Hadoop是分布式系统基础架构,通常指Hadoop生态圈
主要解决
1.海量数据的存储
2.海量数据的分析计算
优势
版本区别
资源调度:内存、CPU分配等
解耦+模块化
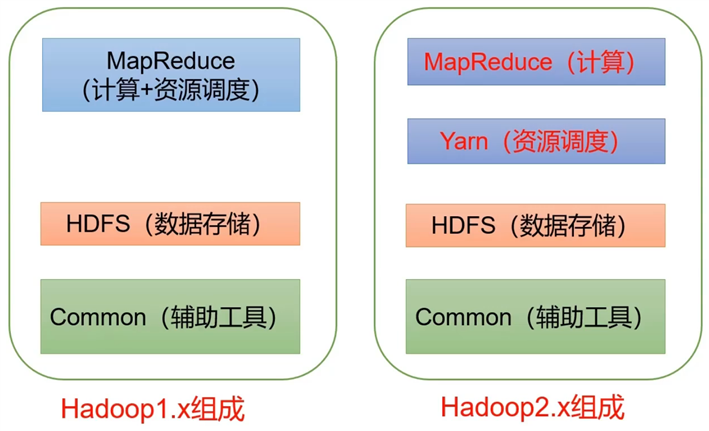
Hadoop3.x在组成上没有变化
Hadoop Distributed File System(HDFS)分布式文件系统
NameNode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的DataNode(数据都存储在什么位置)等
DataNode(dn):在本地文件系统存储文件块数据(具体存储数据),以及块数据的校验和
Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份,可以恢复NameNode的一部分工作
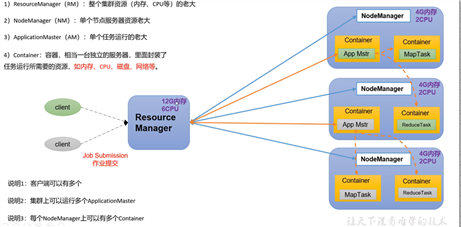
MapReduce将计算过程分为两个阶段:Map和Reduce
1.Map阶段并行处理输入数据 –> 负责大任务分小任务
2.Reduce阶段对Map结果进行汇总 –> 负责汇总结果
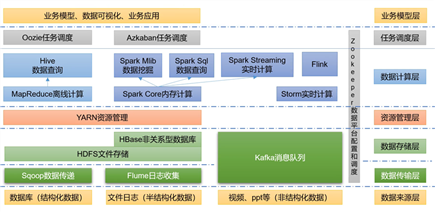
图示补充:
1.数据计算层中MapReduce与Spark Core是离线,离线的主要处理日统计、月统计等。
2.Flink框架在数据计算层
3.内存计算数据快,断电数据缺失
4.Hive与Spark Sql主要都是通过写sql实现分析计算的过程
5.Storm(慢慢过时)实时计算,数据来了就算;SparkStreaming(常用)实时计算是准实时,按批处理数据。
案列
比如jd首页
买书行为被记录下来 --> Nginx ---> Tomcat收集访问日志 --> Flume日志收集 --> kafka消息队列进行缓冲 --> 实时计算
原文:https://www.cnblogs.com/rananie/p/14801529.html