默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。对调试非常有帮助。
| 平台 | 阿里云服务器(1核2G) |
|---|---|
| 系统 | CentOS7.3 |
| 远程工具 | FinalShell |
| 安装包 | hadoop-3.2.0.tar.gz,jdk-8u241-linux-x64.tar.gz |
| 存放路径 | /usr/local/share/applications/ |
| 环境变量 | hadoop:/usr/local/share/applications/hadoop;jdk:/usr/local/share/applications/jdk |
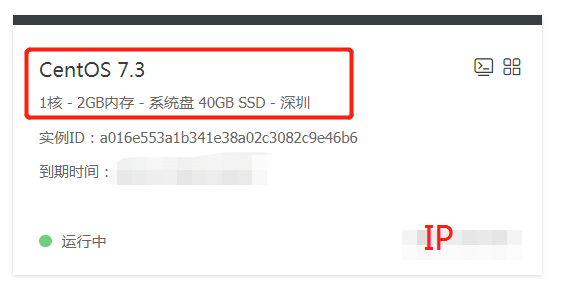

这里使用FinalShell

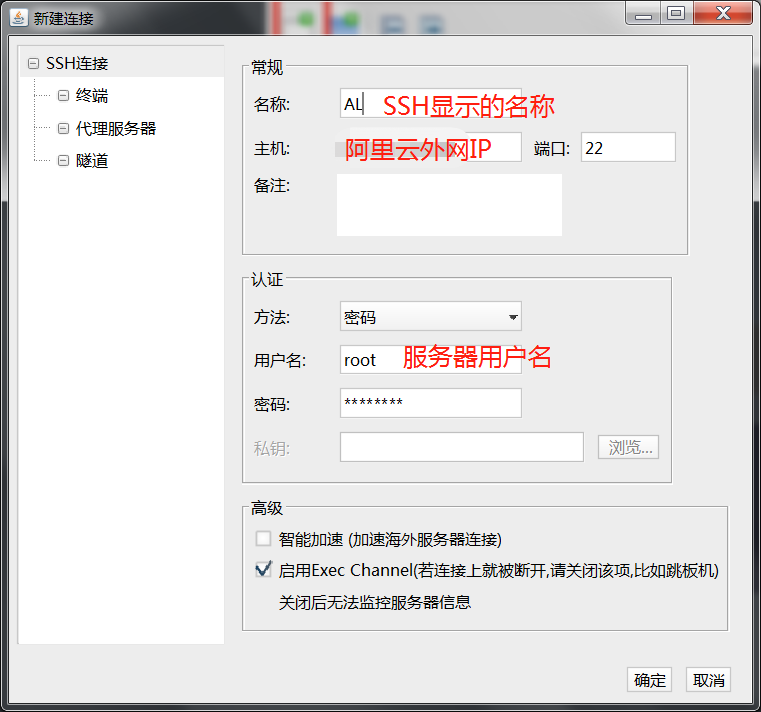
选择->SSH连接
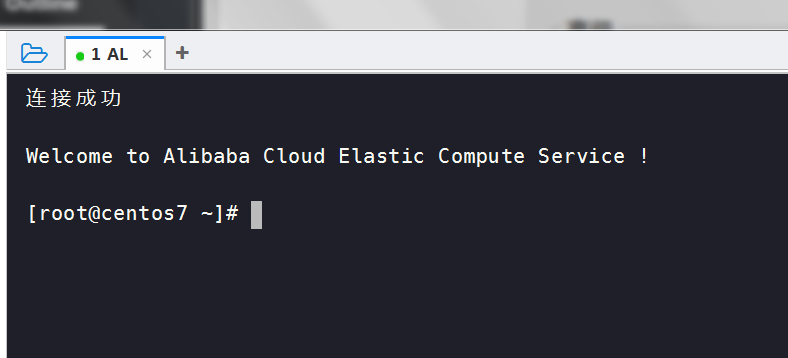
[root@izwz9gkqceq3fljxybvvt2z ~]# vim /etc/hostname

修改主机的IP映射
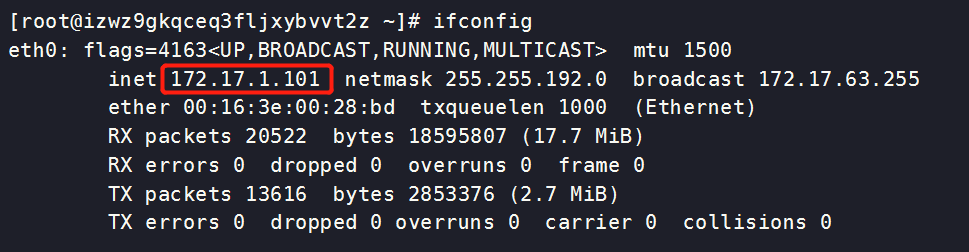
[root@izwz9gkqceq3fljxybvvt2z ~]# ifconfig
[root@izwz9gkqceq3fljxybvvt2z ~]# vim /etc/hosts

配置完成后,重启服务器
[root@izwz9gkqceq3fljxybvvt2z ~]# reboot
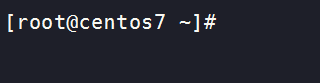
将搭建环境所用的HADOOP和JDK安装包放到/usr/local/share/applications目录下
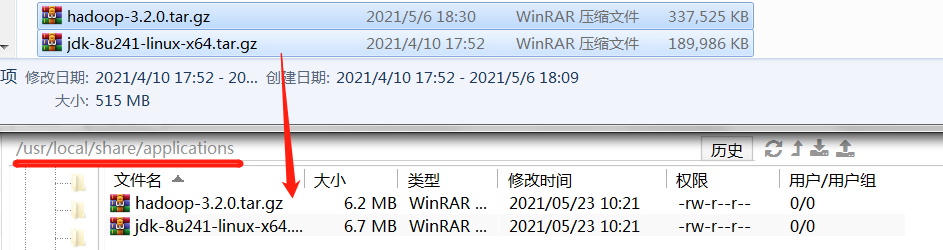
[root@centos7 applications]# ll
总用量 432912
-rw-r--r-- 1 root root 248747707 5月 23 10:22 hadoop-3.2.0.tar.gz
-rw-r--r-- 1 root root 194545143 5月 23 10:22 jdk-8u241-linux-x64.tar.gz
解压
[root@centos7 applications]# tar -xvf hadoop-3.2.0.tar.gz
[root@centos7 applications]# tar -xvf jdk-8u241-linux-x64.tar.gz
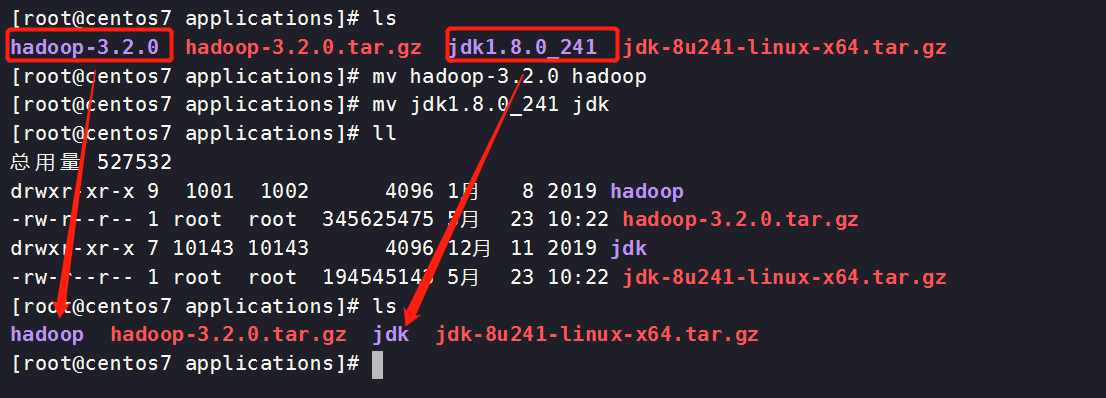
压缩包改名
[root@centos7 applications]# mv hadoop-3.2.0 hadoop
[root@centos7 applications]# mv jdk1.8.0_241 jdk
[root@centos7 hadoop]# vim /etc/profile
JAVA环境变量
export JAVA_HOME=/usr/local/share/applications/jdk #存放JDK文件夹的路径
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=$JAVA_HOME/bin:$PATH
HADOOP环境变量
export HADOOP_HOME=/usr/local/share/applications/hadoop #存放HADOOP文件夹的路径
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

使设置生效
[root@centos7 hadoop]# source /etc/profile
检验JDK是否安装成功 (失败的话检查路径)
[root@centos7 hadoop]# java -version

检验HADOOP是否安装成功
[root@centos7 hadoop]# hadoop version

[root@centos7 hadoop]# yum install -y openssh-server openssh-client
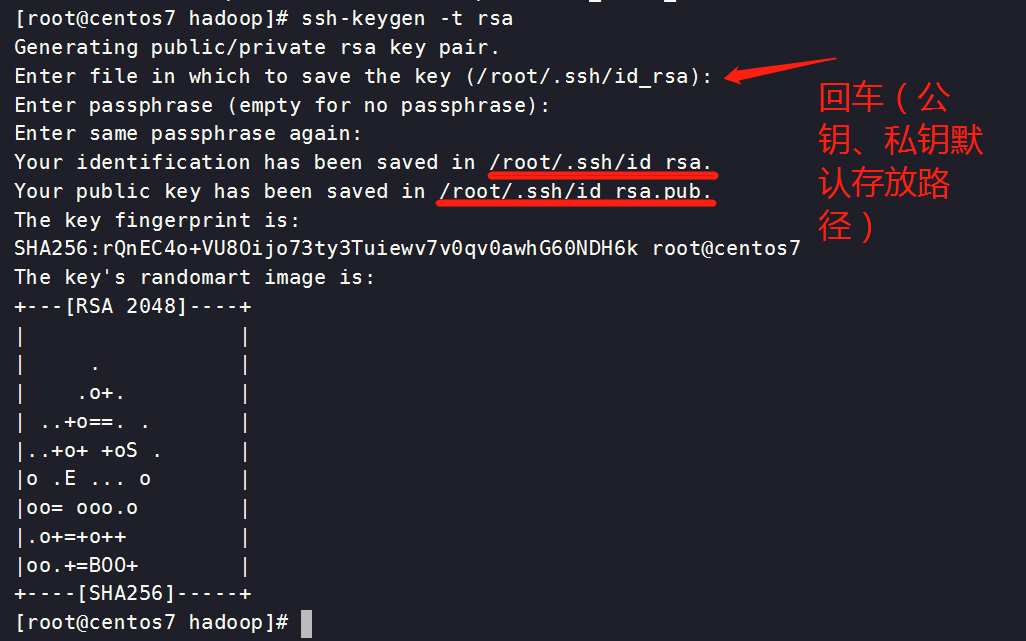
[root@centos7 hadoop]# ssh-keygen -t rsa

因为是单机安装,这里免密是本机登录本机
##切换目录
[root@centos7 .ssh]# cd /root/.ssh/
[root@centos7 .ssh]# pwd
/root/.ssh
##复制公钥
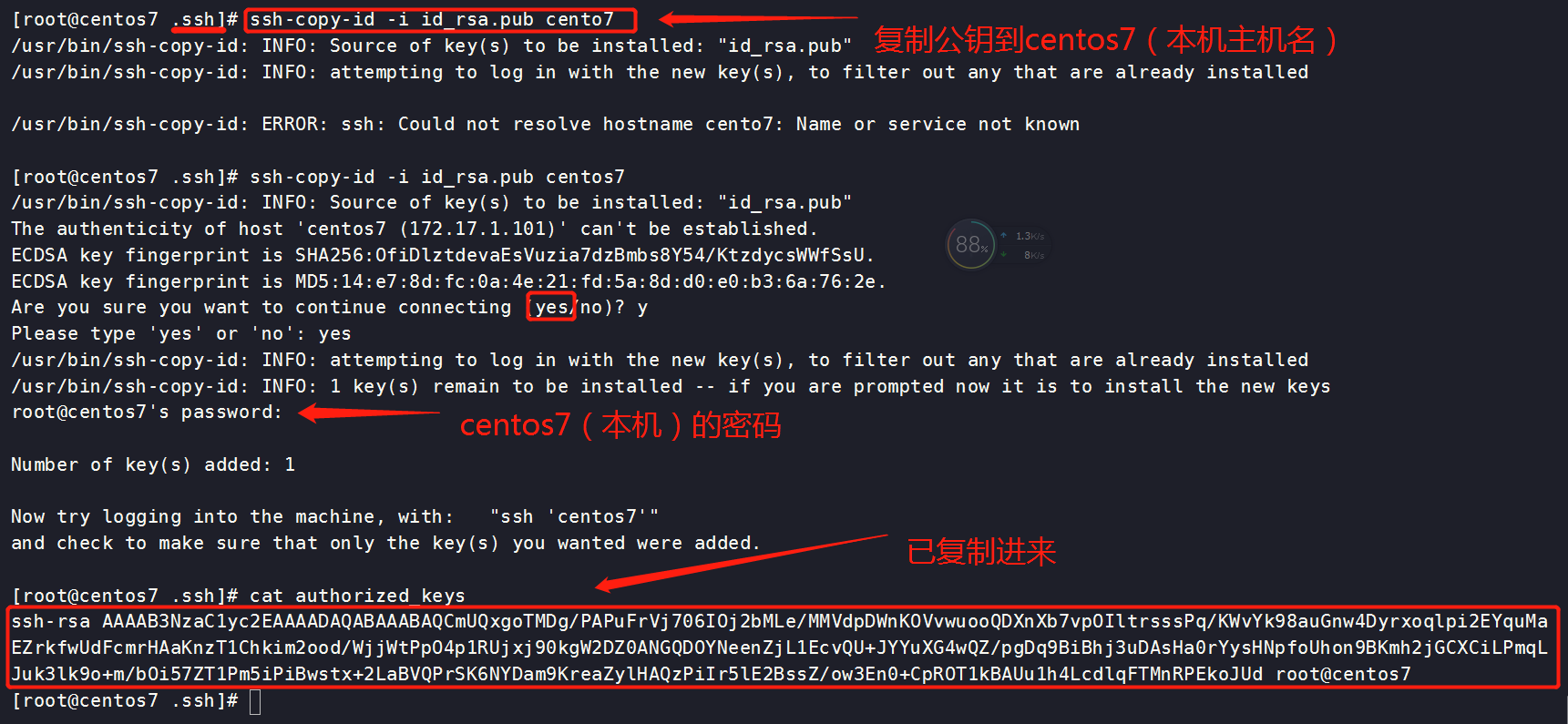
[root@centos7 .ssh]# ssh-copy-id -i id_rsa.pub cento7
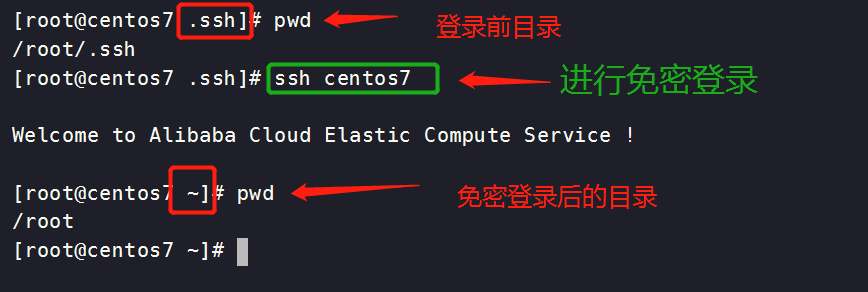
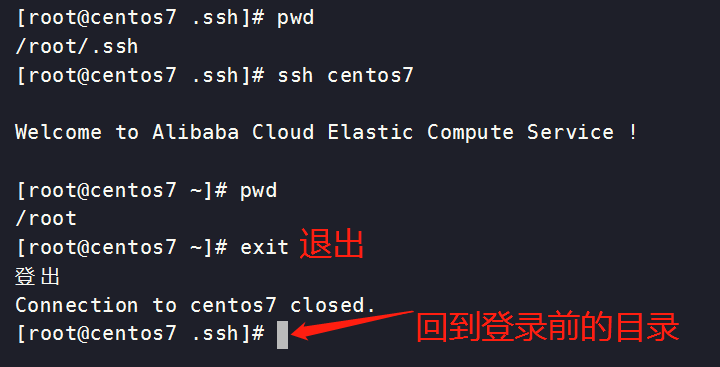
尝试免密登录是否成功(注意登录前后的目录变化)
[root@centos7 .ssh]# pwd
/root/.ssh
[root@centos7 .ssh]# ssh centos7
Welcome to Alibaba Cloud Elastic Compute Service !
[root@centos7 ~]# pwd
/root
[root@centos7 ~]# exit #退出
Connection to centos7 closed.
[root@centos7 .ssh]#
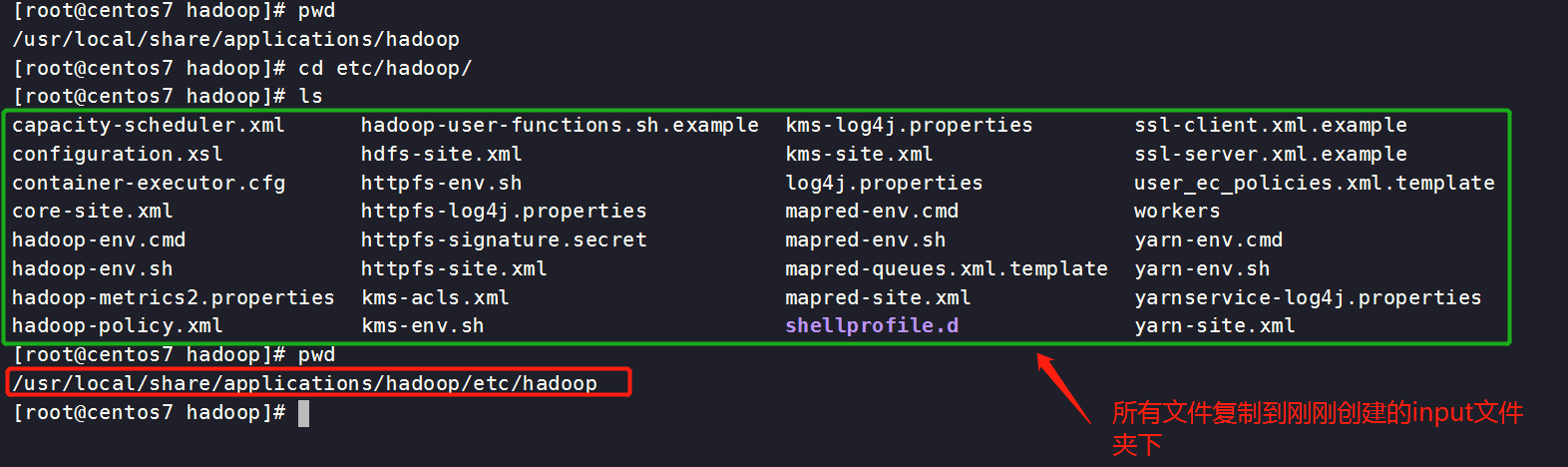
/usr/local/share/applications/hadoop下创建input文件夹

##/usr/local/share/applications/hadoop/etc/hadoop
[root@centos7 hadoop]# cd /usr/local/share/applications/hadoop/etc/hadoop
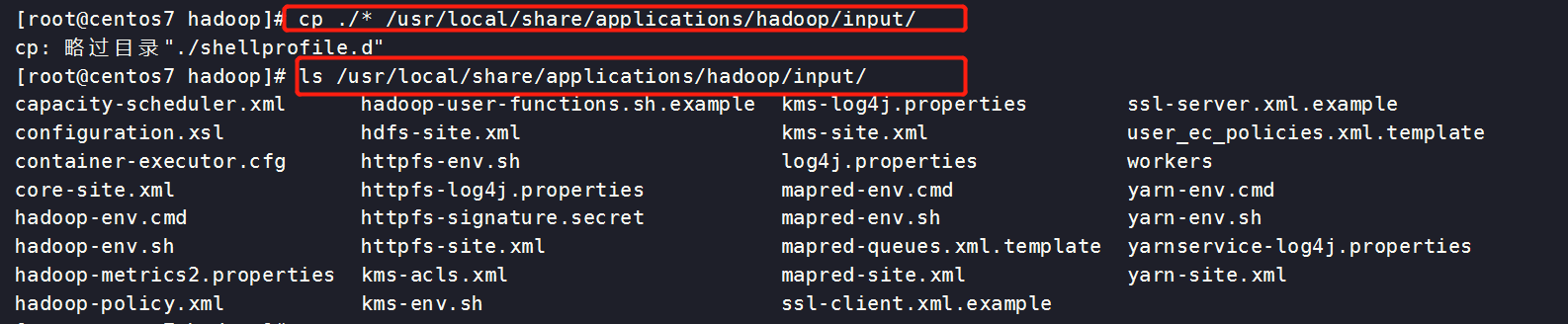
[root@centos7 hadoop]# cp ./* /usr/local/share/applications/hadoop/input/
[root@centos7 hadoop]# ls /usr/local/share/applications/hadoop/input/
运行wordcount程序,并将结果保存在output中。我没找到自带的 hadoop example jar包,所以自己下载了一个。
hadoop example jar下载地址:http://www.java2s.com/Code/Jar/h/Downloadhadoopexamples120jar.htm
将下载的jar包放到/usr/local/share/applications/hadoop目录下
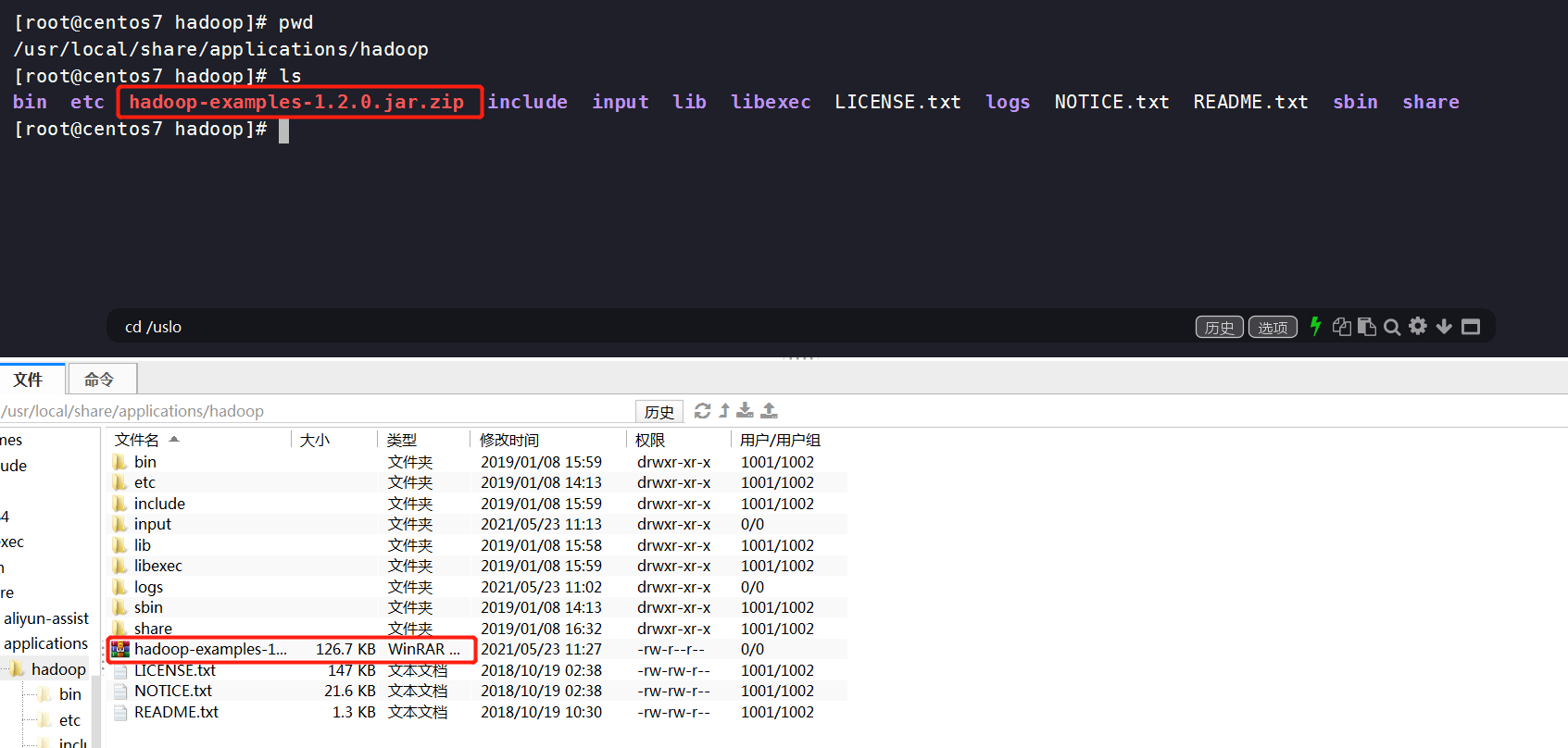
解压jar包
[root@centos7 hadoop]# unzip hadoop-examples-1.2.0.jar.zip

若是出现未找到命令
[root@centos7 hadoop]# unzip --help
-bash: unzip: 未找到命令
则用yum install 下载
[root@centos7 hadoop]# yum install -y unzip
查看hadoop-examples-1.2.0.jar文件权限
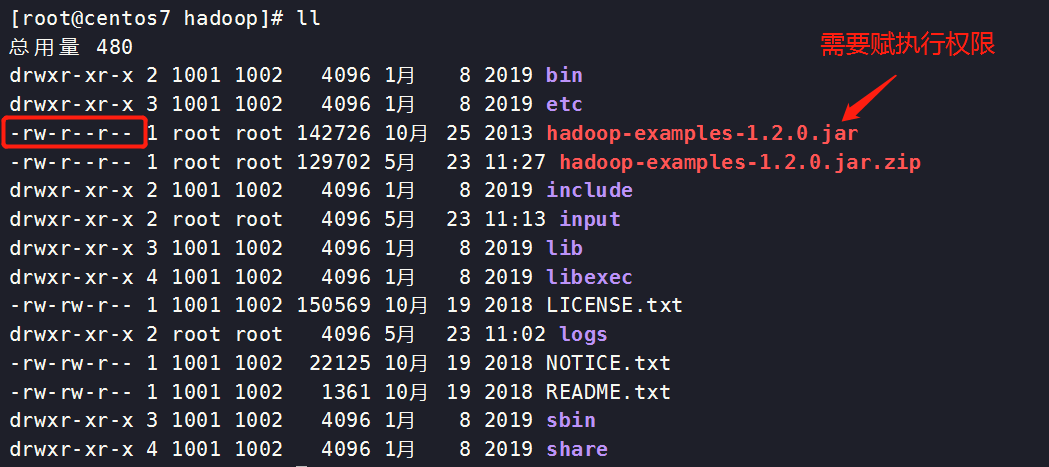
[root@centos7 hadoop]# chmod a+x hadoop-examples-1.2.0.jar
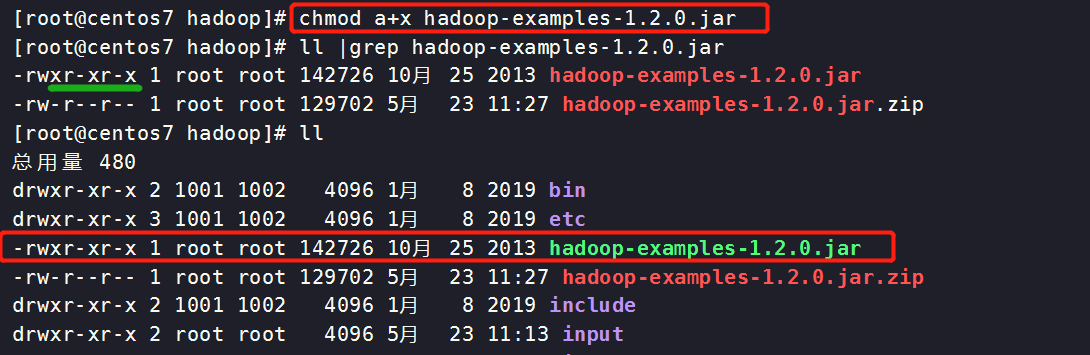
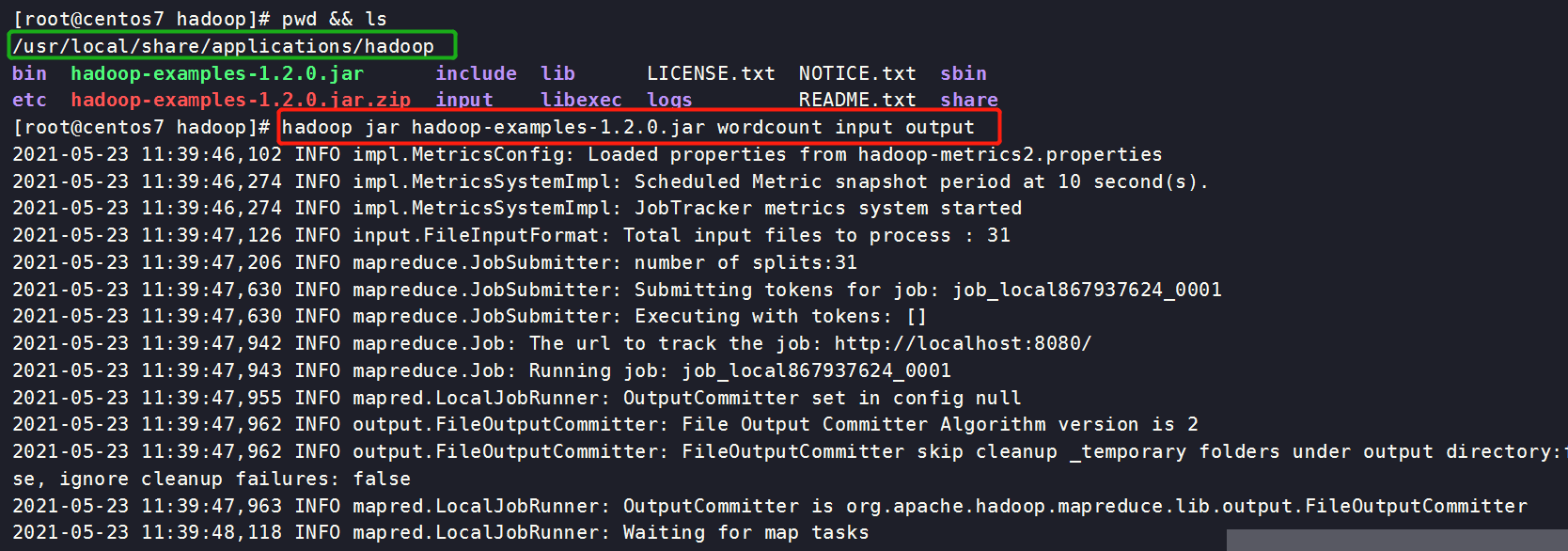
运行
[root@centos7 hadoop]# hadoop jar hadoop-examples-1.2.0.jar wordcount input output

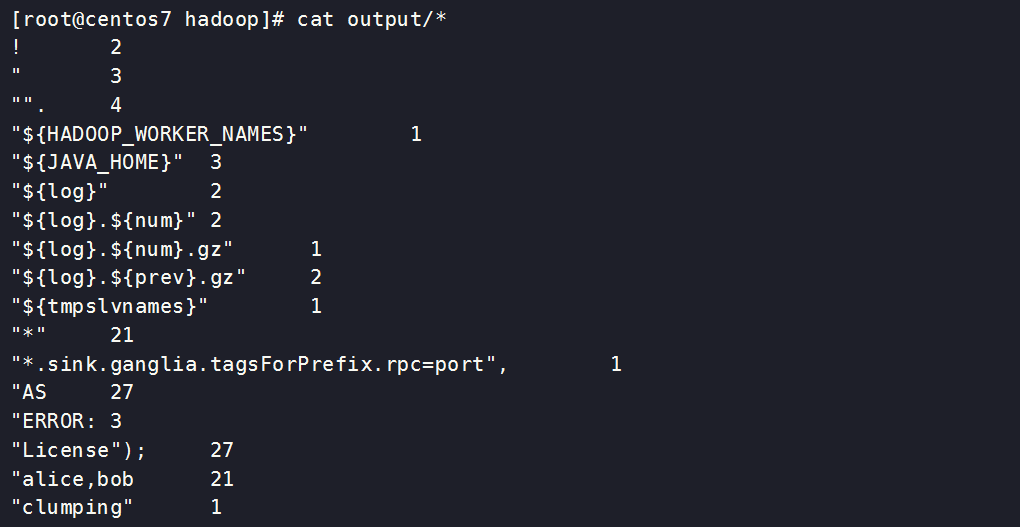
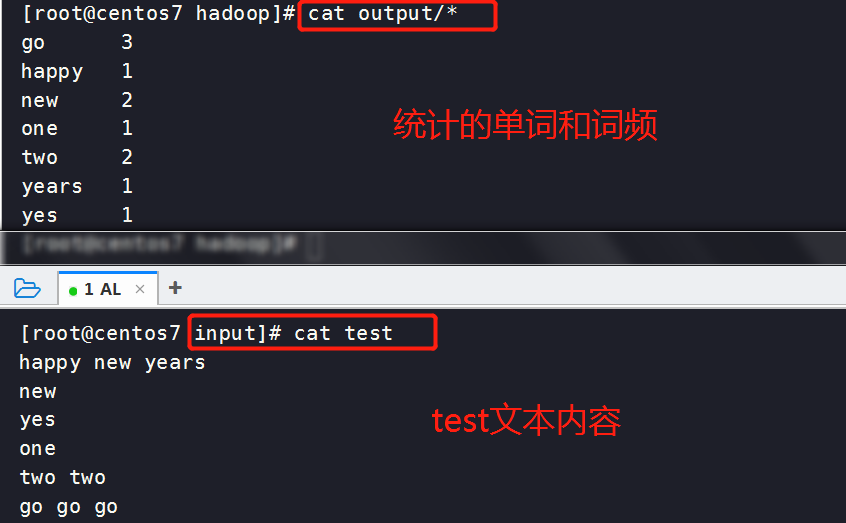
查看统计的单词和出现的频数
[root@centos7 hadoop]# cat output/*
先删除刚刚input下所有文件,删除output文件夹
也可以不删除output文件夹,后面进行测试的时候可以创建另一个名字的文件存放也是可以的
[root@centos7 hadoop]# pwd
/usr/local/share/applications/hadoop #当前所在目录
[root@centos7 hadoop]# rm -rfv input/* #删除input下所有文件
[root@centos7 hadoop]# ls input/
[root@centos7 hadoop]# rm -rf output/
创建一个文本,自己写一些单词
[root@centos7 hadoop]# cd input/ #切换到input目录下
[root@centos7 input]# pwd
/usr/local/share/applications/hadoop/input #当前绝对路径
[root@centos7 input]# ls #当前目录确保被清空
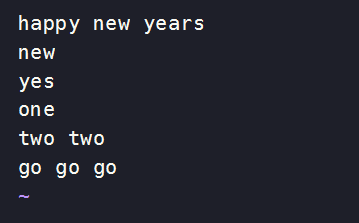
[root@centos7 input]# vim test #自己创建一个单词文本
happy new years
new
yes
one
two two
go go go
运行格式:hadoop jar <hadoop-examplesXXX.jar所在路径> wordcount <要处理文件夹的存放路径> <输出结果的存放路径>
[root@centos7 input]# hadoop jar ../hadoop-examples-1.2.0.jar wordcount ../input ../output
如果cat output/*发现还是之前的数据的话,查看刚刚运行Wordcount的信息,出现如下情况表示输出文件夹有重名。
解决方法
一、删除原有的输出文件夹
二、修改hadoop jar命令重新命名一个文件夹名字(系统会自动生成,不用事先创建)

之后重新运行hadoop jar命令即可
原文:https://www.cnblogs.com/kyokyo-w/p/14801012.html