大家好,我是辰哥。
爬虫采集下来的数据除了存储在文本文件、excel之外,还可以存储在数据集,如:Mysql,redis,mongodb等,今天辰哥就来教大家如何使用Python连接Mysql,并结合爬虫为大家讲解。
前提:这里默认大家已经安装好mysql。
mysql是关系型数据库,支持大型的数据库,可以处理拥有上千万条记录的大型数据库。通过爬虫采集的数据集存储到mysql后,可以借助mysql的关联查询将相关的数据一步取出。具体的作用这里就不赘述了,下面开始进入实际操作。
通过下面这个命令进行安装
pip install pymysqlpymysql库:Python3链接mysql
备注:
ps:MYSQLdb只适用于python2.x
python3不支持MYSQLdb,取而代之的是pymysql
运行会报:ImportError:No module named ‘MYSQLdb‘
import?pymysql?as?pmqlocalhost是本机ip,这里用localhost表示是当前本机,否则将localhost改为对应的数据库ip。
root是数据库用户名,123456是数据库密码,python_chenge是数据库名。
图上的数据库python_chenge已经建立好(建好之后,才能用上面代码去连接),建好之后,当前是没有表的,现在开始用Python进行建表,插入、查询,修改,删除等操作(结合爬虫去讲解)
在存储之前,先通过python创建表,字段有四个(一个主键+电影名称,链接,评分)
# 创建 movie 表创建表movie,字段分别为(id ,title ,url ,rate ),CHARACTER SET utf8 COLLATE utf8_general_ci是字符串编码设置为utf8格式
id是主键primary key,int类型,AUTO_INCREMENT自增,非空not null
title,url 是字符串类型varchar(100),同样非空
评分rate 是带小数的数字,所以是float,同样非空
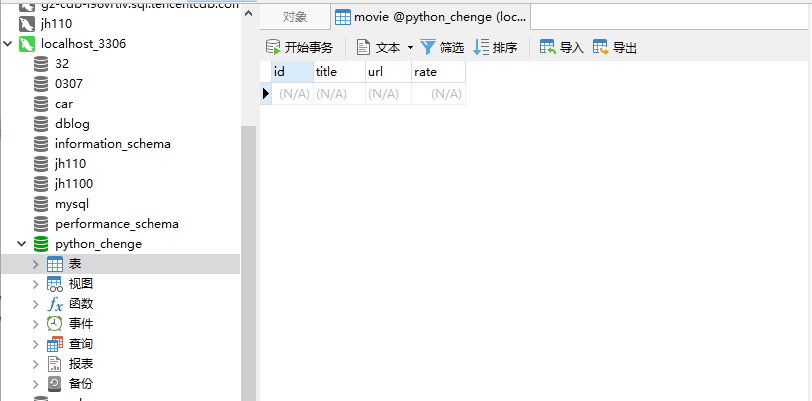
爬虫已经采集到数据,python已经建好表,接着可以将采集的数据插入到数据库,这里介绍两种方式
### 插入数据id是自增的,所以不需要在传值进去。
定义好插入数据库方法后,开始往数据库进行存储
for?i?in?json_data[‘subjects‘]: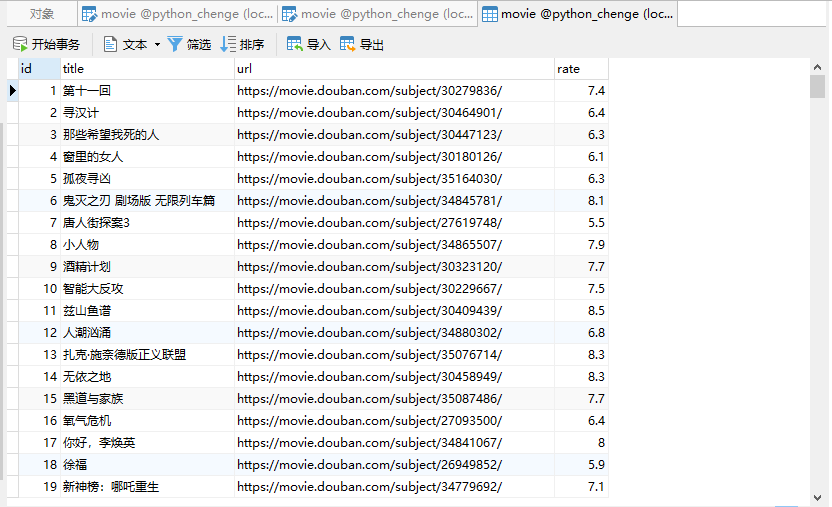
查询表中所有数据
# 查询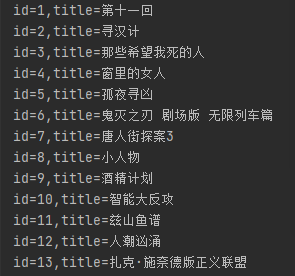
比如查询标题为:唐人街3这一条数据的所有字段
#查询单条
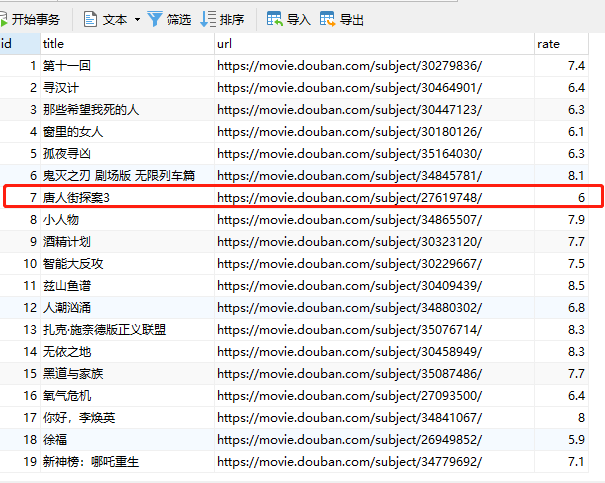
更新数据,还是以上面:唐人街3为例,id为7,将唐人街3评分从5.5改为6
### 更新
同时看一下数据库
同样还是以唐人街为例,其id为7,删除的话咱们可以更新id去删除
def delete(Id):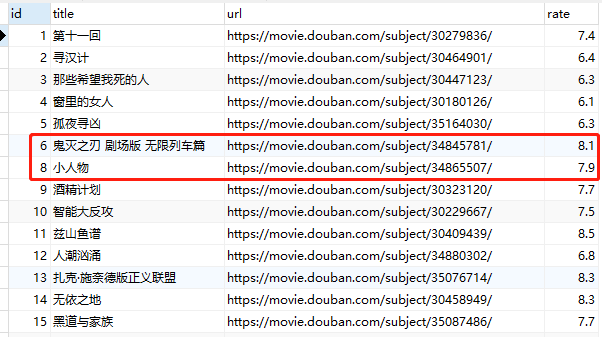
删除之后,就没有第7条数据了,说明删除成功
今天的技术讲解文章就到此结束,主要是将了如何通过python去连接mysql,并进行建表,插入数据,查询,更新修改和删除。(干货文章,推荐收藏)
原文:https://blog.51cto.com/u_11949039/2872562