对于异常类型,均使用HashMap<Integer, Integer>统计每个id出现异常的个数
对于MyPerson也使用的是
private HashMap<Integer, Boolean> acquaintanceNew;
private HashMap<Integer, Integer> valueNew;
来维护一个对于一个人,是否有连接以及连接的权值是多少。
对于MyGroup也使用的是
private HashMap<Integer, Boolean> peopleNew;
private HashMap<Integer, MyPerson> people;
来维护group里一个人是否存在以及存在的人对应的MyPerson
为了Network能够高效的实现,同时我定义了一种数据类型,叫做MyNode,是一种二元结构,有
private int messageid;
private int heat;
其主要功能是二元排序,排序规则为先按heat排序,再按id排序。
对于MyNetwork 使用的容器较为复杂,原因见代码里的注释部分。
private HashMap<Integer, Integer> realid;
private ArrayList<Integer> fa;
//由于id范围较大,先用realid进行离散化,接着再用并查集
private ArrayList<Group> groups;
// 由于group<=5,用arraylist维护常数较小
private HashMap<Integer, Person> peopleNew;
private HashMap<Integer, Message> messagesNew;
//维护network里的人和message
private HashMap<Integer, Integer> dis;
private HashMap<Integer, Integer> vis;
//dijikstra算法中使用
private TreeMap<Integer, MyNode> emojis;
//维护存在的emoji
private TreeSet<MyNode> heats;
//维护存在的emoji,并按照heat进行排序,这样后期迭代器就可以按照heat从小到大进行枚举了。
private ArrayList<Integer>[] emojimessages;
//按照id维护emojimessage
如果直接按照JML实现,复杂度为\(n^2\),用并查集后均摊复杂度基本为o(1)
并查集直接维护即可
单次暴力统计复杂度是\(n^2\),但是注意只有每次修改的时候会最多和n个人修改,所以统计目前的group内的权值和,修改的时候只考虑加入/删除的人对权值和的影响即可,复杂度为o(n)
其实还有一种很妙的分块做法,复杂度为根号n,不过最短路复杂度过大,这里不是复杂度瓶颈,就不多写了
众所周知,最短路有各种算法可以求,而spfa以及在NOI2018宣告了死刑,所以要用dijikstra来求最短路
平均值即为和/人数,统计和之后可以单次o(n)求
方差为\(\sum(a[i]-avg)^2\) 展开后即为\(\sum a[i]^2 -2*\sum a[i]*avg + n*avg^2)\),统计相关参数即可
这里用二分更合适一些,单词复杂度为log,不过有很多on的了,我就没有写log的做法。
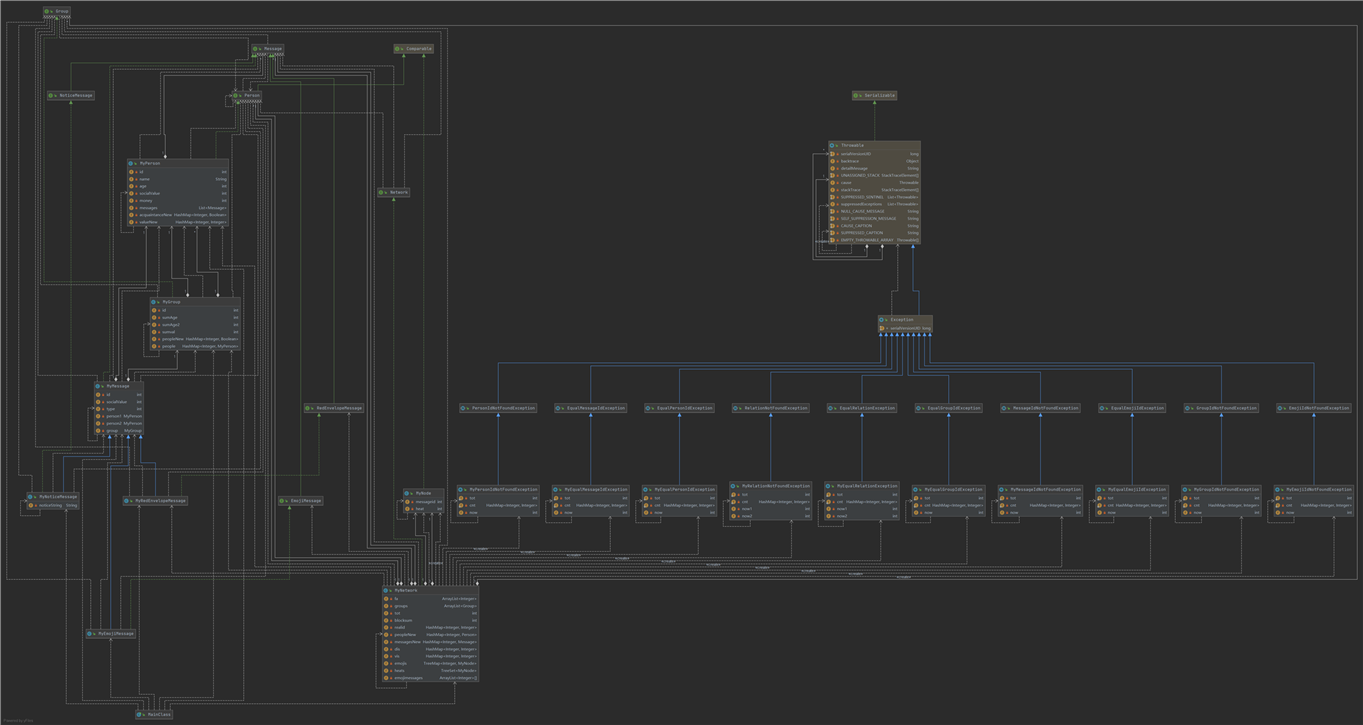
MyPerson最基础。
MyMessage用了MyPerson进行维护。
MyGroup用了MyMessage和MyPerson
MyNetWork用了MyMessage MyGroup和MyPerson
感谢XX, CJY, LXH, GYP 四位优秀的ACM选手给我参考了他们的数据与思路,让我受益匪浅,尤其是XX同学的数据,出一个hack掉我一个,没有她我估计就是0分了。
总是改错代码
不然容易乱
原文:https://www.cnblogs.com/yyxzhj/p/14831924.html