转自:https://blog.csdn.net/DLUTBruceZhang/article/details/9050467
https://www.cnblogs.com/yc3110/p/10440613.html
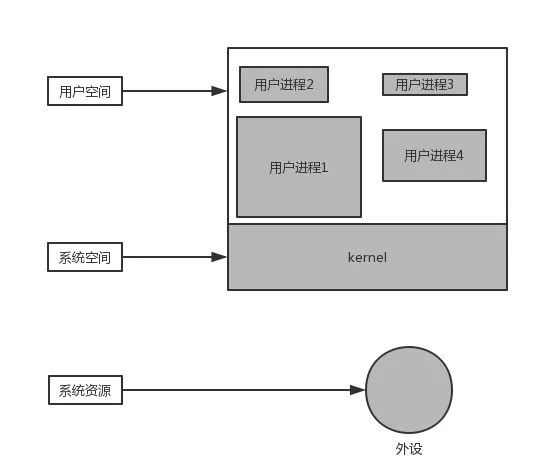
在用户空间中的进程要通过系统调用才能访问系统资源。系统资源包括:

上面所说的这些系统资源,在用户进程中是无法被直接访问的,只能通过操作系统来访问,所以也把操作系统提供的这些功能成为:“系统调用”。
首先,用户进程通过系统调用访问系统资源的时候,需要切换到内核态,而这对应一些特殊的堆栈和内存环境,必须在系统调用前建立好。而在系统调用结束后,cpu会从核心模式切回到用户模式,而堆栈又必须恢复成用户进程的上下文。而这种切换就会有大量的耗时。
一些程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。(用较小的次数填满buffer)。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。【缓冲区就可以理解为内存数组,在当前进程中开辟一段虚拟内存空间,并且映射到物理内存中,实际上存储在物理内存中】
用户缓冲区的目的是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。除了在进程中设计缓冲区,内核也有自己的缓冲区。
read是把数据从内核缓冲区复制到进程缓冲区。write是把进程缓冲区复制到内核缓冲区。当然,write并不一定导致内核的写动作(不等价于写入磁盘),比如os可能会把内核缓冲区的数据积累到一定量后,再一次写入。这也就是为什么断电有时会导致数据丢失。所以说内核缓冲区,是为了在OS级别,提高磁盘IO效率,优化磁盘写操作。
【个人认为,read和write都是系统调用函数,因为要访问内核缓冲区或者写入内核缓冲区,需要进入到内核态。但是因为有buffer的存在,如果这里有数据,就从这里读,而不产生系统调用,节约时间。】

对比阻塞和非阻塞:
应用内核缓冲区的主要思想就是一次读入大量的数据放在缓冲区,需要的时候从缓冲区取得数据:
用户进程是运行在用户空间的,不能直接操作内核缓冲区的数据。 用户进程进行系统调用的时候,会由用户态切换到内核态,待内核处理完之后再返回用户态。
原文:https://www.cnblogs.com/BlueBlueSea/p/14807245.html