pd.concat(objs, axis=0, join=‘outer‘,
join_axes=None, ignore_index=False, keys=None, levels=None,
names=None, verify_integrity=False, sort=None, copy=True)
功能说明:
??多个dataframe或者series拼接到一起。指定方向(上下堆叠、左右拼接),指定合并方式(交集、并集)。
参数说明:
数据源:
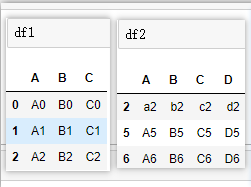
# ①基本连接:纵向合并,取交集
pd.concat([df1, df2])
# ②axis = 1,横向合并
pd.concat([df1,df2],axis=1)
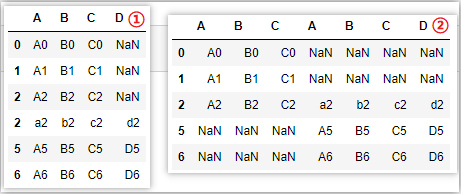
# ③join = ‘inner‘,取交集
pd.concat([df1,df2],join=‘inner‘)
pd.concat([df1,df2],join=‘inner‘,axis=1)
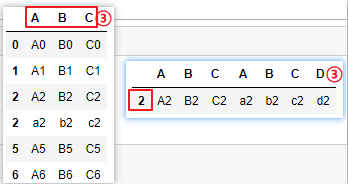
# ④join_axes=[df.index],根据需要保留的index进行合并
pd.concat([df1,df2],join_axes=[df1.columns])
pd.concat([df1,df2],axis=1,join_axes=[df2.index])
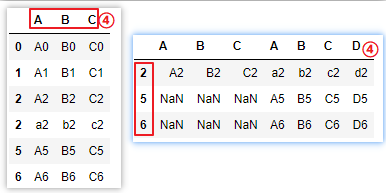
# ⑤ignore_index =True,丢弃原表索引,增加自然索引
pd.concat([df1,df2],ignore_index=True)
pd.concat([df1,df2],ignore_index=True,axis=1)
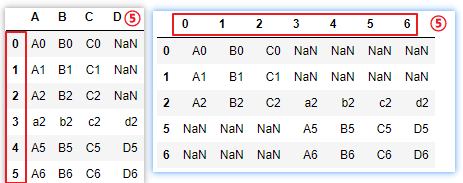
# ⑥keys = [‘df1‘,‘df2‘],names=[‘来源表‘,‘列号‘],在最外层添加一层索引,便于区分合并后的数据是哪个原表
pd.concat([df1,df2],keys=[‘df1‘,‘df2‘])
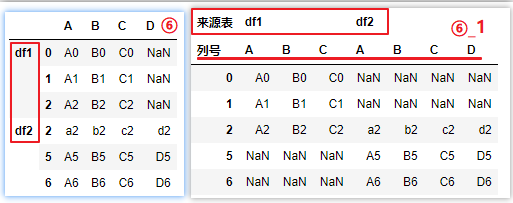
# ⑥_1
pd.concat([df1,df2],keys=[‘df1‘,‘df2‘],axis=1,names=[‘来源表‘,‘列号‘])
pd.merge(left, right, how=‘inner‘, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=(‘_x‘, ‘_y‘), copy=True, indicator=False, validate=None)
功能说明:
??具有全功能、高性能的内存连接操作,与 SQL 的方式很类似。只能用于两个表的拼接,通过参数名称也能看出连接方向是左右拼接,一个左表一个右表,而且参数中没有指定拼接轴的参数axis,不能用于表的上下拼接。
参数说明:
①单个键链接:
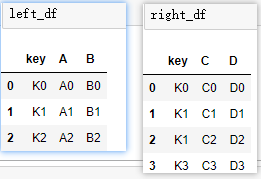
# ①最简单连接:默认内连接,未指定连接键,取公共列作为连接键
pd.merge(left_df,right_df)
# 等价,建议显示指定
pd.merge(left_df,right_df,on=‘key‘)
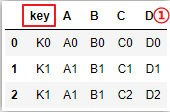
②多个键链接:
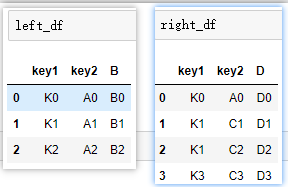
# 不显示指定连接键,默认会以[‘key1‘,‘key2‘]作为链接键
pd.merge(left_df,right_df)
# 等价于(所以建议显示指定)
pd.merge(left_df,right_df,on=[‘key1‘,‘key2‘])
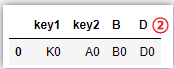
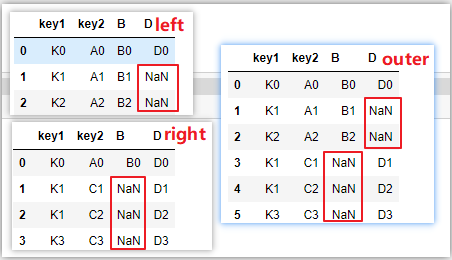
# how=‘left‘,以左表为基表,右表无匹配为NaN
pd.merge(left_df,right_df,how=‘left‘,on=[‘key1‘,‘key2‘])
# how=‘right‘,以右表为基表,左表无匹配为NaN
pd.merge(left_df,right_df,how=‘right‘,on=[‘key1‘,‘key2‘])
# how=‘outer’,外连接,取交集
# 等价于左连接和右连接的并集(叠加)
pd.merge(left_df,right_df,how=‘outer‘,on=[‘key1‘,‘key2‘])
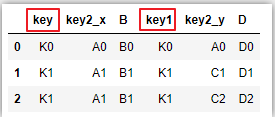
③字段不相同指定连接键:
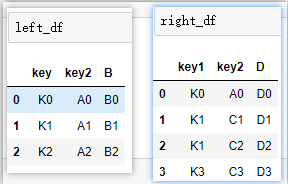
# left_on,right_on指定链接键,重复列会被标记区分
pd.merge(left_df,right_df,left_on=‘key‘,right_on=‘key1‘)
原文:https://www.cnblogs.com/xiaoshun-mjj/p/14854644.html