利用Python中sklearn包进行逻辑回归分析。根据已有数据探究“学习时长”与“是否通过考试”之间关系,并建立预测模型。
# 1.导入包
import warnings
import pandas as pd
import numpy as np
from collections import OrderedDict
import matplotlib.pyplot as plt
warnings.filterwarnings(‘ignore‘)
# 2.创建数据(学习时间与是否通过考试)
dataDict={‘学习时间‘:list(np.arange(0.50,5.50,0.25)),
‘考试成绩‘:[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
dataOrDict=OrderedDict(dataDict)
dataDf=pd.DataFrame(dataOrDict)
# 查看数据具体形式
dataDf.head()
# 查看数据类型及缺失情况
dataDf.info()
# 查看描述性统计信息
dataDf.describe()
# 提取特征和标签
exam_X = dataDf[‘学习时间‘]
exam_y = dataDf[‘考试成绩‘]
# 绘制散点图
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
plt.scatter(exam_X, exam_y, color=‘b‘, label=‘考试数据‘)
plt.legend(loc=2)
plt.xlabel(‘学习时间‘)
plt.ylabel(‘考试成绩‘)
plt.show()
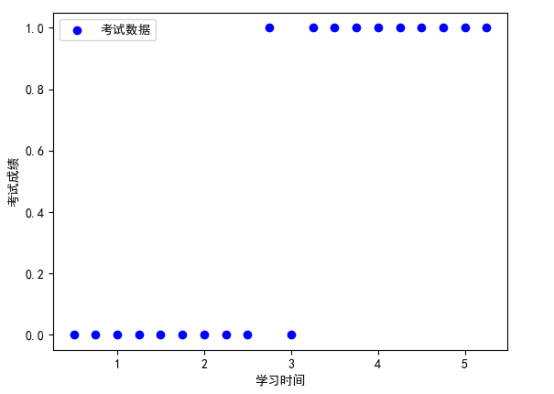
从图中可以看出当学习时间高于某一阈值时,一般都能够通过考试,因此我们利用逻辑回归方法建立模型。
(1)拆分训练集并利用散点图观察
# 1.拆分训练集和测试集
from sklearn.model_selection import train_test_split
exam_X = exam_X.values.reshape(-1, 1)
exam_y = exam_y.values.reshape(-1, 1)
train_X, test_X, train_y, test_y = train_test_split(exam_X, exam_y, train_size=0.8)
print(‘训练集数据大小为‘, train_X.size, train_y.size)
print(‘测试集数据大小为‘, test_X.size, test_y.size)
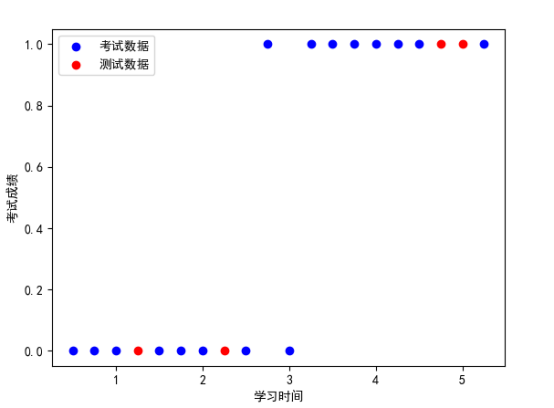
# 2.散点图观察
plt.scatter(train_X, train_y, color=‘b‘, label=‘考试数据‘)
plt.scatter(test_X, test_y, color=‘r‘, label=‘测试数据‘)
plt.legend(loc=2)
plt.xlabel(‘学习时间‘)
plt.ylabel(‘考试成绩‘)
plt.show()
(2)导入模型
# 3.导入模型
from sklearn.linear_model import LogisticRegression
modelLR = LogisticRegression()
(3)训练模型
# 4.训练模型
modelLR.fit(train_X,train_y)
1、模型评分(即准确率)
modelLR.score(test_X,test_y)
>>>
0.75
2、指定某个点的预测情况
# 学习时间确定时,预测为0和1的概率分别为多少?
modelLR.predict_proba([[3]])
>>>
array([[0.53351574, 0.46648426]])
# 学习时间确定时,预测能否通过考试?
modelLR.predict([[3]])
>>>
array([0], dtype=int64)
3、求出逻辑回归函数并绘制曲线
逻辑回归函数
# 先求出回归函数y=a+bx,再代入逻辑函数中pred_y=1/(1+np.exp(-y))
b=modelLR.coef_
a=modelLR.intercept_
print(‘该模型对应的回归函数为:1/(1+exp-(%f+%f*x))‘%(a,b))
>>>
该模型对应的回归函数为:1/(1+exp-(-4.891204+1.585647*x))
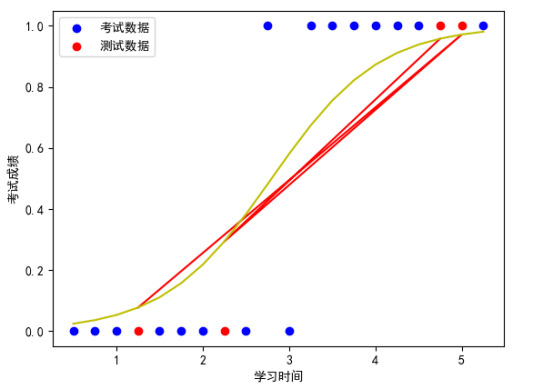
逻辑回归曲线
# 画出相应的逻辑回归曲线
plt.scatter(train_X,train_y,color=‘b‘,label=‘考试数据‘)
plt.scatter(test_X,test_y,color=‘r‘,label=‘测试数据‘)
plt.plot(test_X,1/(1+np.exp(-(a+b*test_X))),color=‘r‘)
plt.plot(exam_X,1/(1+np.exp(-(a+b*exam_X))),color=‘y‘)
plt.legend(loc=2)
plt.xlabel(‘学习时间‘)
plt.ylabel(‘考试成绩‘)plt.show()
# 预测训练数据
modelLR.predict(exam_X)
>>>
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
dtype=int64)
# 由预测结果可知学习时间大于3时,预测能否通过考试
from sklearn.metrics import accuracy_score, precision_score, recall_score
y_true = dataDf[‘考试成绩‘]
y_pred = modelLR.predict(exam_X)
# 准确率
accuracy_score(y_true, y_pred)
>>>
0.95
# 精确度
precision_score(y_true, y_pred)
>>>
1.0
# 召回率
recall_score(y_true, y_pred)
>>>
0.9
原文:https://www.cnblogs.com/linglijun/p/14874277.html