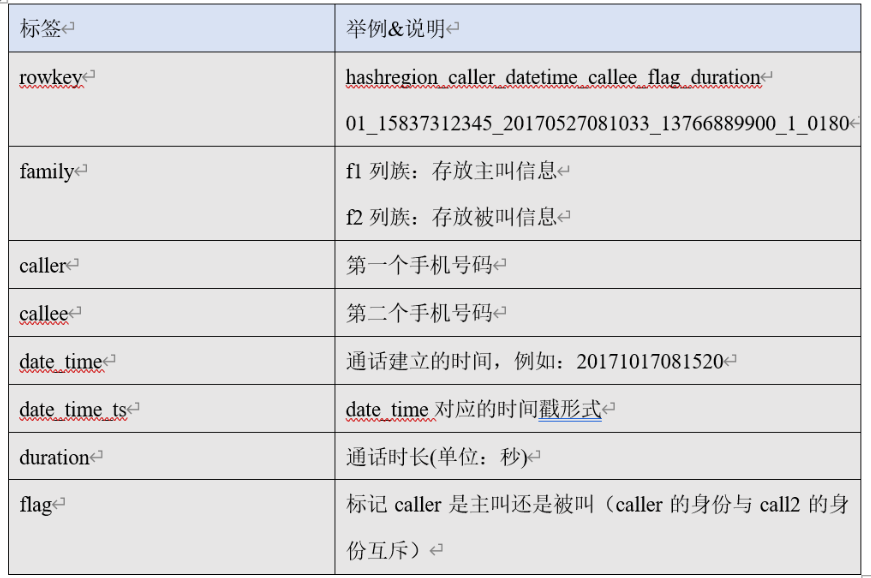
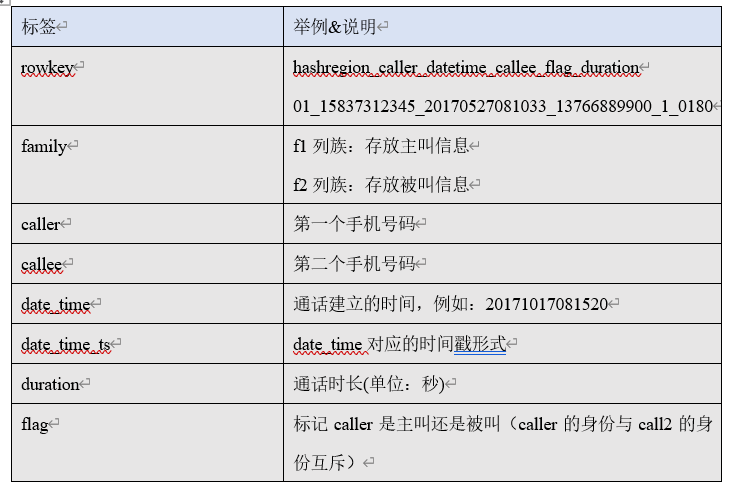
生成通话记录:
//存放tel的list集合
private List<String> phoneList = new ArrayList<>();
//存放tel和Name的Map集合
private Map<String, String> phoneNameMap = new HashMap<>();
随机抽取手机号 配对 成 通话记录,如果重复用 while 满足!= break
随机生成时间
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = sdf1.parse(startTime);
Date endDate = sdf1.parse(endTime);
long randomTS = startDate.getTime() + (long) ((endDate.getTime() - startDate.getTime()) * Math.random());
Date resultDate = new Date(randomTS);
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String resultTimeString = sdf2.format(resultDate);
return resultTimeString;
输出流每次写一条日之后需要flush,不然可能导致积攒多条数据才输出一次。
public void writeLog(String filePath) {
try {
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath,true), "UTF-8");
while (true) {
Thread.sleep(200);
String log = product();
System.out.println(log);
osw.write(log + "\n");
//一定要手动flush才可以确保每条数据都写入到文件一次
osw.flush();
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e2) {
e2.printStackTrace();
}
}
java -cp /root/work/xin_project/jars/ct_producer-1.0-SNAPSHOT.jar producer.ProductLog /root/work/xin_project/jars/calllog.csv
这个命令太麻烦了,便写成了sh脚本
cat product.sh
#!bin/bash
java -cp /root/work/xin_project/jars/ct_producer-1.0-SNAPSHOT.jar producer.ProductLog /root/work/xin_project/jars/calllog.csv
http://192.168.182.179:50070
单个bigdata179上启动
/root/sof/hadoop-2.7.3/sbin/start-all.sh
/root/sof/hadoop-2.7.3/sbin/stop-all.sh
全部 bigdata179 180 181
/root/sof/zookeeper-3.4.10/bin/zkServer.sh start
/root/sof/zookeeper-3.4.10/bin/zkServer.sh stop
单个 bigdata179
/root/sof/hbase-1.3.0/bin/start-hbase.sh
/root/sof/hbase-1.3.0/bin/stop-hbase.sh
每个单个 对应关闭的时候是 每个都要做:
/root/sof/hbase-1.3.0/bin/hbase-daemon.sh stop master
/root/sof/hbase-1.3.0/bin/hbase-daemon.sh stop regionserver
单个
/root/sof/hbase-1.3.0/bin/hbase shell
全部
Kafka的 启动命令 (&表示后台启动):
/root/sof/kafka_2.11-2.1.1/bin/kafka-server-start.sh /root/sof/kafka_2.11-2.1.1/config/server.properties &
全部
Kafka的 关闭命令:
/root/sof/kafka_2.11-2.1.1/bin/kafka-server-stop.sh /root/sof/kafka_2.11-2.1.1/config/server.properties &
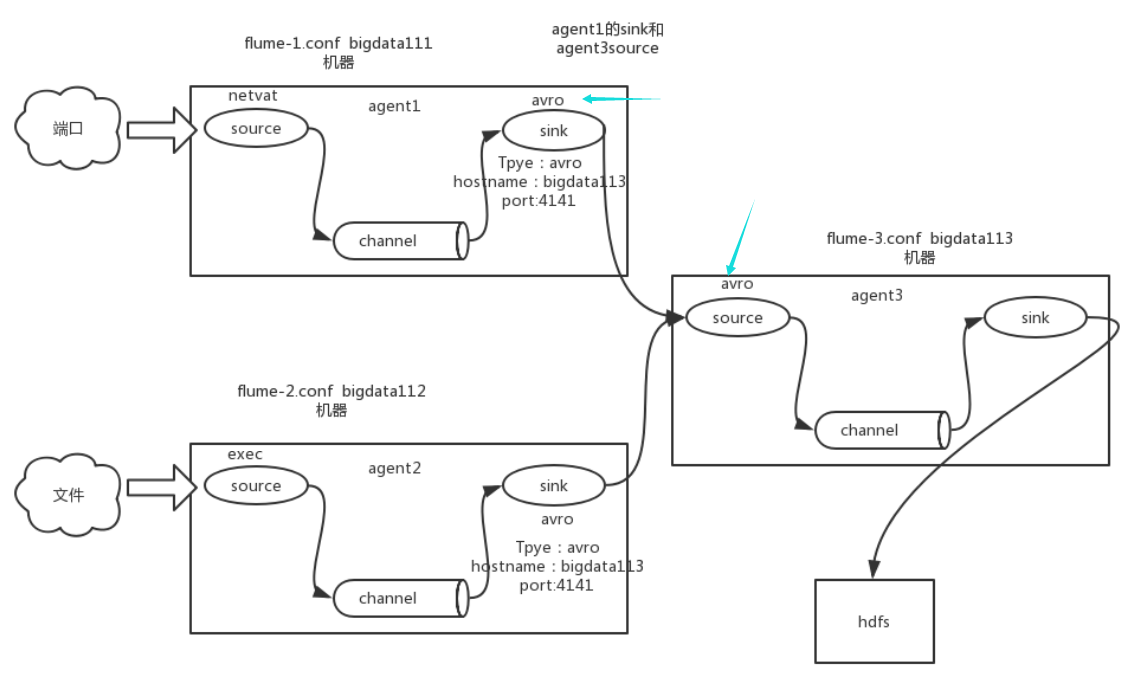
flume和kafka进行实时数据收集。
source channel sink event
流程:
1)source监控有没有新的数据 ,(某个文件或数据流,数据源产生新的数据)
2)拿到该数据后,将数据封装在一个Event中,
3)并put到channel后commit提交,channel队列先进先出,
4)sink去channel队列中拉取数据,
5)然后写入到HDFS中。
监控端口source:type -->netcat 日志打印sink:type-->logger
监控文件(通过shell命令)source:type -->exec hdfs sink:type-->hdfs
监控目录source:type -->spooldir hdfs sink:type-->hdfs
扇入(fan in):数据汇总,多层
channel : type-->两种:内存、磁盘 (内存会有数据丢失的问题)
bin/flume-ng agent --conf conf/ --name a3 --conf-file myconf/flume33.conf
bin/flume-ng agent -c conf -n a3 -f myconf/flume33.conf
扇出(fan out):数据作用于多个地方
source 1个 replicating
channel 多个
sink 多个
配置文件 dataStream是序列化文件, batchSize sink每次的量
agent.sources.kafkaSource.type=org.apache.flume.source.kafka.KafkaSource
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#type的参数不能写成uuid,得写具体,否则找不到类
a1.sources.r1.interceptors.i1.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /root/work/XIN_project/jars/calllog.csv
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = bigdata179:9092,bigdata180:9092,bigdata181:9092
a1.sinks.k1.topic = calllog
a1.sinks.k1.batchSize = 20
a1.sinks.k1.requiredAcks = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动命令:
/root/sof/flume/bin/flume-ng agent --conf /root/sof/flume/conf/ --name a1 --conf-file /root/sof/flume/jobconf/flume2kafka.conf
之后开始生产
$ sh productlog.sh

需要有配置文件说明 kafka的topic kafka的brokerlist:bigdata179:9092
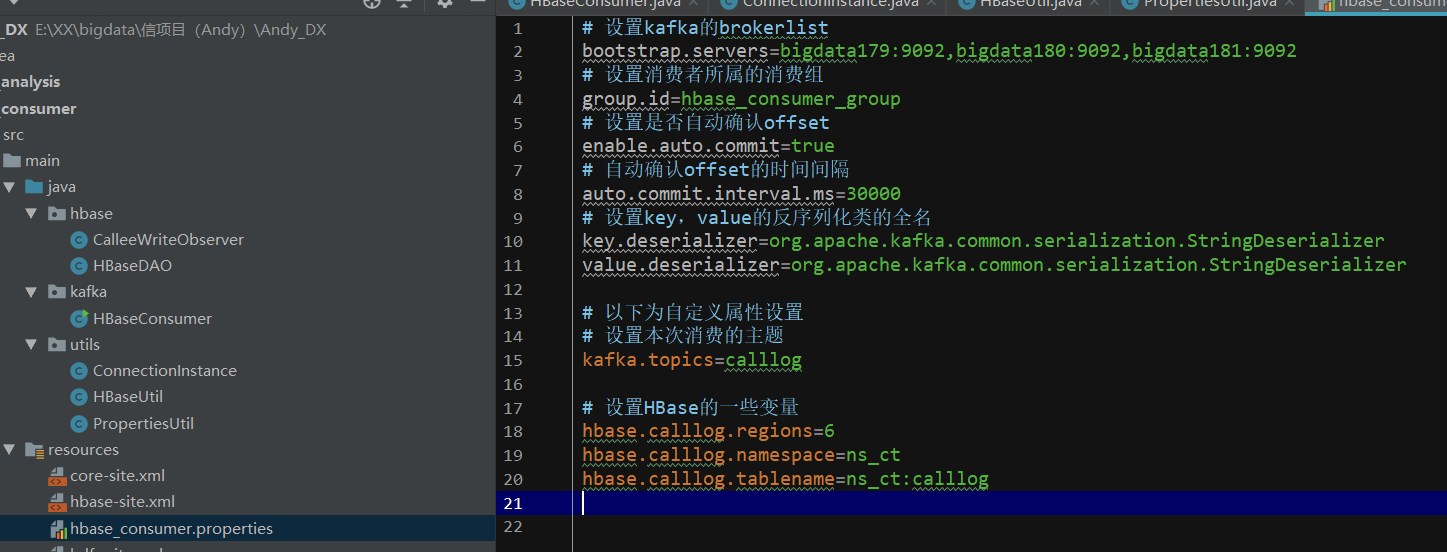

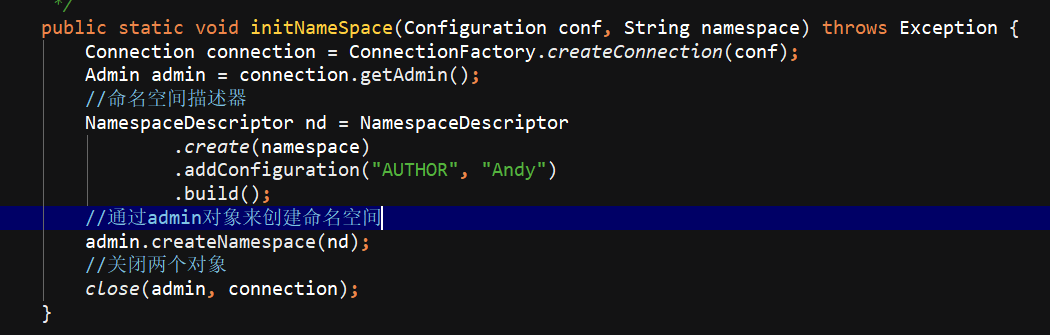
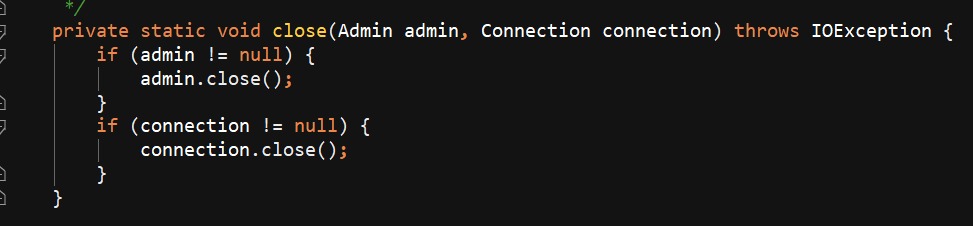
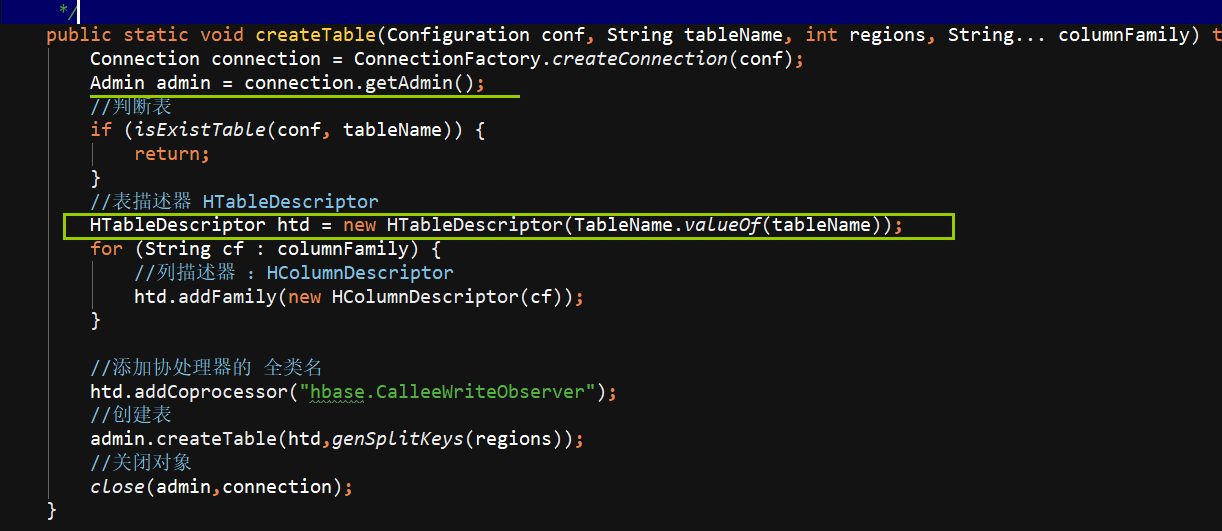
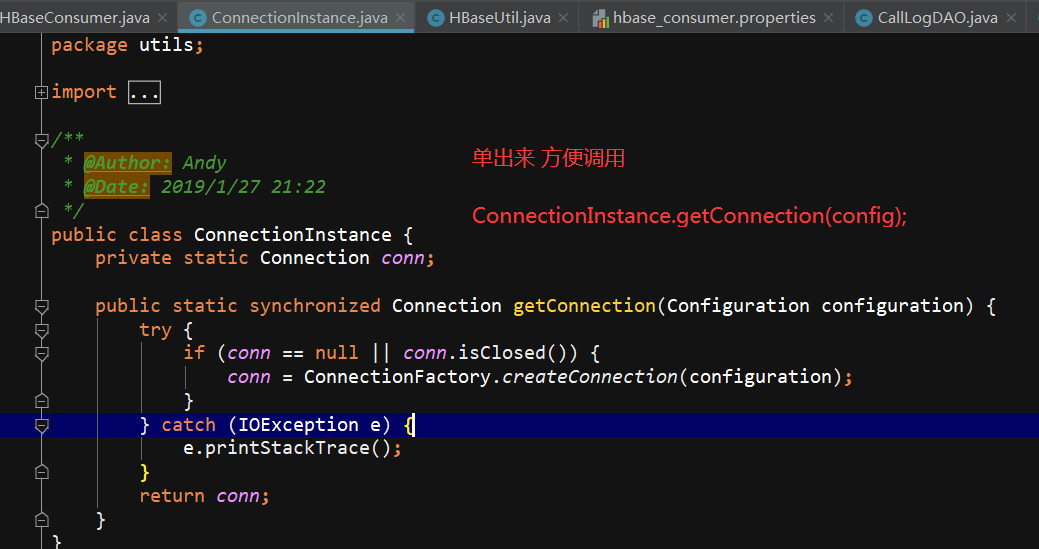
写一个HBaseUtil 里面有 是否存在表 // 初始化命名空间 // 创建表 // 表是否存在

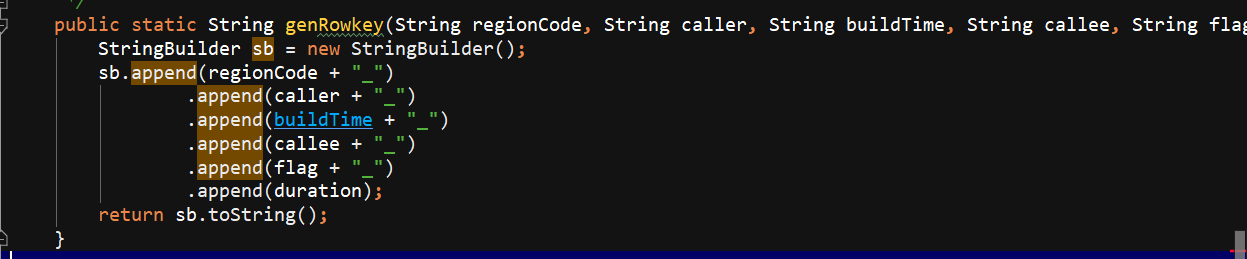
生成rowKey,直接进行的拼接 分区号在前+主叫+建立时间+被叫+flag+通话时长
生成分区号:手机号的后4位 ^异或 通话年月201802 ---> 之后x.hashcode(); ---> 之后%regions Decimal格式化
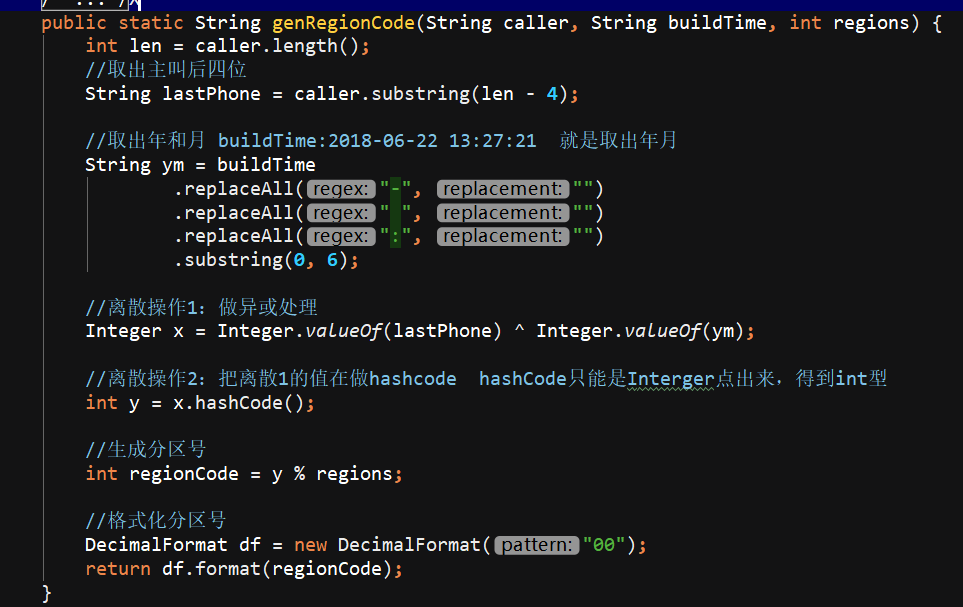
自定义分区
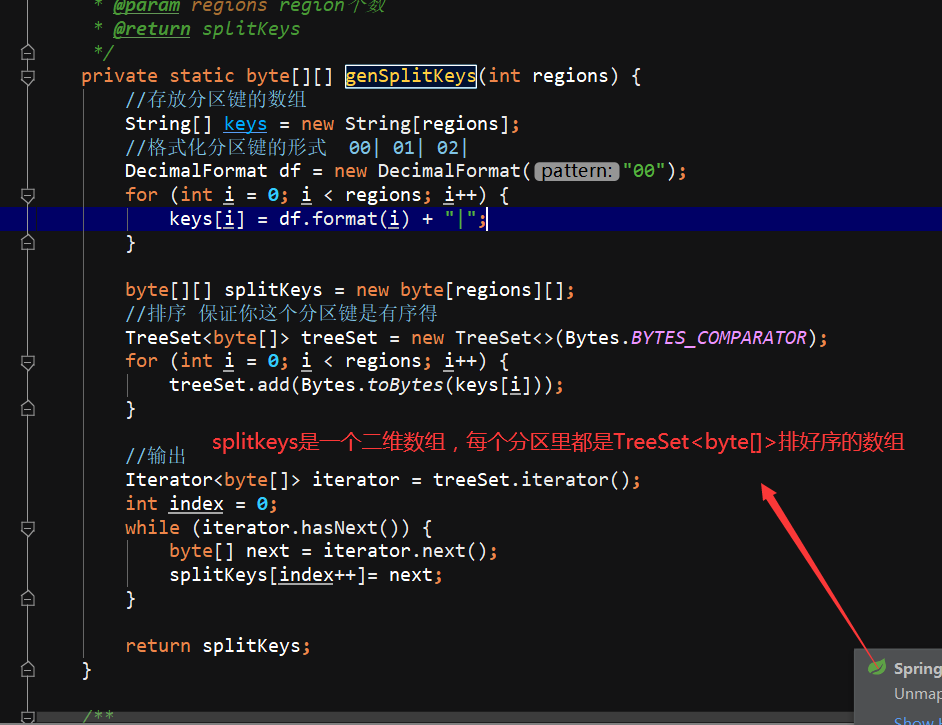
ConnectionInstance设计模式,单出来
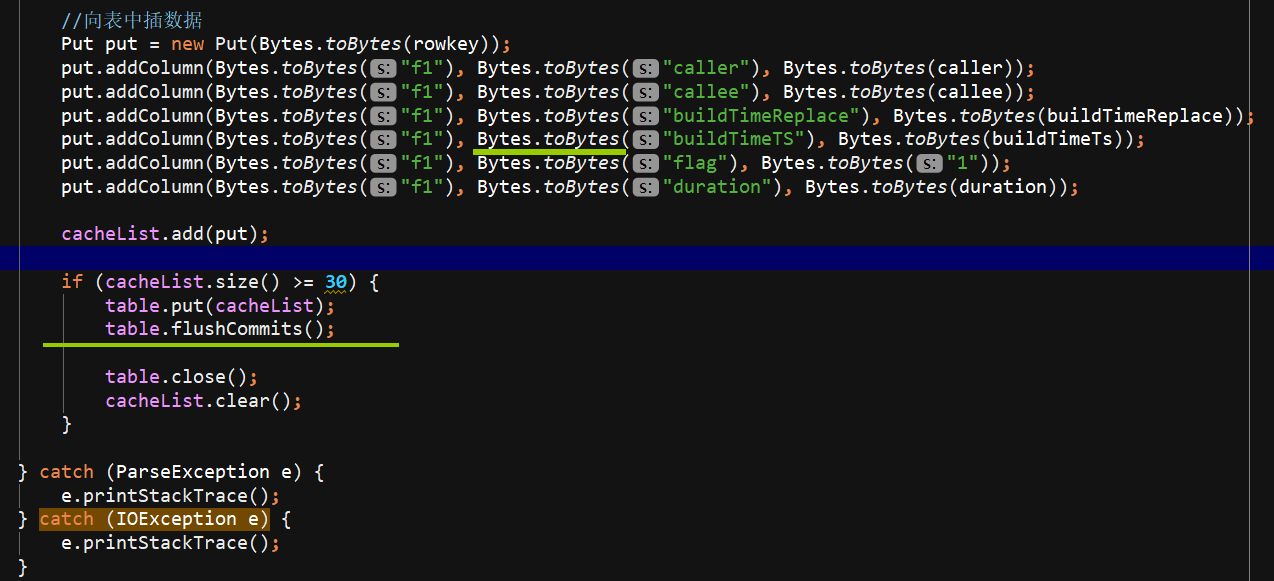
HBaseDAO 就是一个关键的 PUT 方法,把数据传进去
先把数据进行切分,因为csv用的是逗号,,要计算分区号,计算rowkey,,设计batchsize 凑齐30个进行flush

在协处理器中,一条主叫日志成功插入后,将该日志切换为被叫视角再次插入一次,放入到与主叫日志不同的列族中。
修改hbase-site.xml文件,设置协处理器,并群发该hbase-site.xml文件
协处理器放在的是 hbase-site.xml文件 都是传到集群上的所有机器。
插入的数据是 从rowkey里面拿到的 String oriRowKey = Bytes.toString(put.getRow());
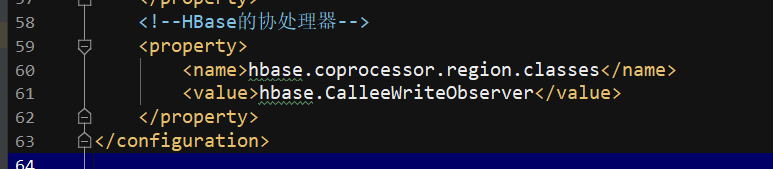
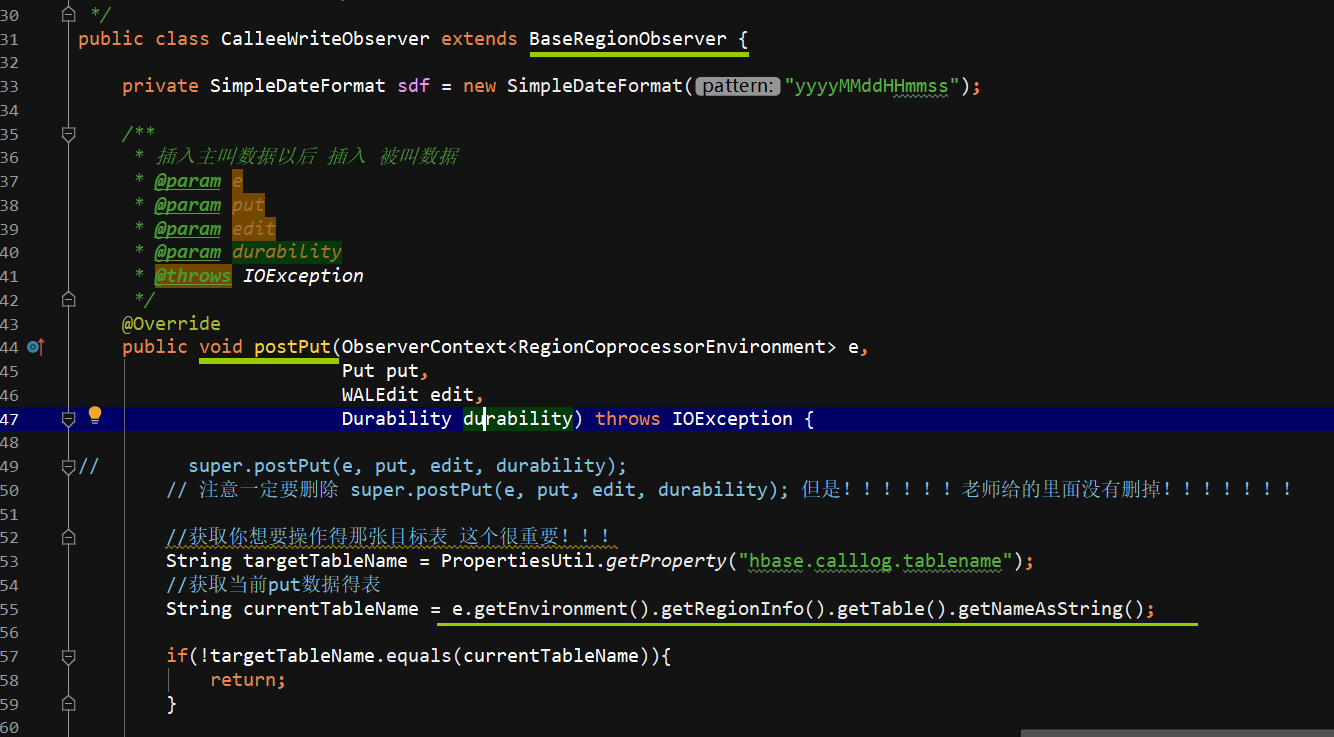
发布jar包到hbase的lib目录下(注意需群发):
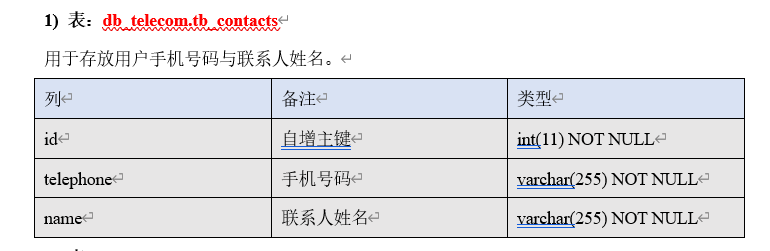
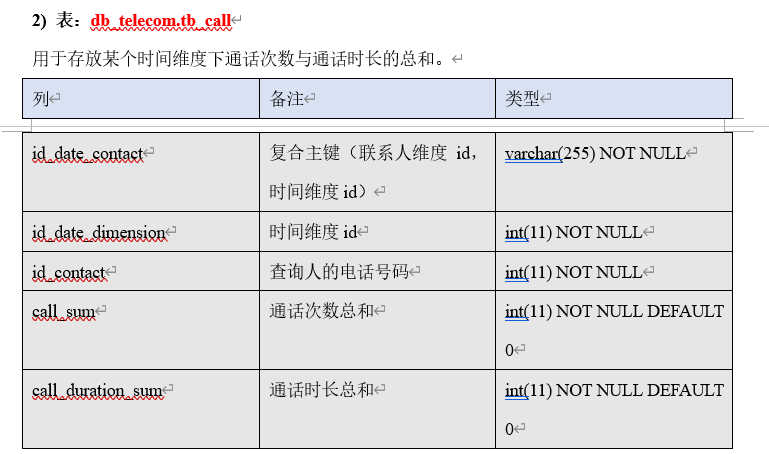
原文:https://www.cnblogs.com/ming-michelle/p/14797215.html