为了能够将查询到的结果,在日志中显示出来,我们需要简单配置下,灵感来源于Django的启动文件wsgi.py。
只需简单几行,我们就能够在不启动项目的情况下,达到实验的目的。
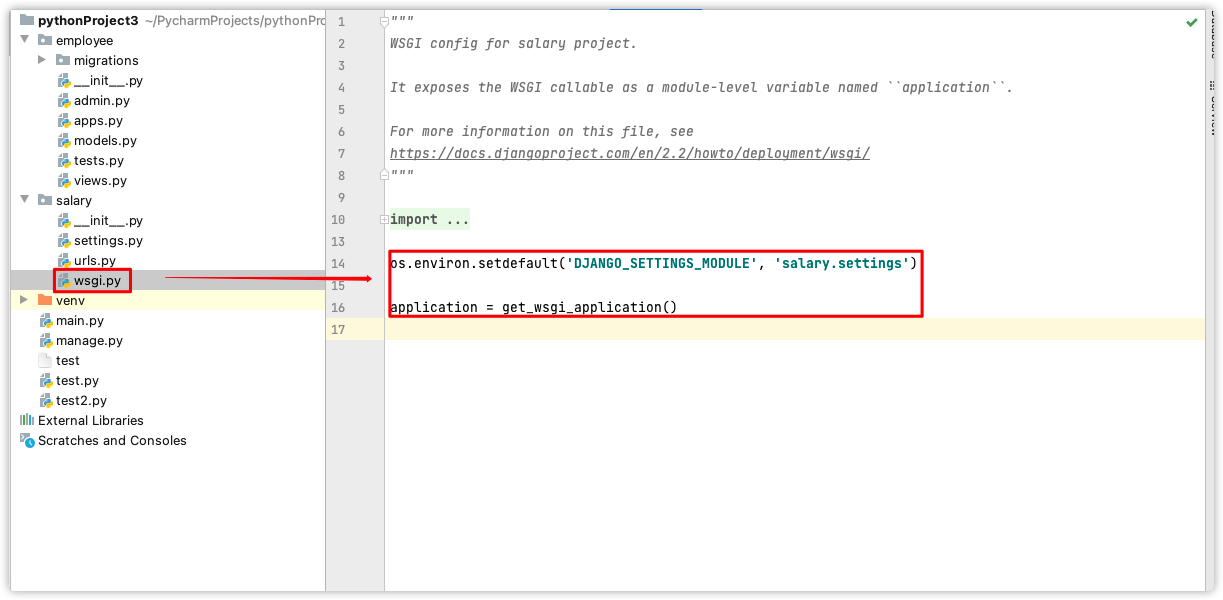
在主项目目录下新建test.py 文件
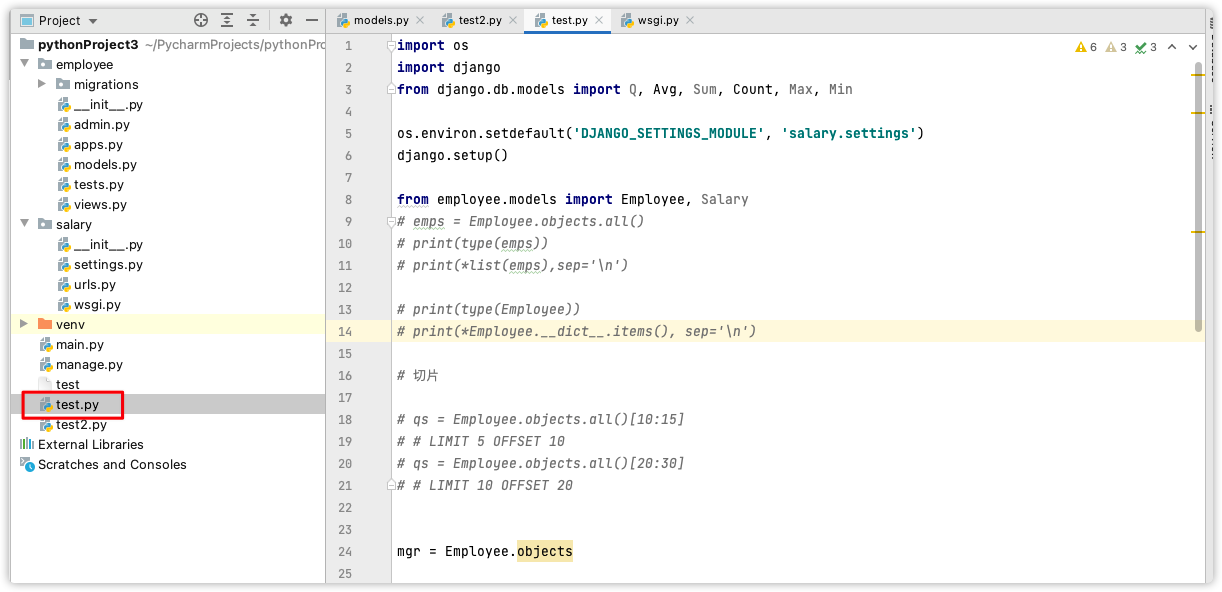
配置如下
import os import django # 参考wsgi.py os.environ.setdefault(‘DJANGO_SETTINGS_MODULE‘, ‘salary.settings‘) django.setup() # 访问数据,一定要写在上面四行之后 from employee.models import Employee emps = Employee.objects.all() # 结果集,本句不发起查询 print(type(emps)) print(*list(emps), sep=‘\n‘) # 所有员工
到这里,准备工作做完了
Django会为模型类提供一个objects对象,它是django.db.models.manager.Manager类型,用于与数
据库交互。当定义模型类的时候没有指定管理器,则Django会为模型类提供一个objects的管理器。
如果在模型类中手动指定管理器后,Django不再提供默认的objects的管理器了。
管理器是Django的模型进行数据库查询操作的接口,Django应用的每个模型都至少拥有一个管理器。
用户也可以自定义管理器类,继承自django.db.models.manager.Manager,实现表级别控制。
qs = Employee.objects.all()[10:15] # LIMIT 5 OFFSET 10 qs = Employee.objects.all()[20:30] # LIMIT 10 OFFSET 20
|
名称
|
说明
|
|
all()
|
|
|
filter()
|
过滤,返回满足条件的数据 |
|
exclude()
|
排除,排除满足条件的数据 |
|
order_by()
|
排序,注意参数是字符串
|
|
values()
|
返回一个对象字典的列表,列表的元素是字典,字典内是字段和值的键值对
|
mgr = Employee.objects # 结果集方法 print(mgr.all()) print(mgr.values()) print(mgr.filter(pk=10010).values()) print(mgr.exclude(emp_no=10001)) print(mgr.exclude(emp_no=10002).order_by(‘emp_no‘)) print(mgr.exclude(emp_no=10002).order_by(‘-pk‘)) print(mgr.exclude(emp_no=10002).order_by(‘-pk‘).values())
| 名称 | 说明 |
|
get()
|
仅返回单个满足条件的对象
如果未能返回对象则抛出DoesNotExist异常;如果能返回多条,抛出
MultipleObjectsReturned异常
|
|
count()
|
返回当前查询的总条数
|
|
first()
|
返回第一个对象
|
|
last()
|
返回最后一个对象
|
|
exist()
|
判断查询集中是否有数据,如果有则返回True
|
# first()/last()方法比get温和,没有查询到结果时会返回none,并不会像get()那样报错 # 单个值方法 print(mgr.first()) print(mgr.all().values().first()) print(mgr.exclude(pk=10010).last()) print(mgr.filter(pk=10010,gender=1).first()) print(mgr.filter(pk=10010).values().first()) print(mgr.count()) print(mgr.exclude(pk=10010).count())
| 名称 | 举例 | 说明 |
|
exact
|
filter(isdeleted=False)
filter(isdeleted__exact=False)
|
严格等于,可省略不写
|
|
contains
|
exclude(title__contains=‘天‘)
|
是否包含,大小写敏感,
等价于 like ‘%天%‘
|
|
startswith
endswith
|
filter(title__startswith=‘天‘)
|
以什么开头或结尾,大小
写敏感
|
|
isnull
isnotnull
|
filter(title__isnull=False)
|
是否为null
|
|
iexact
icontains
istartswith
iendswith
|
||
|
in
|
filter(pk__in=[1,2,3,100])
|
是否在指定范围数据中
|
|
gt、gte
lt、lte
|
filter(id__gt=3)
filter(pk__lte=6 )
filter(pub_date__gt=date(2000,1,1))
|
大于、小于等
|
|
year、month、
day
week_day
hour、minute、
second
|
filter(pub_date__year=2000)
|
对日期类型属性处理
|
# 字段查询,相当于sql语句的where print(mgr.filter(emp_no__exact=10010)) # 就是等于,所以很少用exact。emp_no__exact=10010 相当于 emp_no=10010 print(mgr.filter(pk__in=[10010,100009])) print(mgr.filter(last_name__startswith=‘P‘)) print(mgr.exclude(pk__gt=10003))
虽然Django提供传入条件的方式,但是不方便,它还提供了Q对象来解决。
Q对象是django.db.models.Q,可以使用&、|操作符来组成逻辑表达式。 ~ 表示not。
print(mgr.filter(Q(pk__lt=10006))) # 不如直接写print(mgr.filter(pk__lt=10006)) # 下面几句一样 "与" print(mgr.filter(pk__gt=10003).filter(pk__lt=10006)) # 与 print(mgr.filter(pk__gt=10003,pk__lt=10006)) print(mgr.filter(pk__gt=10003) & mgr.filter(pk__lt=10006)) print(mgr.filter(Q(pk__gt=10003),Q(pk__lt=10006))) print(mgr.filter(Q(pk__gt=10003) & Q(pk__lt=10006))) # 下面几句一样 "或" print(mgr.filter(pk__in=[10003,10006])) print(mgr.filter(pk=10003) | mgr.filter(pk=10006)) print(mgr.filter(Q(pk=10003) | Q(pk=10006))) # 下面几句一样 "非" print(mgr.exclude(pk=10003)) print(mgr.filter(~Q(pk=10003)))
# 聚合 print(mgr.filter(pk__gt=10010).count()) print(mgr.filter(pk__gt=10010).aggregate(Count(‘pk‘), Max(‘pk‘))) print(mgr.filter(pk__gt=10010).aggregate(Avg(‘pk‘))) print(mgr.filter(pk__gt=10010).aggregate(Max(‘pk‘), min=Min(‘pk‘))) # min=Min(‘pk‘) 别名 # 分组 print(mgr.filter(pk__gt=10010).aggregate(Count(‘pk‘))) s = mgr.filter(pk__gt=10010).annotate(Count(‘pk‘)) for x in s: print(x) print(x.__dict__) s = mgr.filter(pk__gt=10010).values(‘gender‘).annotate(Count(‘pk‘)) print(s) for x in s: print(x) # values()方法,放在annotate前就是指定分组字段,之后就是取结果中的字段。 s = mgr.filter(pk__gt=10010).values(‘gender‘).annotate(c=Count(‘pk‘)).order_by(‘-c‘) print(s) for x in s: print(x) s = mgr.filter(pk__gt=10010).values(‘gender‘).annotate(Avg(‘pk‘), c=Count(‘pk‘)).order_by(‘-c‘).values(‘pk__avg‘,‘c‘) print(s) for x in s: print(x)
原文:https://www.cnblogs.com/soymilk2019/p/14782697.html