使用asreml分析数据时, 得到的是sln数据,进行多性状分析或者随机回归分析时,sln中的Level是1.001,小数点前面的1表示第一个性状,后面的001表示ID。
有时候需要将1.001分为1和001,R中的tidyverse中的separate可以分割,但是由于data.table中的fread读取时,将1.001当作数字,在分割时,1.010和1.100都分割为1,这明显是错误的。
txt数据:
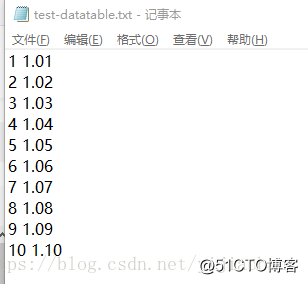
比如上面的数据,想将第二列分为1和1:10,但是第十行,分割结果为1!这不是我想要的。
library(data.table)
library(tidyverse)
dd?<-fread("d:/test-datatable.txt")
separate(dd,2,into=c("a","b"),sep="\\.",remove?=?T)#?V1?a??b#?1:??1?1?01#?2:??2?1?02#?3:??3?1?03#?4:??4?1?04#?5:??5?1?05#?6:??6?1?06#?7:??7?1?07#?8:??8?1?08#?9:??9?1?09#?10:?10?1??1在fread中增加参数:colClasses = “Level”
library(data.table)
library(tidyverse)#?dd?<-fread("d:/test-datatable.txt")dd?<-fread("d:/test-datatable.txt",colClasses?=?"Level")
dd
str(dd)
separate(dd,2,into=c("a","b"),sep="\\.",remove?=?T)#?V1?a??b#?1:??1?1?01#?2:??2?1?02#?3:??3?1?03#?4:??4?1?04#?5:??5?1?05#?6:??6?1?06#?7:??7?1?07#?8:??8?1?08#?9:??9?1?09#?10:?10?1?10fread 读取文件时 数字按照因素进行读取的方法 colClasses =
原文:https://blog.51cto.com/yijiaobani/2866261