进程是具有一定独立功能的程序,关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。从逻辑角度来看,多线程的意义在于一个应用程序(进程)中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用来实现,而是作为进程来调度和管理以及资源分配。这就是进程和线程的重要区别,进程和线程的主要差别在于,进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。下面我们来说一说并发连接数。
最大并发连接数是服务器同一时间能处理最大会话数量。
我们打开一个网站就是一个客户端浏览器与服务端的一个会话,而我们浏览网页是基于http协议。
HTTP支持两种建立连接的方式:非持久连接和持久连接(HTTP1.1默认的连接方式为持久连接)。
1.建立TCP连接 2.Web浏览器向Web服务器发送请求命令 3.Web浏览器发送请求头信息 4.Web服务器应答 5.Web服务器发送应答头信息 6.Web服务器向浏览器发送数据 7.Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,但是浏览器一般其头信息加入了这行代码 Connection:keep-alive,TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接目的,节省了为每 个请求建立新连接所需的时间,还节约了网络带宽。
用户下载服务器上的文件,则为一个连接,用户文件下载完毕后这个连接就消失了。有时候用户用迅雷的多线程方式下载的话,这一个用户开启了5个线程的话,就算是5个连接。
用户打开你的页面,就算停留在页面没有对服务器发出任何请求,那么在用户打开一面以后的15分钟内也都要算一个在线。
上面的情况用户继续打开同一个网站的其他页面,那么在线人数按照用户最后一次点击(发出请求)以后的15分钟计算,在这个15分钟内不管用户怎么点击(包括新窗口打开)都还是一人在线。
当用户打开页面然后正常关闭浏览器,用户的在线人数也会马上清除。
Web服务器由于要同时为多个客户提供服务,就必须使用某种方式来支持这种多任务的服务方式。一般情况下可以有以下三种方式来选择,多进程方式、多线程方式及异步方式。其中,多进程方式中服务器对一个客户要使用一个进程来提供服务,由于在操作系统中,生成一个进程需要进程内存复制等额外的开销,这样在客户较多时的性能就会降低。为了克服这种生成进程的额外开销,可以使用多线程方式或异步方式。在多线程方式中,使用进程中的多个线程提供服务, 由于线程的开销较小,性能就会提高。事实上,不需要任何额外开销的方式还是异步方式,它使用非阻塞的方式与每个客户通信,服务器使用一个进程进行轮询就行了。
虽然异步方式最为高效,但它也有自己的缺点。因为异步方式下,多个任务之间的调度是由服务器程序自身来完成的,而且一旦一个地方出现问题则整个服务器就会出现问题。因此,向这种服务器增加功能,一方面要遵从该服务器自身特定的任务调度方式,另一方面要确保代码中没有错误存在,这就限制了服务器的功能,使得异步方式的Web服务器的效率最高,但功能简单,如Nginx服务器。
由于多线程方式使用线程进行任务调度,这样服务器的开发由于遵从标准,从而变得简单并有利于多人协作。然而多个线程位于同一个进程内,可以访问同样的内存空间,因此存在线程之间的影响,并且申请的内存必须确保申请和释放。对于服务器系统来讲,由于它要数天、数月甚至数年连续不停的运转,一点点错误就会逐渐积累而最终导致影响服务器的正常运转,因此很难编写一个高稳定性的多线程服务器程序。但是,不是不能做到时。Apache的worker模块就能很好的支持多线程的方式。
多进程方式的优势就在于稳定性,因为一个进程退出的时候,操作系统会回收其占用的资源,从而使它不会留下任何垃圾。即便程序中出现错误,由于进程是相互隔离的,那么这个错误不会积累起来,而是随着这个进程的退出而得到清除。Apache的prefork模块就是支持多进程的模块。
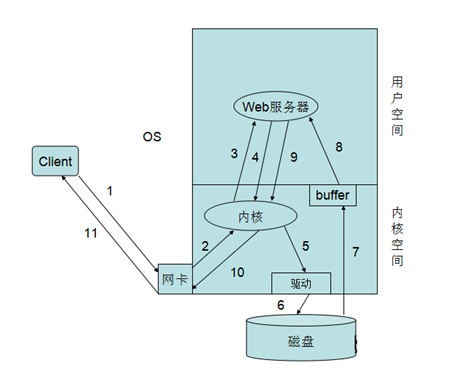
在上面的讲解中我们说明,Web服务器的如何提供服务的,有多进程的方式、多线程的方式还有异步方式我们先简单这么理解,后面我们慢慢说,现在我们不管Web服务器是如何提供服务的,多进程也好、多线程好,异步也罢。下面我们来说一下,一个客户端的具体请求Web服务的具体过程,从上图中我们可以看到有11步,下面我们来具体说一下,
1.首先我们客户端发送一个请求到Web服务器,请求首先是到网卡。2.网卡将请求交由内核空间的内核处理,其实就是拆包了,发现请求的是80端口。3.内核便将请求发给了在用户空间的Web服务器,Web服务器接受到请求发现客户端请求的index.html页面。4.Web服务器便进行系统调用将请求发给内核。5.内核发现在请求的是一页面,便调用磁盘的驱动程序,连接磁盘。6.内核通过驱动调用磁盘取得的页面文件。7.内核将取得的页面文件保存在自己的缓存区域中便通知Web进程或线程来取相应的页面文件。8.Web服务器通过系统调用将内核缓存中的页面文件复制到进程缓存区域中。9.Web服务器取得页面文件来响应用户,再次通过系统调用将页面文件发给内核。10.内核进程页面文件的封装并通过网卡发送出去。11.当报文到达网卡时通过网络响应给客户端
简单来说就是:用户请求-->送达到用户空间-->系统调用-->内核空间-->内核到磁盘上读取网页资源->返回到用户空间->响应给用户。上述简单的说明了一下,客户端向Web服务请求过程,在这个过程中,有两个I/O过程,一个就是客户端请求的网络I/O,另一个就是Web服务器请求页面的磁盘I/O。 下面我们就来说说Linux的I/O模型。
原文:https://www.cnblogs.com/lichouluoyu/p/14806137.html