论文:《You Only Look Once: Unified, Real-Time Object Detection》
https://arxiv.org/abs/1506.0264
网络中的亮点:
Yolo v1的思想:
第一,将一副图片分成s*s个网络,如果目标中心落在网格,则这个网格负责预测这个目标。例如:图片分成7*7,狗的中心落在中心格子上。
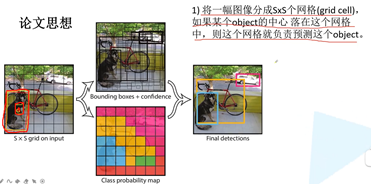
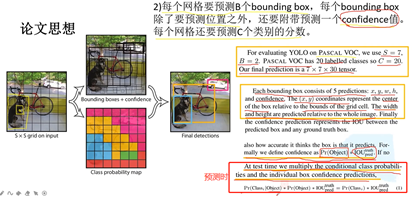
第二,每个grid cell要预测B个bounding box,每个bounding box除了预测位置之外,还有confidence值。每个网格还要预测C类别分数。没有anrch概念,直接预测它的坐标信息。
损失函数:
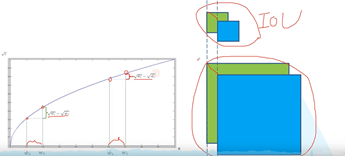
三部分:对目标边界框的损失,对confidence的损失,对类别的损失。用误差平方和求解。对于宽和高进行开根号处理。

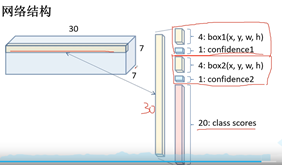
网络结构:

综述:
Joseph Redmon(2016)利用直接回归位置构建一阶段的YOLO模型,实现了45FPS 448x448,63.4mAP。
论文:《YOLO9000:Better, Faster, Stronger》
https://arxiv.org/abs/1612.08242
全流程多尺度方法。数据多尺度,网络检测头多尺度,一个检测头检测多尺度图片。
网络中的亮点:
检测效果在当年是非常有优势的。
1、在每个卷积层后面加上了BN层,添加了BN层之后对我们的训练收敛帮助非常大的,减少了所需正则化处理。提升了2个点,也可以移除dropourt。
2、采用更高分辨率的分类器,448*448,提升了4个百分点mAP的提升。
3、尝试使用anchor边界框,能够简化目标边界框预测的问题,也能够使网络更容易学习。没有使用anchor时69.5mAP,召回率81%;使用anchor之后,69.2mAP,召回率88%。虽然mAP降低了,但是召回率提升,说明了有更多提升的空间。
4、聚类。为什么要采用给定的anchor,根据工程经验,给出k-means聚类方法,获得priors的方法。
5、关于目标边界框预测的解释:


通过sigmoid函数进行限制,值的大小在0-1之间。让每个anchor负责每个grid cell区域内的目标。这种方法有五个点的提升,说明更加合理。

To就是confidence。五个参数。
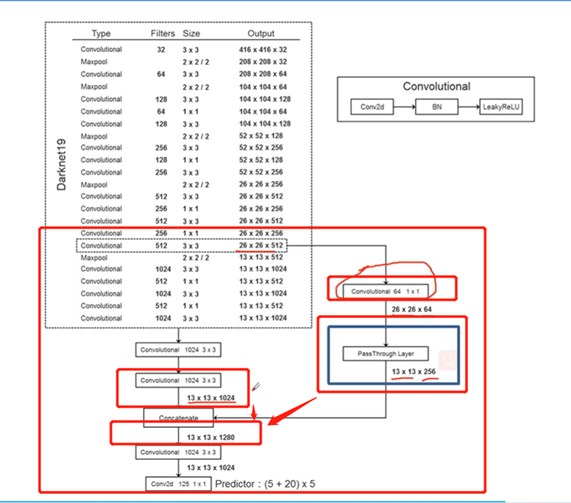
6、在预测特征图中结合更底层的预测信息,因为底层信息会包含更多的图像细节在里面,这些细节是检测小目标所需要的。这也说明了直接拿高层的信息进行检测效果是很差的。将高层信息与底层信息进行融合。通过passthrough layer进行融合,将相对底层特征图与高层特征图进行融合从而提升我们检测小目标的效果。用一个1*1的降维卷积层,深度变小,维度变小,拼接。
7、多尺度训练,替换掉固定尺寸。
网络结构:
卷积核个数,卷积核大小3*3,默认pading为1.
卷积没有bais,BN+relu。最后一个不同,只有卷积。
网络训练细节

数据增强同yolo v1和SSD。
综述:
Joseph Redmon(2016)采用BN层、高分辨率图像微调分类模型、Anchor Boxes和约束预测边框的位置的方法,对YOLO模型进行优化,提出YOLOv2模型,mAP值从第一次的63.4提高到78.6。
论文:《YOLOv3: An Incremental Improvement》
https://pjreddie.com/media/files/papers/YOLOv3.pdf
网络中的亮点:
特征金字塔可以在速度和准确率之间进行权衡,可以通过它获得更加鲁棒的语义信息。
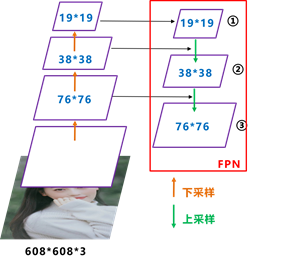
图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。
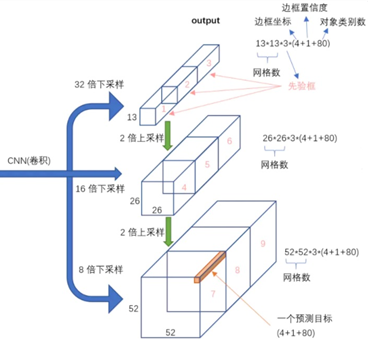
网络结构:
YOLO v3使用了Darknet-53的前面的52层,大量使用残差的跳层连接,并且为了降低池化带来的特征丢失现象,作者直接摒弃了POOLing。
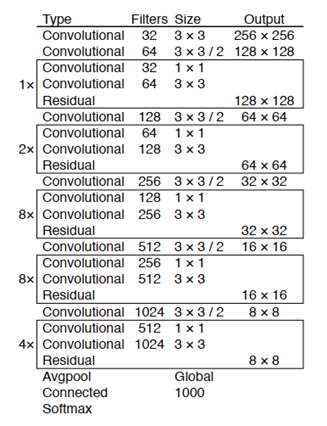
综述:
Joseph Redmon(2018)利用Darknet-53 骨架、FPN金字塔特征图、多尺度特征方法,并用logistic取代了softmax,调整了网络结构,搭建YOLOv3模型。在28.2 mAP下运行22毫秒,与SSD一样准确,但速度快三倍,实现57.9 AP50,性能相似,但要快3.8倍。
论文:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
https://arxiv.org/pdf/2004.1093
网络中的亮点:
1、Input: Mosaic 马赛克数据增强
Mosaic图像增强:图像的随机裁剪,图像的随机水平翻转,以及亮度色度饱和度等随机的调整,那这个具体实现,是将多张图像拼接在一起,四张图像进行拼接,进行预测。
优点:增加数据多样性;增加数据目标个数;BN能一次性统计多张图片的参数。
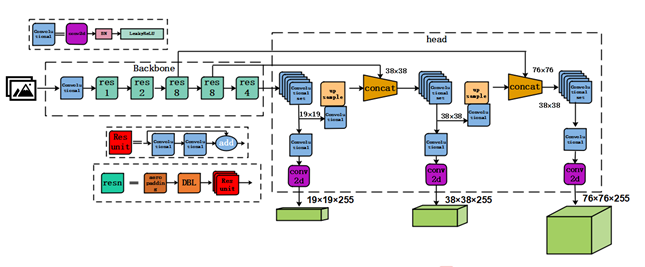
2、BackBone: CSP模块、Mish激活、Droupblock
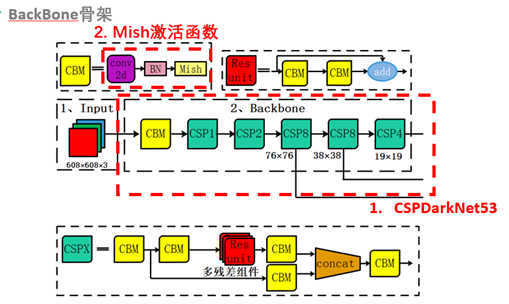
CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。
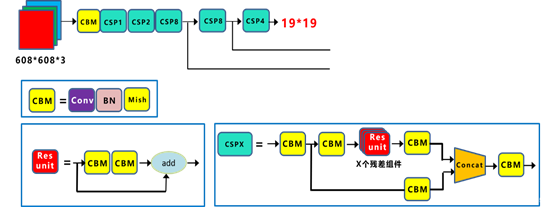
这里因为CSP模块比较长,不放到本处,大家也可以点击Yolov4的netron网络结构图,对比查看,一目了然。
每个CSP模块前面的卷积核的大小都是3×3,步长为2,因此可以起到下采样的作用。
因为Backbone有5个CSP模块,输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19
经过5次CSP模块后得到19*19大小的特征图。
而且作者只在Backbone中采用了Mish激活函数,网络后面仍然采用Leaky_relu激活函数。
Yolov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。
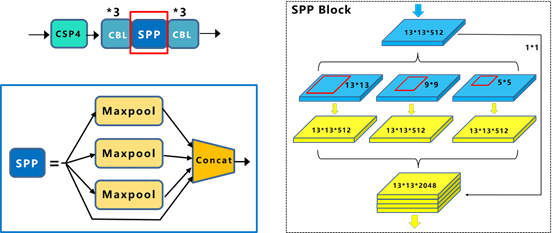
3、Neck: SPP模块、FPN+PAN模块
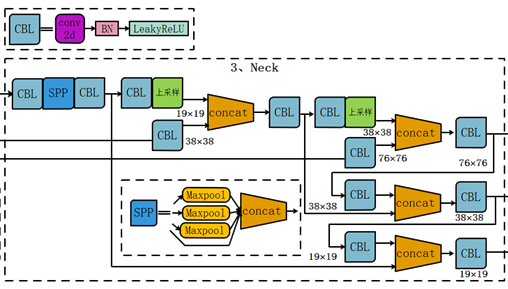
在预测之前,加入SPP网络。其余的都一样。
yolo4的neck结构采用该模式,我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。
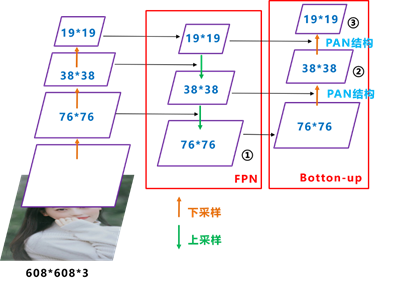
和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。其中包含两个PAN结构。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行特征聚合,这样的操作确实很皮。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
4、Head: CIoU_Loss


网络结构:
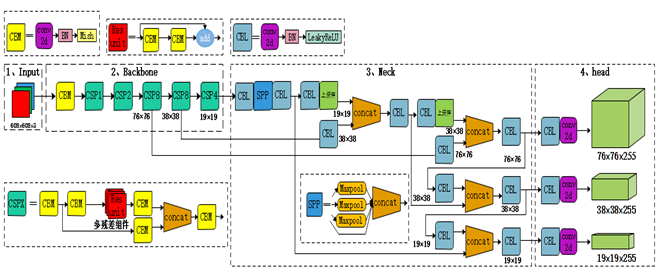
综述:
Alexey Bochkovskiy(2020)利用CSPdarknet53、Mish激活、Droupblock、SPP多尺度融合、PAN模块和DIOU_nms损失方法,提出YOLOv4模型。实现了在Tesla V100上,MS COCO数据集以65帧每秒的实时速度运行,AP为43.5% (65.7% AP50)。
原文:https://www.cnblogs.com/xmy-0904-lfx/p/14842248.html