简介
Spring Data JPA 是在 JPA 规范的基础上进行进一步封装的产物,和之前的 JDBC、slf4j 这些一样,只定义了一系列的接口。具体在使用的过程中,一般接入的是 Hibernate 的实现,那么具体的 Spring Data JPA 可以看做是一个面向对象的 ORM。虽然后端实现是 Hibernate,但是实际配置和使用比 Hibernate 简单不少,可以快速上手。如果业务不太复杂,个人觉得是要比 Mybatis 更简单好用。
本文就简单列一下具体的知识点,详细的用法可以见参考文献中的博客。本文具体会涉及到 JPA 的一般用法、事务以及对应 Hibernate 需要掌握的点。
基本使用
1. 创建项目,选择相应的依赖。一般不直接用 mysql 驱动,而选择连接池。
<dependency>???<groupId>org.springframework.bootgroupId>???<artifactId>spring-boot-starter-data-jpaartifactId>dependency><dependency>???<groupId>mysqlgroupId>???<artifactId>mysql-connector-javaartifactId>???<scope>runtimescope>dependency><dependency>???<groupId>com.alibabagroupId>???<artifactId>druid-spring-boot-starterartifactId>???<version>1.1.18version>dependency>
2. 配置全局yml文件
spring:?datasource:???type:?com.alibaba.druid.pool.DruidDataSource???driver-class-name:?com.mysql.cj.jdbc.Driver???url:?jdbc:mysql://172.21.30.61:3306/gpucluster?serverTimezone=Hongkong&characterEncoding=utf-8&useSSL=false???username:???password:?jpa:????hibernate:??????ddl-auto:?update????open-in-view:?false????properties:??????hibernate:????????dialect:?org.hibernate.dialect.MySQL57Dialect????????show_sql:?false????????format_sql:?truelogging:??level:????root:?info?#?是否需要开启?sql?参数日志????org.springframework.orm.jpa:?DEBUG????org.springframework.transaction:?DEBUG????org.hibernate.engine.QueryParameters:?debug????org.hibernate.engine.query.HQLQueryPlan:?debug????org.hibernate.type.descriptor.sql.BasicBinder:?trace
hibernate.ddl-auto: update??实体类中的修改会同步到数据库表结构中,慎用。
show_sql?可开启 hibernate 生成的 sql,方便调试。
logging?下的几个参数用于显示 sql 的参数。
3.?创建实体类并添加 JPA 注解
@Entity@Table(name?=?"user")@Datapublic?class?User?{????@Id????@GeneratedValue(strategy?=?GenerationType.IDENTITY)????private?Long?id;????private?String?name;????private?Integer?age;????private?String?address;????private?LocalDateTime?createTime;????private?LocalDateTime?updateTime;}4.?创建对应的 Repository
实现 JpaRepository 接口,生成基本的 CRUD 操作样板代码。并且可根据 Spring Data JPA 自带的 Query Lookup Strategies 创建简单的查询操作,在 IDEA 中输入?findBy??等会有提示。
public?interface?IUserRepository?extends?JpaRepository<User,Long>?{????ListfindByName(String?name);????ListfindByAgeAndCreateTimeBetween(Integer?age,?LocalDateTime?createTime,?LocalDateTime?createTime2);}Repository 继承了?JpaRepository?后会有一系列基本的默认 CRUD 方法,例如:
ListfindAll();PagefindAll(Pageable?pageable);T?getOne(ID?id);T?S?save(T?entity);void?deleteById(ID?id);
Repository 继承了?JpaRepository?后,可在接口中定义一系列方法,它们一般以?findBy、countBy、deleteBy、existsBy?等开头,如果使用 IDEA,输入以下关键字后会有响应的提示。例如:
public?interface?IUserRepository?extends?JpaRepository<User,Integer>{????User?findByUsername(String?username);????Integer?countByDept(String?dept);}对于一些单表多字段查询,使用这种方式就非常舒服了,而且完全 oop 思想,不需要思考具体的 SQL 怎么写。但有个问题,字段多了之后方法名会很长,调用的时候会比较难受,这个时候可以利用 jdk8 的特性将它缩短,当然这种情况也可以直接用?@Query?写 HQL 或 SQL 解决。
User?findFirstByEmailContainsIgnoreCaseAndField1NotNullAndField2NotNull(final?String?email);
default?User?getByEmail(final?String?email)?{??return?findFirstByEmailContainsIgnoreCaseAndField1NotNullAndField2NotNull(email);}常见的操作可见?[附录?-?支持的方法关键词](###?支持的方法关键词)
@Transactional(readOnly?=?true)public?interface?UserRepository?extends?JpaRepository<User,?Long>?{??@Query(nativeQuery?=?true,?value?=?"select?*?from?user?where?tel?=??1")??List;
??@Modifying??@Transactional??@Query("delete?from?User?u?where?u.active?=?false")??void?deleteInactiveUsers();}@Query?中可写 HQL 和 SQL,如果是 SQL,则?nativeQuery = true。
//?复杂查询,创建?Specificationprivate?PagegetOrderInfoListByConditions(String?tel,?int?pageSize,?int?pageNo,?String?beginTime,?String?endTime)?{????Specificationspecification?=?new?Specification()?{????????@Override????????public?Predicate?toPredicate(Rootroot,?CriteriaQuery?query,?CriteriaBuilder?cb)?{????????????Listpredicate?=?new?ArrayList<>();????????????if?(!Strings.isNullOrEmpty(beginTime))?{????????????????predicate.add(cb.greaterThanOrEqualTo(root.get("createTime"),?DateUtils.getDateFromTimestamp(beginTime)));????????????}????????????if?(!Strings.isNullOrEmpty(endTime))?{????????????????predicate.add(cb.lessThanOrEqualTo(root.get("createTime"),?DateUtils.getDateFromTimestamp(endTime)));????????????}????????????if?(!Strings.isNullOrEmpty(tel))?{????????????????predicate.add(cb.equal(root.get("userTel"),?tel));????????????}????????????return?cb.and(predicate.toArray(new?Predicate[predicate.size()]));????????}????};????Sort?sort?=?new?Sort(Sort.Direction.DESC,?"createTime");????Pageable?pageable?=?new?PageRequest(pageNo?-?1,?pageSize,?sort);????return?orderInfoRepository.findAllEntities(specification,?pageable);}Specificationspecification?=?(root,?criteriaQuery,?criteriaBuilder)?->?{??Subquery?subQuery?=?criteriaQuery.subquery(String.class);??Root?from?=?subQuery.from(User.class);??subQuery.select(from.get("userId")).where(criteriaBuilder.equal(from.get("username"),?"mqy6289"));??return?criteriaBuilder.and(root.get("userId").in(subQuery));};return?userProjectRepository.findAll(specification);删除
直接使用默认的?deleteById()。
使用申明式查询创建对应的删除方法?deleteByXxx。
使用 SQL\HQL 注解删除
新增和修改
调用 save 方法,如果是修改的需要先查出相应的对象,再修改相应的属性。
Spring Boot 默认集成事务,所以无须手动开启使用?@EnableTransactionManagement?注解,就可以用?@Transactional注解进行事务管理。需要使用时,可以查具体的参数。
@Transactional?注解的使用,具体可参考:透彻的掌握 Spring 中 @transactional 的使用。
谈谈几点用法上的总结:
持久层方法上继承?JpaRepository,对应实现类?SimpleJpaRepository?中包含?@Transactional(readOnly?=?true)?注解,因此默认持久层中的?CRUD?方法均添加了事务。申明式事务更常用的是在?service?层中的方法上,一般会调用多个?Repository?来完成一项业务逻辑,过程中可能会对多张数据表进行操作,出现异常一般需要级联回滚。一般操作,直接在?Serivce?层方法中添加?@Transactional?即可,默认使用数据的隔离级别,默认所有?Repository?方法加入?Service?层中的事务。@Transactional?注解中最核心的两个参数是?propagation?和?isolation。前者用于控制事务的传播行为,指定小事务加入大事务还是所有事务均单独运行等;后者用于控制事务的隔离级别,默认和?MySQL?保持一致,为不可重复读。我们也可以通过这个字段手动修改单个事务的隔离级别。具体的应用场景可见我另一篇博客?谈谈事务的隔离性及在开发中的应用。同一个?service?层中的方法调用,如果添加了?@Transactional?会启动?hibernate?的一级缓存,相同的查询多次执行会进行?Session?层的缓存,否则,多次相同的查询作为事务独立执行,则无法缓存。如果你使用了关系注解,在懒加载的过程中一般都会遇到过?LazyInitializationException?这个问题,可通过添加?@Transactional,将?session?托管给?Spring?Transaction?解决。只读事务的使用。可在?service?层中全局配置只读事务?@Transactional(readOnly?=true),对于具有读写的事务可在对应方法中覆盖即可。在只读事务无法进行写入操作,这样在事务提交前,hibernate?就会跳过?dirty?check,并且?Spring?和?JDBC?会有多种的优化,使得查询更有效率。
JPA 自带的 Audit 可以通过 AOP 的形式注入,在持久化操作的过程中添加创建和更新的时间等信息。具体使用方法:
申明实体类,需要在类上加上注解 @EntityListeners(AuditingEntityListener.class)。
在 Application 启动类中加上注解 @EnableJpaAuditing
在需要的字段上加上 @CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy 等注解。
如果只需要更新创建和更新的时间是不需要额外的配置的。
如果需要进行级联查询,可用 JPA 的 @OneToMany、@ManyToMany 和 @OneToOne 来修饰,当然,碰到出现一对多等情况的时候,可以手动将多的一方的数据去查询出来填充进去。
由于数据库设计的不同,注解在使用上也会存在不同。这里举一个 OneToMany 的例子。
仓库和货物是一对多关系,并且在设计上,Goods 表中包含 Repository 的外键,则在 Repository 添加注解,Goods 上不需要。
@Entitypublic?class?Repository{??@OneToMany(cascade?=?{CascadeType.ALL})??@JoinColumn(name?=?"repo_id")??private?List}
public?class?Goods{}具体可参考:@OneToMany、@ManyToOne 以及 @ManyToMany 讲解(五)
JPA 的这几个注解和 Hibernate 的关联度比较大,而且一般适合于 code first 的形式,也就是说先有实体类后生成数据库。在这里我并不建议没有学习过 Hibernate 直接上手 Spring Data JPA 的人去使用这些注解,因为一旦加上关系注解后,从查询的角度虽然方便了,但是涉及到一些级联的操作,例如删除、修改等操作,容易采坑。需要额外去了解 Hibernate 的缓存刷新机制。
默认单数据源的情况下,我们只需要将自己的 Repository 实现 JpaRepository 接口即可,通过 Spring Boot 的 Auto Configuration 会自动帮我们注入所需的 Bean,例如?LocalContainerEntityManagerFactoryBean、EntityManager?、DataSource。
但是在多数据源的情况下,就需要根据配置文件去条件化创建这些 Bean 了。
配置文件添加多个数据源信息
spring:??datasource:????hangzhou:?#?datasource1??????type:?com.alibaba.druid.pool.DruidDataSource??????driver-class-name:?com.mysql.cj.jdbc.Driver??????url:?jdbc:mysql://172.17.11.72:3306/gpucluster?serverTimezone=Hongkong&characterEncoding=utf-8&useSSL=false??????username:?root??????password:?123456????shanghai:?#?datasource2??????type:?com.alibaba.druid.pool.DruidDataSource??????driver-class-name:?com.mysql.cj.jdbc.Driver??????url:?jdbc:mysql://172.21.30.61:3306/gpucluster?serverTimezone=Hongkong&characterEncoding=utf-8&useSSL=false??????username:?root??????password:?123456??jpa:????open-in-view:?false????properties:??????hibernate:????????dialect:?org.hibernate.dialect.MySQL57Dialect
数据源 bean 注入
@Slf4j@Configurationpublic?class?DataSourceConfiguration?{????@Bean(name?=?"HZDataSource")????@Primary????@Qualifier("HZDataSource")????@ConfigurationProperties(prefix?=?"spring.datasource.hangzhou")????public?DataSource?primaryDataSource()?{????????return?DataSourceBuilder.create().type(DruidDataSource.class).build();????}
????@Bean(name?=?"SHDataSource")????@Qualifier("SHDataSource")????@ConfigurationProperties(prefix?=?"spring.datasource.shanghai")????public?DataSource?secondaryDataSource()?{????????return?DataSourceBuilder.create().type(DruidDataSource.class).build();????}}注入 JPA 相关的 bean(一个数据源一个配置文件)
@Configuration@EnableTransactionManagement@EnableJpaRepositories(????????entityManagerFactoryRef?=?"entityManagerFactoryHZ",????????transactionManagerRef?=?"transactionManagerHZ",????????basePackages?=?{"cn.com.arcsoft.app.repo.jpa.hz"},????????repositoryBaseClass?=?IBaseRepositoryImpl.class)public?class?RepositoryHZConfig?{????private?final?DataSource?HZDataSource;????private?final?JpaProperties?jpaProperties;????private?final?HibernateProperties?hibernateProperties;
????public?RepositoryHZConfig(@Qualifier("HZDataSource")?DataSource?HZDataSource,?JpaProperties?jpaProperties,?HibernateProperties?hibernateProperties)?{????????this.HZDataSource?=?HZDataSource;????????this.jpaProperties?=?jpaProperties;????????this.hibernateProperties?=?hibernateProperties;????}
????@Primary????@Bean(name?=?"entityManagerFactoryHZ")????public?LocalContainerEntityManagerFactoryBean?entityManagerFactoryHZ(EntityManagerFactoryBuilder?builder)?{????????//?springboot?2.x????????Map????????????????jpaProperties.getProperties(),?new?HibernateSettings());????????return?builder.dataSource(HZDataSource)????????????????.properties(properties)????????????????.packages("cn.com.arcsoft.app.entity")????????????????.persistenceUnit("HZPersistenceUnit")????????????????.build();????}
????@Primary????@Bean(name?=?"transactionManagerHZ")????public?PlatformTransactionManager?transactionManagerHZ(EntityManagerFactoryBuilder?builder)?{????????return?new?JpaTransactionManager(entityManagerFactoryHZ(builder).getObject());????}}在之前配置的对应的包中添加相应的 repository 就可以了。如果数据源数据库是相同的,可实现一个主的 repository,其余继承一下。
JPA?与?Hibernate
在使用 Spring Data JPA 的时候,虽然底层是 Hibernate 实现的,但是我们在使用的过程中完全没有感觉,因为我们在使用 JPA 规范提供的 API 来操作数据库。但是遇到一些复杂的业务,或许任然需要关注 Hibernate,或者 JPA 底层的一些实现,例如 EntityManager 和 EntityManagerFactory 的创建和使用。
下面我就讲讲最核心的两点。
用过 Mybatis 的都知道,它属于半自动的 ORM,仅仅是将 SQL 执行后的结果映射到具体的对象,虽然它也做了对查询结果的缓存,但是一旦数据查出来封装到实体类后,就和数据库无关了。但是 JPA 后端的 Hibernate 则不同,作为全自动的 ORM,它自己有一套比较复杂的机制,用于处理对象和数据库中的关系,两者直接会进行绑定。
首先在 Hibernate 中,对象就不再是基本的 Java POJO 了,而是有四种状态。
临时状态 (transient): 刚用 new 语句创建,还未被持久化的并且不在 Session 的缓存中的实体类。
持久化状态 (persistent): 已被持久化,并且在 Session 缓存中的实体类。
删除状态 (removed): 不在 Session 缓存中,而且 Session 已计划将其从数据库中删除的实体类。
游离状态 (detached): 已被持久化,但不再处于 Session 的缓存中的实体类。
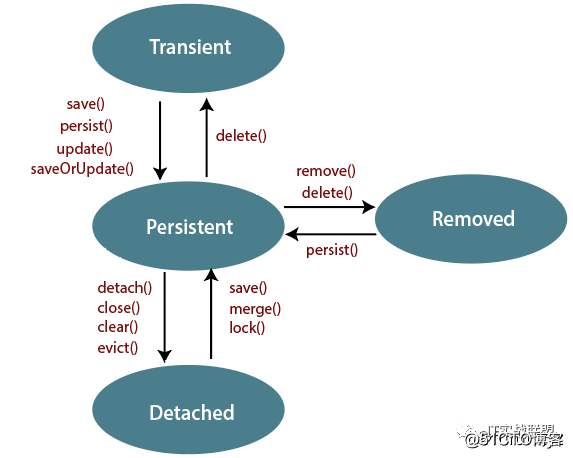
需要特别关注的是持久化状态的对象,这类对象一般是从数据库中查询出来的,同时会存在 Session 缓存中,由于存在缓存清理与 dirty checking 机制,当修改了对象的属性,无需手动执行 save 方法,当事务提高后,改动会自动提交到数据库中去。
当事务提交后,会进行缓存清理操作,所有 session 中的持久化对象都会进行 dirty checking。简单描述一下过程:
在一个事务中的各种查询结果都会缓存在对应的 session 中,并且存一份快照。
在事务 commit 前,会调用?session.flush()?进行缓存清理和 dirty checking。将所有 session 中的对象和对应快照进行对比,如果发生了变化,则说明该对象 dirty。
执行 update 和 delete 等操作将 session 中变化的数据同步到数据库中。
开启只读事务可屏蔽 dirty checking,提高查询效率。
Jpa 与 lombok 配合使用的问题产生 StackOverflowError
使用 Hibernate 的关系注解 @ManyToMany 时使用 @Data,执行查询时会出现 StackOverflowError 异常。主要是因为 @Data 帮我们实现了 hashCode() 方法出现了问题,出现了循环依赖。
解决方法:在关系字段上加上 @EqualsAndHashCode.Exclude 即可。
@EqualsAndHashCode.Exclude
@ManyToMany(fetch?=?FetchType.LAZY,cascade?=?{CascadeType.PERSIST})
private?SetLombok.hashCode issue with “java.lang.StackOverflowError: null”
Spring boot JPA:Unknown entity 解决方法
在采用两个大括号初始化对象后,再调用 JPA 的 save 方法时会抛出 Unknown entity 这个异常,这是 JPA 无法正确识别匿名内部类导致的。
解决方法:手动 new 一个对象再调用 set 方法赋值。
Spring boot JPA:Unknown entity 解决方法
使用关系注解时产生的 LazyInitializationException 异常
org.hibernate.LazyInitializationException: could not initialize proxy - no Session
如果使用 Hibernate 关系注解,可能会遇到这个问题,这是因为在 session 关闭后 get 对象中懒加载的值产生的。
解决方法:
在实体类中添加注解?@Proxy(lazy = false)
在 services 层的方法中添加?@Transactional,将 session 管理交给 spring 事务
本文主要讲了下 Spring Data JPA 的基本使用和一些个人经验。
ORM 发展至今,从 Hibernate 到 JPA,再到现在的 Spring Data JPA。可以看到是一个不断简化的过程,过去大段的 xml 已经没有了,仅保留基本的 sql 字符串即可。Spring Data JPA 虽然配置和使用起来简单,但由于它的底层依然是 Hibernate 实现的,因此有些东西仍然需要去了解。就目前使用而言,有以下几点感受:
要用好 Spring Data JPA,Hibernate 的相关机制还是需要有一定的了解的,例如前面提到的对象声明周期及 Session 刷新机制等。如果不了解,容易出现一些莫名其妙的问题。
如果是新手,个人不推荐使用关系注解。技术本身就是一步步在简化,如果不是非常复杂的例如 ERP 系统,没必要去使用 JPA 和 Hibernate 原生的东西,完全可以手动多次查询操作来代替关系注解。之所以这么讲,是因为对 JPA 的关系注解的使用,以及各种级联操作的类型理解不深,会存在一些隐患。
原文:https://blog.51cto.com/u_7117633/2856116