
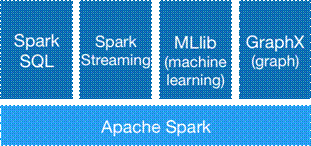
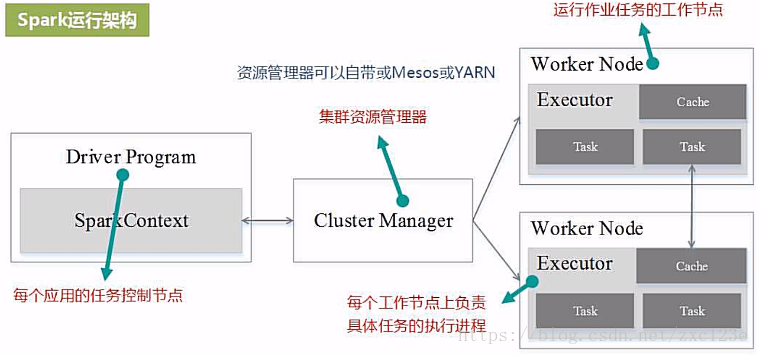
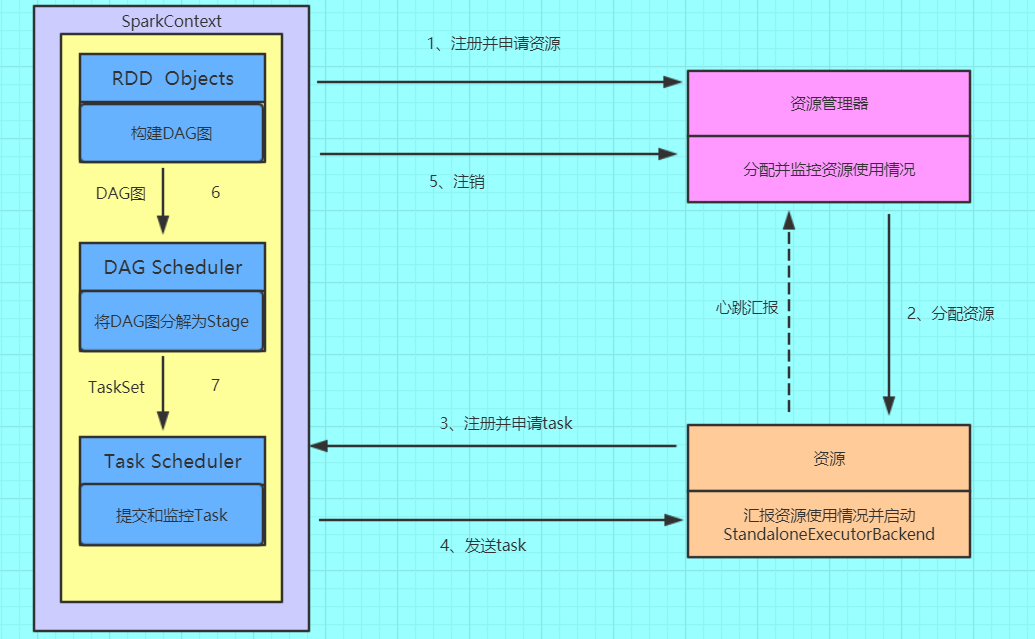
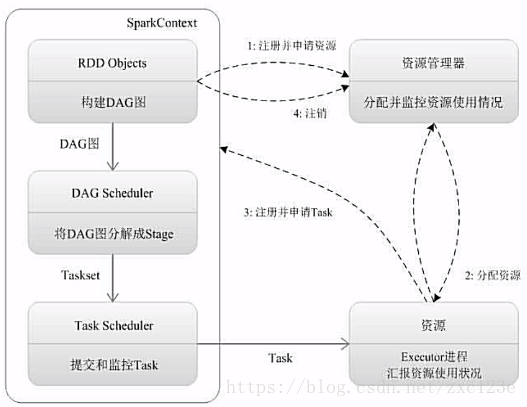
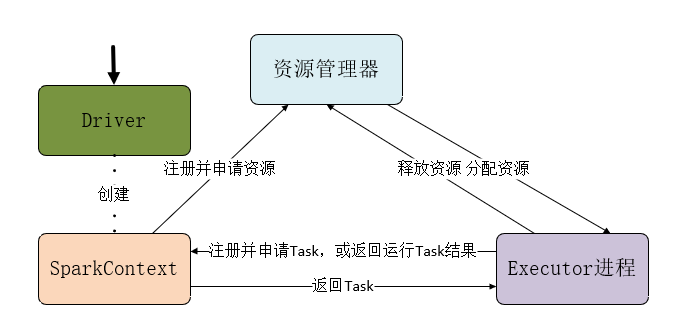
1、Driver创建SparkContext对象
2、SparkContext向资源管理器申请资源
3、资源管理器为Executor进程分配资源,并启动Executor进程
4、Executor进程向SparkContext申请Task
5、SparkContext根据RDD依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理,TaskScheduler向Executor返回Task
6、Executor运行Task,并向TaskScheduler和DAGScheduler返回运行结果
7、写入数据,释放资源