为什么要用集合?
数组用于对多个同类型数据的存储,是 Java容器。(这里的存储是内存中的存储,不涉及持久化的存储)
数据存储的特点:初始化后即确定长度。方法有限、效率不高、实际元素个数无法直接获取,arr.length 获取的是数组的总长度,即初始化的那个确定的长度。
回答:因为已有的 Java容器——数组不能满足各种需求,所以有了集合。
Java的集合分为两大类:实现了 Collecion 接口的和实现了 Map 接口的。
注意二者的区别:Collection 是单列集合,存储一个个的对象,Map 则是双列集合,存储键值对。
实现了 Collection 类的结构图如下:
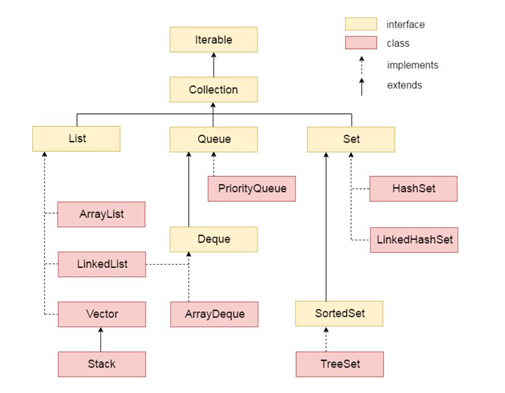
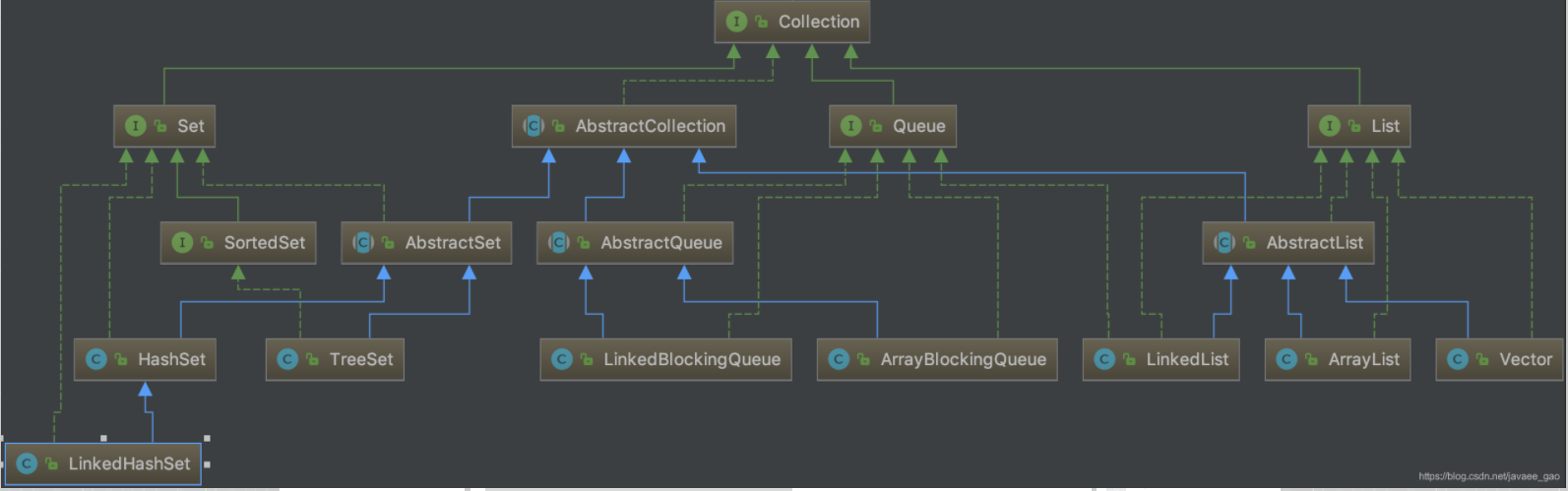
Collection 接口的常用方法:
增:
List<String> lst1 = new ArrayList<>(); List<String> lst2 = new ArrayList<>(); String s1 = new String("haha"); String s2 = new String("haha"); lst1.add(s1); lst2.add(s2); System.out.println(lst1.equals(lst2));
输出:true。
public void test2(){ ArrayList<Person> l1 = new ArrayList<>(); ArrayList<Person> l2 = new ArrayList<>(); Person p1 = new Person("xiaoyueliang", 12); Person p2 = new Person("xiaoyueliang", 12); l1.add(p1); l2.add(p2); System.out.println(l1.equals(l2)); }
输出:false。
我好像对 equals 方法有点疑惑,还有 String 的存储方式?
数组与集合的转换
//集合 --->数组:toArray() Object[] arr = coll.toArray(); for(int i = 0;i < arr.length;i++){ System.out.println(arr[i]); } //拓展:数组 --->集合:调用Arrays类的静态方法asList(T ... t) List<String> list = Arrays.asList(new String[]{"AA", "BB", "CC"}); System.out.println(list);
对于 数组 --> 集合,需要注意以下的情况:
// 情况 1
List arr1 = Arrays.asList(new int[]{123, 456}); System.out.println(arr1.size());//1
// 情况 2
List arr2 = Arrays.asList(new Integer[]{123, 456}); System.out.println(arr2.size());//2
情况 1 是把整个数组当成一个元素放进了集合里,情况 2 则是把数组里的元素一个一个地放进去。
使用实现了 Collection接口的集合存储某些类,该类需要重写 equals 方法。
为什么?
因为 Collection 里面有的方法需要比较。
??这是什么意思?
??:其实就是上面那个 Person 的例子一样,明明存进去的是同一个东西(内容上),但是 equals 方法返回的是 false,现实使用中,我们其实更在乎内容,而不是“地址值”。所以需要重写一下 Person 的equals 方法,对比的是内容,而不是 Object 默认的 equals 方法对比的“地址值”(Java中这个东西叫啥啊?)
重写一下 Person 中的 equals 方法:
@Override public boolean equals(Object obj) { if(this == obj){ return true; } if(obj == null){ return false; } if(getClass() != obj.getClass()){ return false; } Person p = (Person) obj; return this.name.equals(p.name) && this.id == p.id; }
这样,test2()的输出就是 true 了。
PS:??重写 equlas 方法我总是忘了怎么写,觉得很害怕写 equlas 方法。在《Java 核心技术卷 I》中文版的 P117 里面有一个写 equals 的完美建议:
对于 public boolean equals(Object obj),其实我们只要记住,目标是:比较具体内容。
1. 显示参数的命名是 obj;
2. 先比较引用是否相同:
if(this == obj) return true;
3. 空值判断
if(obj == null) return false;
4. 类型比较(??:这里的类型,子类的话怎么样呢)【其实这里用 instanceof 更好】
if(this.getClass != obj.getClass) return fasle;
5. 经过了 4 ,能到这步的都是类型相同的,所以先类型转换一下:
ClassName other = (ClassName) obj;
6. ClassName 中的域比较
准则就是,基本类型用 ==,应用类型用 Object.equals。(实际上没有这个静态方法,这里的意思是用上父类的重写 equals 方法)
return field1 == other.field1 && Object.equals(field2, other.field2);
看一下 String 中的equals 方法。
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false;
String 的类型比较是 子类欸,那《Java 核心技术卷I》给的是getClass,这样好像不是很好,用 instanceof 更好。
对比一下 getClass 和 instanceof
Person p1 = new Person("xioayueliang", 12); Student s1 = new Student("xinxin", 24, 9); System.out.println(p1.getClass()); // class pers.xyl.java.Person
System.out.println(s1.getClass()); // class pers.xyl.java.Student
instanceof
boolean result = obj instanceof Class
其中 obj 为一个对象,Class 表示一个类或者一个接口,当 obj 为 Class 的对象,或者是其直接或间接子类,或者是其接口的实现类,结果result 都返回 true,否则返回false。
Object 的 equals
public boolean equals(Object obj) { return (this == obj); }
可以看到,就是比较引用值。
其实这可以从“为什么我们需要 equals?”角度来想。
因为我们现实生活中,更多的是需要比较“实际内容”,至于在计算机里面的存储,我们并不关心。但是原本的比较方法 “==”,只有在对基本变量类型的时候才是“比较内容”,在面对引用类型的时候是“比较地址”。这不是我们想要的。所以我们都会重写 equals 方法。而String 类已经重写好了。
Iterator 接口 和 foreach 循环
遍历 Collection 的两种方法:迭代器 Iterator ;foreach 循环
Iterator 对象称为 迭代器。而 Collection 中的 iterator 方法就是返回一个 迭代器实例。
// 对集合 coll 调用 iterator() 方法,获得一个迭代器。
Iterator iterator = coll.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); }
Iterator 类:
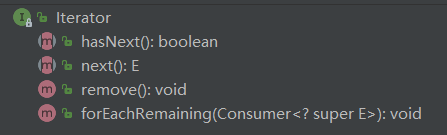
要注意 Iterator 类的 remove() 和 Collection 的 remove()。
Iterator 类的 remove() 要搭配 next() 使用。
《Java 核心技术卷I》里面说到,next() 其实更像是指在了两个元素之间,我们只要越过了要删除的那个元素,即使用了 next()之后,才可以 remove()。很显然嘛,毕竟我们总要看一下里面是什么才进行删除。
foreach 循环
//for(集合元素的类型 局部变量 : 集合对象) for(Object obj : coll){ System.out.println(obj); }
说明:内部仍然使用了迭代器。【??,这是咋知道的,这种情况看不了源码啊?】
一个注意点:这种遍历的方法,那个“集合元素类型”,即使使用泛型定义了具体的集合类型,这里好像也只能写“Object"。??【好吧,这个”好像“是错误的,之前的模糊印象,谁让我当时不搞清楚!】
例子如下:
public void test2(){ ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); for(int i:list){ System.out.println(i); } }
使用了泛型,就可以在 foreach 里面用实际的 集合元素类型。
Collection 子接口—— List 接口
常用方法
常用实现类:
List接口:存储序的、可重复的数据。 --> “动态”数组,替换原的数组
ArrayList:作为 List 接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData存储
LinkedList:对于频繁的插入、删除操作,使用此类效率比ArrayList高;底层使用双向链表存储
Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] elementData
ArrayList 源码分析:
jdk 7
ArrayList list = new ArrayList();//底层创建了长度是10的Object[]数组elementData list.add(123);//elementData[0] = new Integer(123); ... list.add(11);//如果此次的添加导致底层elementData数组容量不够,则扩容。
结论:建议开发中使用带参的构造器:ArrayList list = new ArrayList(int capacity)
jdk 8
ArrayList list = new ArrayList();//底层Object[] elementData初始化为{}.并没创建长度为10的数组 list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到elementData[0] ...
jdk7中的ArrayList的对象的创建类似于单例的饿汉式,
而jdk8中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
LinkedList 源码分析
// 内部声明了Node类型的first和last属性,默认值为null,即底层是双向链表 LinkedList list = new LinkedList();
list.add(123);//将123封装到Node中,创建了Node对象。
private static class Node<E> { // 其中,Node定义为:体现了LinkedList的双向链表的说法 E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
Vector 源码分析
与 List 接口的区别。【??:一个东西存在,要问为什么存在?】
【计算两个东西:1 哈希值,2 索引。??:不同的哈希值经过某种算法也可能得出相同的结论】x 不同,有可能 y 同,但是 y 不同,那么 x 肯定不同。这是数学上函数的基本要求。这里的 x 可以指元素,y 则是 哈希值。元素是横坐标,哈希值是纵坐标,因为是 f(元素)= 哈希值。
如果此位置上没其他元素,则元素 a 添加成功。 ---> 情况1 ?
如果此位置上其他元素 b (或以链表形式存在的多个元素,则比较元素a与元素b的hash值: ?
如果hash值不相同,则元素 a 添加成功。---> 情况2 ?
如果hash值相同,进而需要调用元素 a 所在类的equals()方法: 【??:哈希值相同代表了什么?因为 hashCode() 可以重写,所以还是不能保证内容相同,所以要进行 equals 比较】?
equals()返回true,元素a添加失败 ?
equals()返回false,则元素a添加成功。---> 情况3
对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
jdk 7 :元素a放到数组中,指向原来的元素。
jdk 8 :原来的元素在数组中,指向元素a。
HashSet底层:数组+链表的结构。(前提:jdk7)【??what the hell?jdk8咋样的呢?】
Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历 在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。对于频繁的遍历操作,LinkedHashSet效率高于HashSet.
TreeSet
存储对象所在类的要求:
HashSet/LinkedHashSet:
要求:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals() ( “相等的对象必须具有相等的散列码”。)
要求:重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
TreeSet: 1.自然排序中,比较两个对象是否相同的标准为:compareTo()返回0,不再是equals(). 2.定制排序中,比较两个对象是否相同的标准为:compare()返回0,不再是equals().
源码分析:
源码还是要多看看。。。总结了一个早上都没写完……累了。
【要看一下 hashcode 和 equals】
原文:https://www.cnblogs.com/isxyl/p/14800671.html