ResNet 是残差网络(Residual Network)的缩写,是一种作为许多计算机视觉任务主干的经典神经网络。ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,ResNet最根本的突破在于它使得我们可以训练成功非常深的神经网路,如150+层的网络由于梯度消失的问题,训练非常深的神经网络是非常困难的。之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测、分割、识别等领域都纷纷使用ResNet,Alpha zero也使用了ResNet,所以可见ResNet确实很好用。
随着网络的加深,出现了训练集准确率下降的现象,可以确定这不是由于 过拟合 造成的,因为过拟合下训练集准确率很高。

造成这个问题的原因:
两种解决思路:
(1) 调整求解方法,比如更好的初始化、更好的梯度下降算法等;
(2) 调整模型结构,让模型更易于优化。
ResNet的作者从后者入手,探求更好的模型结构。将堆叠的几层 layer 称之为一个 block ,对于某个 block ,其可以拟合的函数为 $F(x)$ ,如果期望的潜在映射为 $H(x)$,与其让$F(x) $直接学习潜在的映射,不如去学习残差$H(x)?x$,即$F(x):=H(x)?x$,这样原本的前向路径上就变成了$F(x)+x$,用 $F(x)+x$ 来拟合 $H(x)$ 。作者认为这样可能更易于优化,因为相比于让 $F(x)$ 学习成恒等映射,让$F(x)$学习成 $0$ 要更加容易——后者通过$L2$正则就可以轻松实现。这样,对于冗余的 block ,只需$F(x)→0$就可以得到恒等映射,性能不减。
所以针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深;
ResNet网络结构如下:

ResNet效果图:

读图:随着网络的层数加深,误差越来越小。
网络中的亮点:
1、超深的网络结构(突破1000层)
2、提出residual模块
3、使用Batch Normalization加速训练,丢弃dropout。
为什么ResNet可以解决"随着网络加深,准确率不下降"的问题?
理论上,对于"随着网络加深,准确率下降"的问题,ResNet提供了两种选择方式,也就是 "identity mapping" 和 "residual mapping",如果网络已经到达最优,继续加深网络,"residual mapping"将被 push 为 0,只剩下"identity mapping",这样理论上网络一直处于最优状态,网络的性能也就不会随着深度增加而降低了。
$F(x)+x $ 构成的 block 称之为 Residual Block ,即残差块,如下图所示,多个相似的 Residual Block 串联构成 ResNet。
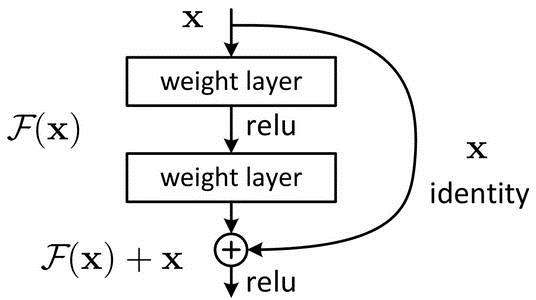
残差是什么?
ResNet提出了两种 mapping :(1) identity mapping,指图中"曲线"。(2) residual mapping,指除"曲线"部分,所以最后的输出是 $y=F(x)+x$ 。
identity mapping 指本身,也就是公式中的 $x$,而 residual mapping 指的是"差",也就是 $y?x$ ,所以残差指的就是 $F(x)$ 部分。
一个残差块有 2 条路径$F(x)$和 $x$,$F(x)$路径拟合残差,称之为残差路径,$x$ 路径为 identity mapping 恒等映射,称之为”shortcut”。图中的$⊕$为 element-wise addition,要求参与运算的 $F(x)$ 和 $x$ 的尺寸要相同。
产生如下问题:
残差路径
残差路径大致分成2种:
1、没有 bottleneck 结构,如下图左所示,称之为“basic block”。basic block 由 2 个 $3\times 3$ 卷积层构成,bottleneck block含$1\times 1$卷积层。
2、有 bottleneck 结构,即下图右中的$1\times 1$卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”;
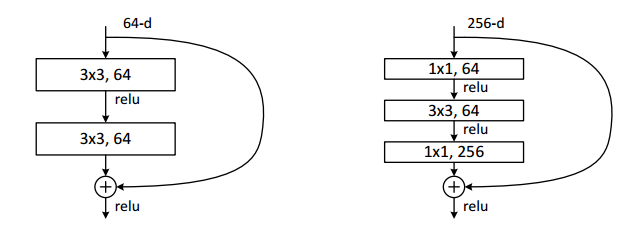
shortcut路径
shortcut路径可以分成 2 种:取决于残差路径是否改变 feature map 的数量和尺寸
1、将输入 $x$ 原封不动地输出
2、需要经过$1\times 1$ 卷积来升维 or/and 降采样,主要作用是将输出与 $F(x)$ 路径的输出保持 shape 一致,对网络性能的提升并不明显,两种结构如下图所示:

Residual Block之间的连接
在原论文中,$F(x)+x$经过 ReLU 后直接作为下一个 block 的输入 $x$。
对于 $F(x)$路径、shortcut 路径以及 block 之间的衔接,在论文 Identity Mappings in Deep Residual Networks 中有更进一步的研究。
ResNet 为多个 Residual Block 的串联,下面直观看一下 ResNet-34 与 34-layer plain net 和 VGG 的对比,以及堆叠不同数量Residual Block得到的不同ResNet。
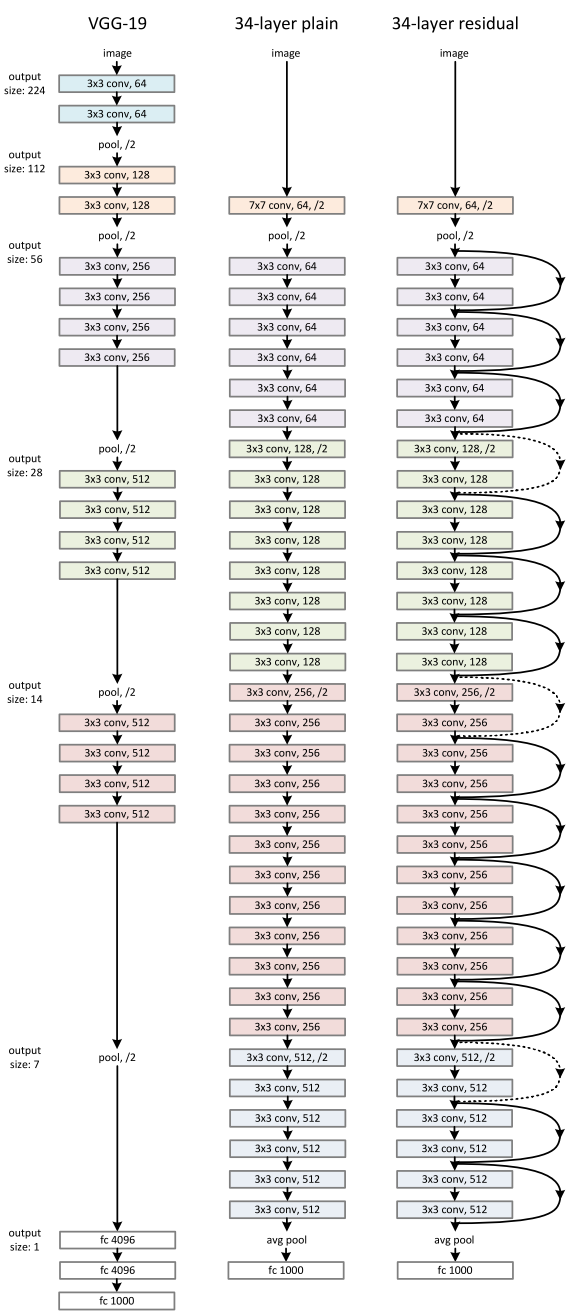

ResNet的设计有如下特点:
ResNet结构非常容易修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的宽度和深度,来得到不同表达能力的网络,而不用过多地担心网络的“退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。
下面为网络的性能对比:

上面的实验说明,不断地增加 ResNet 的深度,甚至增加到 1000 层以上,也没有发生 “退化” ,可见 Residual Block 的有效性。ResNet 的动机在于认为拟合残差比直接拟合潜在映射更容易优化,下面通过绘制 error surface 直观感受一下 shortcut 路径的作用,图片截自 Loss Visualization 。

可以发现:
原文:https://www.cnblogs.com/BlairGrowing/p/14853384.html