awk ‘{if($ 0~“listAuths”)print}‘ xxx.log 发现 需要的是将一个文件中的内容与另一个文件中的进行匹配 并输出属于A,同时也属于B文件,则将B文件下该行内容打印出来 方法1: awk ‘NR==FNR{a[$1];next}{if($2 in a)print }‘ file1 file2
awk ‘NR==FNR{a[$1];next}{if(($4 in a)==FALSE)print }‘ file2 file1 #### 排除 file1 文件中(第四列)包含file2文件中(第一列)的部分
方法2: grep –Ff file1 file2 awk ‘NR==FNR{a[$1]}NR>FNR && ($1 in a){print $0}‘ otuid table.txt
测试: [root@dept01 dba_app]# awk ‘NR==FNR{a[$1];next}{if(($2 in a)==FALSE)print }‘ f2 f1 insert a.1; insert a.2; insert a.8; insert a.13; insert a.14;
[root@dept01 dba_app]# awk ‘{print NR"|" FNR}‘ f2 f1 1|1 2|2 3|3 4|4 5|5 6|6 7|7 8|8 9|9 10|1 11|2 12|3 13|4 14|5 15|6 16|7 17|8 18|9 19|10 20|11 21|12 22|13 23|14
[root@dept01 dba_app]# cat f2 f1 a.3; a.4; a.5; a.6; a.7; a.9; a.10; a.11; a.12; insert a.1; insert a.2; insert a.3; insert a.4; insert a.5; insert a.6; insert a.7; insert a.8; insert a.9; insert a.10; insert a.11; insert a.12; insert a.13; insert a.14;
[root@dept01 dba_app]# wc -l f2 f1 9 f2 14 f1 23 total [root@dept01 dba_app]#
awk ‘{if($ 0~“listAuths”)print}‘ xxx.log 发现 需要的是将一个文件中的内容与另一个文件中的进行匹配 并输出属于A,同时也属于B文件,则将B文件下该行内容打印出来 方法1: awk ‘NR==FNR{a[$1];next}{if($2 in a)print }‘ file1 file2
awk ‘NR==FNR{a[$1];next}{if(($4 in a)==FALSE)print }‘ file2 file1 #### 排除 file1 文件中(第四列)包含file2文件中(第一列)的部分
方法2: grep –Ff file1 file2 awk ‘NR==FNR{a[$1]}NR>FNR && ($1 in a){print $0}‘ otuid table.txt
测试: [root@dept01 dba_app]# awk ‘NR==FNR{a[$1];next}{if(($2 in a)==FALSE)print }‘ f2 f1 insert a.1; insert a.2; insert a.8; insert a.13; insert a.14;
[root@dept01 dba_app]# awk ‘{print NR"|" FNR}‘ f2 f1 1|1 2|2 3|3 4|4 5|5 6|6 7|7 8|8 9|9 10|1 11|2 12|3 13|4 14|5 15|6 16|7 17|8 18|9 19|10 20|11 21|12 22|13 23|14
[root@dept01 dba_app]# cat f2 f1 a.3; a.4; a.5; a.6; a.7; a.9; a.10; a.11; a.12; insert a.1; insert a.2; insert a.3; insert a.4; insert a.5; insert a.6; insert a.7; insert a.8; insert a.9; insert a.10; insert a.11; insert a.12; insert a.13; insert a.14;
[root@dept01 dba_app]# wc -l f2 f1 9 f2 14 f1 23 total [root@dept01 dba_app]#
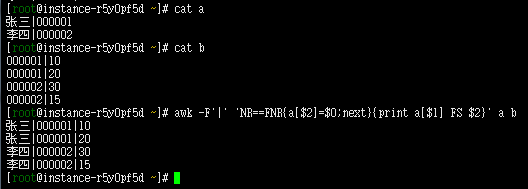
将两个文件具有相同列的行进行合并 复制代码 [root@tyjs09 ~]# cat a 张三|000001 李四|000002 [root@tyjs09 ~]# cat b 000001|10 000001|20 000002|30 000002|15 [root@tyjs09 ~]# awk -F‘|‘ ‘NR==FNR{a[$2]=$0;next}{print a[$1] FS $2}‘ a b 张三|000001|10 张三|000001|20 李四|000002|30 李四|000002|15 复制代码 解释: NR会将2个文件是为一个整体进行行计数,FNR会将每个文件是为一个整体进行技术,例如: NR===>>123,456 FNR===>>123,123 本例中,当NR==FNR是为真,反之为假;为真时运行第一个动作{},不为真时就跳过第一个{},执行第二个{}。 $0表示整行,$1表示第一列,$2表示第二列 代码解说: 当为真时,执行第一个文件a,a的文件内容如下你: 张三|000001 李四|000002 那么a[$2]=$0其实就是定义了一个变量,即:a[000001] = 张三|000001 next表示执行下一行或者下一个周期。 awk -F‘|‘ ‘NR==FNR{a[$2]=$0;next}{print a[$1] FS $2}‘ a b 当NR!=FNR时,说明第一个文件已经执行完了,开始执行第二个文件了,第二个文件的内容如下: 000001|10 000001|20 000002|30 000002|15 那么a[$1]==a[00001] 请看两个红色的区域,将两个文件相同的内容作为每个文件的key值,a[$2], a[$1]其实这两个key都是a[000001] 定义第一个文件的key值等于整行内容 a[$2]=$0 ====>> a[000001] = 张三|000001 然后在执行第二个文件时用这个key进行取值a[$1](因为我们事先定义好的$1就是000001), 最后把文件2中剩下的内容进行拼接 {print a[$1] FS $2} 所以就有了上面的结果!
关于awk的多文件处理: awk的数据输入有两个来源,标准输入和文件,后一种方式支持多个文件,如 1、shell的Pathname Expansion方式:awk ‘{...}‘ *.txt # *.txt先被shell解释,替换成当前目录下的所有*.txt,如当前目录有1.txt和 2.txt,则命令最终为awk ‘{...}‘ 1.txt 2.txt 2、直接指定多个文件: awk ‘{...}‘ a.txt b.txt c.txt ... awk对多文件的处理流程是,依次读取各个文件内容,如上例,先读a.txt,再读b.txt.... 那么,在多文件处理的时候,如何判断awk目前读的是哪个文件,而依次做对应的操作呢? 1、当awk读取的文件只有两个的时候,比较常用的有两种方法 一种是awk ‘NR==FNR{...}NR>FNR{...}‘ file1 file2 或awk ‘NR==FNR{...}NR!=FNR{...}‘ file1 file2 另一种是 awk ‘NR==FNR{...;next}{...}‘ file1 file2 了解了FNR和NR这两个awk内置变量的意义就很容易知道这两种方法是如何运作的 QUOTE: FNR The input record number in the current input file. #已读入当前文件的记录数 NR The total number of input records seen so far. #已读入的总记录数 next Stop processing the current input record. The next input record is read and processing starts over with the first pattern in the AWK program. If the end of the input data is reached, the END block(s), if any, are executed. 对于awk ‘NR==FNR{...}NR>FNR{...}‘ file1 file2 读入file1的时候,已读入file1的记录数FNR一定等于awk已读入的总记录数NR,因为file1是awk读入的首个文件,故读入file1时执行前一个命令块{...} 读入file2的时候,已读入的总记录数NR一定>读入file2的记录数FNR,故读入file2时执行后一个命令块{...} 对于awk ‘NR==FNR{...;next}{...}‘ file1 file2 读入file1时,满足NR==FNR,先执行前一个命令块,但因为其中有next命令,故后一个命令块{...}是不会执行的 读入file2时,不满足NR==FNR,前一个命令块{..}不会执行,只执行后一个命令块{...} 2、当awk处理的文件超过两个时,显然上面那种方法就不适用了。因为读第3个文件或以上时,也满足NR>FNR (NR!=FNR),显然无法区分开来。 所以就要用到更通用的方法了: 1、ARGIND 当前被处理参数标志: awk ‘ARGIND==1{...}ARGIND==2{...}ARGIND==3{...}... ‘ file1 file2 file3 ... 2、ARGV 命令行参数数组: awk ‘FILENAME==ARGV[1]{...}FILENAME==ARGV[2]{...}FILENAME==ARGV[3]{...}...‘ file1 file2 file3 ... 3、把文件名直接加入判断: awk ‘FILENAME=="file1"{...}FILENAME=="file2"{...}FILENAME=="file3"{...}...‘ file1 file2 file3 ... #没有前两种通用 举例: 有两个文件a.txt 和 b.txt a.txt中第一列和第二列数字都有重复,格式如下: 20000401 100000999 20000401 100002999 20000401 100007999 20000401 100013999 20100503 100000999 20100503 400002999 20100503 100007999 20100503 400013999 b.txt中第一列数字唯一,不重复,格式如下: 100000999 123 100002999 456 100007999 137 100013999 253 400002999 394 400013999 672 想要连接两个文件形成c.txt,形成的c.txt格式如下: 20000401 100000999 123 20000401 100002999 456 20000401 100007999 137 20000401 100013999 253 20100503 100000999 123 20100503 400002999 394 20100503 100007999 137 20100503 400013999 672 awk ‘NR==FNR{a[$1]=$2} NR>FNR{print $0,a[$2]}‘ b.txt a.txt awk ‘NR==FNR{a[$1]=$2;next}{print $0,a[$2]}‘ b.txt a.txt 又有如下需求: 我有两个的档案: a.txt (内容很普通,就是正常文本) asaff adfg dgfjh djghalhg b.txt (因为a中有些行是错的,所以修改了,格式为:行号+修改内容) 2:asaffnew 4:hgitsh 想根据 b 档案的行号替换 a.txt 的相关行,请问怎样处理? awk -F: ‘NR==FNR{a[$1]=$2;next}FNR in a{print a[FNR];next}1‘ b.txt a.txt awk -F: ‘NR==FNR{a[$1]=$2;next};FNR in a{$0=a[FNR]}1‘ b.txt a.txt 这个1有打印当前整行的意思。
原文:https://www.cnblogs.com/chendian0/p/14792854.html