1 后台
from django.core.paginator import Paginator from django.db.models import Q from django.forms import model_to_dict from django.http import JsonResponse # 做全部查询 - 供调用 def do_get_all_data(s_model, page_index, page_size): # 精准查询 sq_set = get_all_data(s_model) # 获取分页数据和paginator page_data, paginator = get_paginator(sq_set, page_index, page_size) datas = [] for data in page_data: # 查询结果为一个包含model对象的列表 循环该列表获取到每一个Model对象 # 把Model对象转换成字典,把这些字典添加一个list中 datas.append(model_to_dict(data)) result = {‘code‘: 1, ‘page_index‘:page_index, ‘page_size‘: page_size, ‘total‘: paginator.count, ‘data‘: datas, ‘msg‘: ‘成功‘ } return JsonResponse(result, json_dumps_params={‘ensure_ascii‘: False}) # 做精准查询 - 供调用 def do_filter_request(request, filter_list, f_model, page_index, page_size): # 精准查询 fq_set = get_filter_data(request, filter_list, f_model) # 获取分页数据和paginator page_data, paginator = get_paginator(fq_set, page_index, page_size) datas = [] for data in page_data: # 查询结果为一个包含model对象的列表 循环该列表获取到每一个Model对象 # 把Model对象转换成字典 datas.append(model_to_dict(data)) # 把这些字典添加一个list中 result = {‘code‘: 1, ‘page_index‘:page_index, ‘page_size‘: page_size, ‘total‘: paginator.count, ‘data‘: datas, ‘msg‘: ‘成功‘ } return JsonResponse(result, json_dumps_params={‘ensure_ascii‘: False}) # 做模糊查询 - 供调用 def do_search_request(request, search_field, search_list, s_model, page_index, page_size): # 精准查询 fq_set = get_search_data(search_field, search_list, s_model) # 获取分页数据和paginator page_data, paginator = get_paginator(fq_set, page_index, page_size) datas = [] for data in page_data: # 查询结果为一个包含model对象的列表 循环该列表获取到每一个Model对象 # 把Model对象转换成字典 datas.append(model_to_dict(data)) # 把这些字典添加一个list中 result = {‘code‘: 1, ‘page_index‘:page_index, ‘page_size‘: page_size, ‘total‘: paginator.count, ‘data‘: datas, ‘msg‘: ‘成功‘ } return JsonResponse(result, json_dumps_params={‘ensure_ascii‘: False}) # 获取分页数据 def get_paginator(request_list, page_index, page_size): # 获取 paginator 对象 paginator=Paginator(request_list,page_size) # 获取某页的数据 page_data=paginator.page(page_index) return page_data, paginator # 精准查询 def get_filter_data(request, filter_list, f_model): ‘‘‘ request: 客户端请求 filter_list:查询哪些字段 f_model:使用哪个model查 ‘‘‘ dict = {} # 遍历filter_list,用户输入和filter内容生成字典 for field in filter_list: value = request.GET.get(field) if value is not None: dict[field] = value if dict is not None: q_set = f_model.objects.filter(**dict) return q_set # 模糊查询 def get_search_data(search_value, search_list, s_model): ‘‘‘ request: 客户端请求 search_field:查询哪个字段 search_list:查询哪些字段 s_model:使用哪个model查 ‘‘‘ # search_field = request.GET.get(search_field) dict = {} q = Q() for field in search_list: dict[‘{}__contains‘.format(field)] = search_value q = q | Q(**dict) q_set = s_model.objects.filter(q) return q_set # 全部查询 def get_all_data(s_model): ‘‘‘ s_model:使用哪个model查 ‘‘‘ q_set = s_model.objects.all().order_by(‘id‘) return q_set
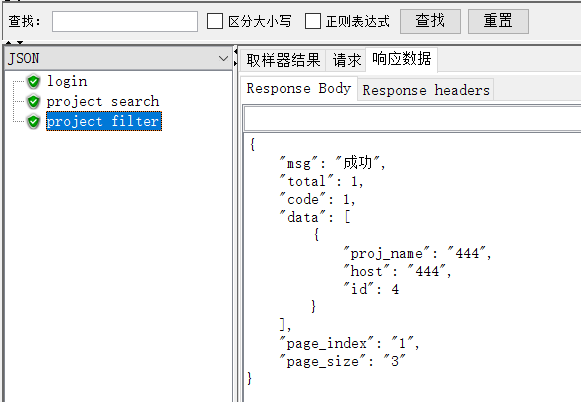
# 查询全部 class ProjectList(View): @login_check def get(self, request): page_index = request.GET.get(‘page_index‘, 1) page_size = request.GET.get(‘page_size‘, 10) print(page_index) print(page_size) # 全部查询 result = do_get_all_data(Project, page_index=page_index, page_size=page_size) return result # 模糊查询 class SearchProject(View): @login_check def get(self, request): page_index = request.GET.get(‘page_index‘, 1) page_size = request.GET.get(‘page_size‘, 10) search_field = request.GET.get(‘proj_name‘) print(page_index) print(page_size) print(search_field) search_list = [‘proj_name‘] # 模糊查询 result = do_search_request(request, search_field, search_list, Project, page_index=page_index, page_size=page_size) return result # 精准查询 class FilterProject(View): @login_check def get(self, request): page_index = request.GET.get(‘page_index‘, 1) page_size = request.GET.get(‘page_size‘, 10) print(page_index) print(page_size) filter_list = [‘proj_name‘] # 模糊查询 result = do_filter_request(request, filter_list, Project, page_index=page_index, page_size=page_size) return result
# 工程urls urlpatterns = [ path(‘admin/‘, admin.site.urls), path(‘v1/user/‘, include((‘user.urls‘, ‘apps.user‘), ‘user‘)), # 分布式路由,匹配到/v1/user后,到 user urls中找 user 后面的path path(‘v1/project/‘, include((‘project.urls‘, ‘apps.project‘), ‘project‘)), ] # 产品urls urlpatterns = [ path(‘add‘, AddProject.as_view(), name=‘add‘), path(‘list‘, ProjectList.as_view(), name=‘list‘), path(‘search‘, SearchProject.as_view(), name=‘search‘), path(‘filter‘, FilterProject.as_view(), name=‘filter‘), ]
2 前台
// 查询全部 export const project_list = query => { return fetch(baseurl + ‘/v1/project/list?‘ +‘page_index=‘+query.page_index+‘&page_size=‘+query.page_size, { method: ‘GET‘, // params: query, headers: new Headers({‘authorization‘: localStorage.getItem(‘token‘)}), }).then(response => { return response.json() }) } // 模糊查询 export const search_project = query => { return fetch(baseurl + ‘/v1/project/search?‘ +‘page_index=‘+query.page_index+‘&page_size=‘+query.page_size+‘&proj_name=‘+query.proj_name, { method: ‘GET‘, // params: query, headers: new Headers({‘authorization‘: localStorage.getItem(‘token‘)}), }).then(response => { return response.json() }) }
import {project_add, project_list,search_project} from "@/api/lizi"; created() { // 当页面创建时,请求产品列表 this.getData(); }, // 获取 easy-mock 的模拟数据 getData() { project_list(this.query).then(res => { this.tableData = res.data; this.pageTotal = res.total; }); }, // 分页导航 handlePageChange(val) { console.log(this.query) console.log(`当前页: ${val}`); this.$set(this.query, "page_index", val); this.getData(); },
原文:https://www.cnblogs.com/lizitestdev/p/14829266.html