采集企业官网的产品数据,以ASM-Pacific科技公司https://www.asmpacific.com/zh-cn/为例。
网站数据是动态加载的,点击加载更多进行抓包。

看到Request URL为:https://www.asmpacific.com/zh-cn/index.php?option=com_asm&task=products.getAjax
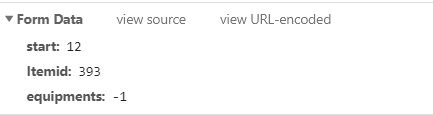
post请求,同时还携带有参数
返回的数据是商品的HTML,对于HTML文本可以直接取DOM树使用XPath进行解析。
这样看来思路很清晰,发送Request请求,解析商品HTML即可。但需求还要取得商品的分类标签

每件商品还需要有类别标签信息,所以第一步是先获取分类标签

每一类商品标签都有对应的value作为商品标签的id,这也是进行动态请求的参数
以焊线机为例,标签id为22,
请求参数equipments:22

最后是获取商品详细信息,同样是动态加载,需要商品id作为参数,而商品id则需要在上面分类商品列表中得到。
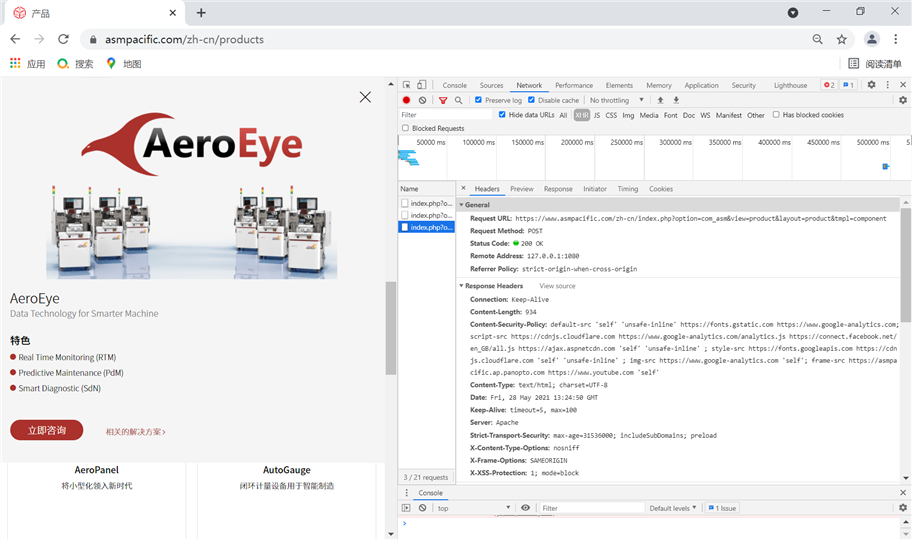
这样为了获取商品信息和分类,需要进行三级动态加载。
htmlutil是封装好的解析工具
import copy import scrapy import json from scrapy import Request from lxml import etree import ASMPacificPro.tools.htmlutil as htmlutil class AsmpacificSpider(scrapy.Spider): name = ‘ASM‘ def start_requests(self): # 获取初始请求 meta = {} meta[‘webid‘] = self.name meta[‘website‘] = ‘ASM Pacific Technology Ltd‘ meta[‘entName‘] = ‘ASM太平洋科技有限公司‘ meta[‘entNameEng‘] = ‘ASM Pacific Technology Ltd‘ # 商品首页 url = ‘https://www.asmpacific.com/zh-cn/products‘ yield Request(url=url, meta=meta) def parse_cis(self, response): # 商品详情页动态请求 item_url = "https://www.asmpacific.com/zh-cn/index.php?option=com_asm&view=product&layout=product&tmpl=component" html = response.body.decode(‘utf-8‘) dom = etree.HTML(html) json_dict = json.loads(response.text) data = json_dict["data"] dom = etree.HTML(data) items = dom.xpath(‘//*[@ class="item"]‘) meta = response.meta # start 商品数 num = len(items) # 类别id category_id = meta[‘category_id‘] meta[‘start‘] = meta[‘start‘] + num for item in items: meta = copy.deepcopy(response.meta) # 产品图片 x = ‘./div/img‘ img, alt = htmlutil.getimglink(item, x, response.request.url) meta[‘img‘] = img # 产品名称 x = ‘./h3/text()‘ name = htmlutil.gettext(item, x) meta[‘name‘] = name # 产品简介 x = ‘./p/text()‘ anchor = htmlutil.gettext(item, x) meta[‘anchor‘] = anchor # 商品id x = ‘./@data-id‘ item_id = htmlutil.gettext(item, x) new_url = item_url + "&id=" + item_id print(new_url) yield Request(url=new_url, method="POST", callback=self.parse_detail, meta=meta) def parse_detail(self, response): html = response.body.decode(‘utf-8‘) dom = etree.HTML(html) meta = response.meta # 产品信息 x = ‘.//div[@class="features"]‘ content_xml, content = htmlutil.gettextf(dom, x) item = {} item[‘name‘] = meta[‘name‘] item[‘entNameEng‘] = meta[‘entNameEng‘] item[‘entName‘] = meta[‘entName‘] item[‘category‘] = meta[‘category‘] item[‘description‘] = None item[‘webid‘] = meta[‘webid‘] item[‘website‘] = meta[‘website‘] item[‘img‘] = meta[‘img‘] item[‘content‘] = content item[‘content_xml‘] = content_xml item[‘url‘] = response.request.url item[‘urlList‘] = meta.get(‘urlList‘) item[‘mark‘] = 0 item[‘node‘] = None item[‘dataSheet‘] = None dic = {} dic[‘__db‘] = ‘incostar‘ dic[‘__col‘] = ‘product‘ dic[‘value‘] = item self.logger.info(‘fetch success:‘ + response.request.url) yield dic def parse_category(self, response): url = "https://www.asmpacific.com/zh-cn/index.php?option=com_asm&task=products.getAjax" # 商品详情页动态请求 item_url = "https://www.asmpacific.com/zh-cn/index.php?option=com_asm&view=product&layout=product&tmpl=component" html = response.body.decode(‘utf-8‘) dom = etree.HTML(html) json_dict = json.loads(response.text) data = json_dict["data"] dom = etree.HTML(data) items = dom.xpath(‘//*[@ class="item"]‘) meta = response.meta # start 商品数 num = len(items) # 类别id category_id = meta[‘category_id‘] meta[‘start‘] = meta[‘start‘] + num for item in items: meta = copy.deepcopy(response.meta) # 产品图片 x = ‘./div/img‘ img, alt = htmlutil.getimglink(item, x, response.request.url) meta[‘img‘] = img # 产品名称 x = ‘./h3/text()‘ name = htmlutil.gettext(item, x) meta[‘name‘] = name # 产品简介 x = ‘./p/text()‘ anchor = htmlutil.gettext(item, x) meta[‘anchor‘] = anchor # 商品id x = ‘./@data-id‘ item_id = htmlutil.gettext(item, x) new_url = item_url + "&id=" + item_id print(new_url) yield Request(url=new_url, method="POST", callback=self.parse_detail, meta=meta) # 回调 请求剩下商品 if num != 0: new_url = url + "&start=" + str(meta[‘start‘]) + "&Itemid=393&equipments=" + str(category_id) print(new_url) yield Request(url=new_url, method="POST", callback=self.parse_category, meta=meta) def parse(self, response): # 动态请求 url = "https://www.asmpacific.com/zh-cn/index.php?option=com_asm&task=products.getAjax" html = response.body.decode(‘utf-8‘) dom = etree.HTML(html) # 获取商品分类 x = ‘//*[@id="Equipment"]/label‘ # print(label.strip()) labels = dom.xpath(x) for label in labels: meta = copy.deepcopy(response.meta) # 商品类别category_id x = ‘./input/@value‘ category_id = htmlutil.gettext(label, x) meta[‘category_id‘] = category_id # 商品类别名称 x = ‘./text()|./a/text()‘ category = htmlutil.gettext(label, x) meta[‘category‘] = category meta[‘start‘] = 0 # 拼接post请求url new_url = url + "&equipments=" + category_id print("商品类别号" + category_id) print("商品类别名称" + category) yield Request(url=new_url, method="POST", callback=self.parse_category, meta=meta)
原文:https://www.cnblogs.com/wkfvawl/p/14823858.html