先对整体做一个理解,根据规格给出的属性规划数据结构以及容器选择;然后对于addPerson、getAge这类可以“望文生义”的方法,先写一下自己的理解,然后再去和规格核对,主要关注异常的处理。对于一些比较复杂的方法,比如sendIndirectMessage,就只能慢慢分析规格,按照规约逻辑完成代码实现。有一些方法比如getAgeVar,规格给出的实现通常是循环这类效率比较低的算法,会根据实际情况进行算法的优化。
这个单元的难度确实比前两个单元的难度降了不少,但是需要考虑的细节更多了,我这种马大哈就栽了不少..所以测试很重要啊害
关于测试,第一次第二次的时候尝试了Junit,但是只对部分方法进行了测试,导致起的作用并不大,我现在觉得使用Junit测试可以换一个角度思考问题,从数据构造的角度去尝试覆盖每一种方法可能会遇到的不同的情况,而这个单元很适合Junit的学习,因为规格中已经把方法中的后置条件给出来了。后来尝试了测评机对拍,但是在随机生成的数据质量堪忧,能够找到的bug有限,还是得靠人工构造的数据(以及抱别人大腿),第二次作业对拍找到了一些些bug,第三次找到了好几个随便测测就会挂的bug...
在容器的选择上基本使用了HashMap存储id以及对应信息,存取比较方便并且快速。Person类中的Message用了LinkedList,这样头插入就可以直接利用addFirst方法。
在并查集以及最短路里面因为测试中person的人数以及指令的数量都被限制,我都很懒惰地使用了数组,疯狂被吐槽,也因为懒惰也没有去更改。写代码的时候因为不熟悉迭代器出了一些bug,后来还是用了简单暴力的foreach。在写博客的时候去深入了解了一下Iterator。
第一次作业主要的难点在于isCircle和queryBlockSum函数的设计。我在这里使用了增加了路径压缩的并查集,并且加了Flag用于表示需不需要重新计算。
第二次作业Group中的getAgeVar这个方法原本我就是用的规格中所给的方法实现,没有想到可以通过简单的数学计算化简,改进之后整体速度快了很多。
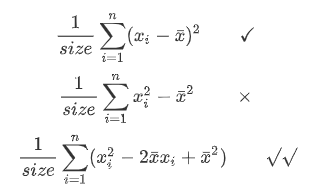
还有queryValueSum这个方法,我原来是用的循环,很容易被卡,后来改成了在addToGroup以及addRelationship的时候更新,速度快了很多。
第三次作业复杂的地方主要有两个,一个是deleteColdEmoji,一个就是sendIndirectMessage,对于第一个由于复杂度应该是O(n),使用迭代器或者for或者foreach的速度差别应该不是很大。这里简单概括一下不同遍历方法对于不同容器的效率。
ArrayList //按照效率从高到低
- for 由于for按照数组下标查询,复杂度为O(1)
- Iterator
- foreach
LinkedList
- Iterator
- foreach
- for 对于LinkedList按照下标查询使用时顺着节点顺序查找,时间复杂度为O(n)
HashMap //第二三四种方法在不同数据量下有一定波动
- entrySet的迭代器遍历
- entrySet的for循环遍历
- 迭代器遍历keySet()后map.get(key)
- for循环遍历keySet()后Map.get(key)
- for循环直接遍历
由于foreach的底层原理是实现Iterator,两者速度差距不大
总得来说,迭代器通常更优,如果需要遍历时删除更是几种方法中最优的选择。对于Hashmap,对entrySet遍历比keySet以及valueSet快。
因为在用Iterator的时候出现了bug,我后来又换成了foreach。课下对Iterator进行了一些学习,它的功能其实比较简单,主要通过一个Cursor进行正向迭代,只有四个方法, next() 、 hasNext() 、remove()、forEachRemaining(),前三个方法都比较熟悉,对于forEachRemaining()则是在对集合中剩余的元素进行操作,也即使cursor之后的元素。
由于主要的框架都由课程组给出,这里主要对第三次作业的图模型进行分析。我认为我的代码并没有很好的体现网络模型,只是根据需要实现的方法补充了其需要的数据结构。我单设了一个类用于存储与图相关的信息并实现最短路径等计算(实际原因是不单抽出来MyNetWork就超过500行了,但这样确实也让MyNetwork里的方法的逻辑更清晰了一些),但是这里写的实在是不够优雅。father用于存储节点的父节点,rank用于存储节点的秩,这两部分是为了并查集连通块数量,上面提到的静态数组就是它俩,为此次还定义了HashMap用作id和序号的映射;定义了Edge类实现Comparable接口,作为边的数据结构;嵌套ArrayList作为图的存储。整体来说更好的写法应该是把静态数组换成ArrayList或者HashMap。把图类抽出来的好处就是,新增关系之后对现有数据的维护就可以更好地整合。
因为第一次根据JML写代码,会出现读不全的情况。比如addRelation只对一人执行、isCircle少了异常判断等蠢蠢的问题..
强测和互测中因为Exception计数的问题挂了两个点并且被hack了两次,没有考虑到id1 == id2的时候只需要加一次。在计算blockSum的时候忘记并查集可以记录连通块的功能,暴力搜索导致有的时候会TLE。
这一次作业在上一次的基础上增加了Group,总体难度没有增加太多。G
主要的Bug是group人数1111的判断写错了(最气人的是我不是没看到是写错了..) 判断是否大于1111的位置不太对,导致行为和规格不相符。
本次作业新增不同种类的message以及不同sendmessage的方式,JML变得很长很难读,容易看漏,优先级和括号也非常容易搞混。前两次的错误其实都可以通过测试测出来,所以这一次加强了测试,也确实通过了强测也没有被hack。
这一次作业过中测并没有前两次顺利,找了好久都还是会挂一个点,但也因此仔仔细细读了好几遍JML和自己的代码,也发现了很多小bug。比如在addMessage中没有添加EmojiId的判断,传到Exception的id是messageId而不是EmojiId,群发红包的时候除的是所有group的数目而不是group内的人数等等这些小问题。
相对简单的单元做的并没有比前两个单元好,主要还是测试不够+检查不够,不过也体会到了一个比较完整的比较贴近实际的从给定需求入手、以测试结尾的程序开发过程,官方给出的接口也让我们更好地体会架构。
原文:https://www.cnblogs.com/nie-s/p/14820644.html