1.准备表结构和数据
create table test_middle_data.spe_count_test( name string, sex string, is_valid string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘; insert into test_middle_data.spe_count_test values(‘jack01‘,‘man‘,‘N‘); insert into test_middle_data.spe_count_test values(‘jack02‘,‘woman‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack03‘,‘man‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack04‘,‘woman‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack05‘,‘man‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack06‘,‘woman‘,‘N‘); insert into test_middle_data.spe_count_test values(‘jack07‘,‘man‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack08‘,‘man‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack09‘,‘man‘,‘N‘); insert into test_middle_data.spe_count_test values(‘jack10‘,‘woman‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack11‘,‘man‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack12‘,‘man‘,‘Y‘); insert into test_middle_data.spe_count_test values(‘jack13‘,‘woman‘,‘N‘);
2. 需求是根据sex分组,并统计有效的个数和总个数
我发现有人会这样写
select a.sex,a.is_valid_y,b.total_num FROM( SELECT sex,count(1) is_valid_y FROM test_middle_data.spe_count_test where is_valid = ‘Y‘ group by sex ) a inner join ( SELECT sex, count(1) total_num FROM test_middle_data.spe_count_test group by sex ) b on a.sex = b.sex
结果:
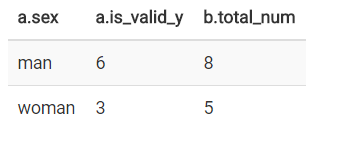
这种两张表做关联查询影响性能,我们可以优化
3. 使用count的特点优化
count(1)或者count(*)都是计算总行数包括字段为NULL,但是count(字段名)是不会统计字段为NULL的数据,我们利用这个特点完成需求
select sex,count(case when is_valid = ‘Y‘ then is_valid else NULL end) is_valid_y, count(1)total_num FROM test_middle_data.spe_count_test group by sex
结果也和第二步的sql一样
原文:https://www.cnblogs.com/yangji0202/p/14794400.html