地址指向原有引用
1.构建一个nextTable,大小为table的两倍。
为了防止多个线程同时进行扩容,sizeCtl参数为 volatile ,保证可见性。保证只有一个线程能够构建 nextTable。
2.把table的数据复制到nextTable中。
put操作采用 cas+Synchronized 来实现并发插入或者更新操作
1.对 Key进行 Hash
2.在 table中定位索引的位置 n 是 table 的大小
3.获取 table中对应的索引的元素 f,( table 是 volatile 修饰的)。
4.如果 f为 null使用 Cas 插入或者更新元素,如果 cas 失败了,则会自旋重新尝试
5.如果不为空,则采用尾插法插入,采用 Synchronized 加锁头结点
1.计算 table 是否为空如果为空则返回 Null
2.计算 key 的 hash值,并获取指定 table 中指定位置的 Node 节点,通过遍历链表或者树结构找到对应的节点,返回 value 值
concurrentHashMap 读操作不加锁的原因在于使用了 volatile 关键字来修饰 Node的 value 和 next保证可见性。
而数组上的 volatile 是为了保证 Node数组在扩容的时候对其他线程具有可见性
原文:https://www.cnblogs.com/LeeBoom/p/mian-shi-ti6concurrenthashmap-jie-xi.html