Elasticsearch是一个基于Apache Lucene全文搜索引擎开发的分布式的 RESTful 风格的的实时搜索与数据分析引擎,它比Lucene更强大,并且是开源的。官方网站:https://www.elastic.co/cn/
Elasticsearch是面向文档型数据库,一条数据就是一个文档,和数据结构mongoDB类似,文档序列化之后是JSON格式,例如一条用户数据:
{
"name":"tino",
"age":"25",
"department":"DC",
"hobies":[
"sports",
"music",
"movie"
]
}
相当于oracle/mysql数据库中的一张user表中的一条记录,这user表有name、age、department、hobies字段,而在Elasticsearch中,这是一个文档,而user则是整个文档的一个类型,Elasticsearch和关系型数据库术语的对照基本上是:
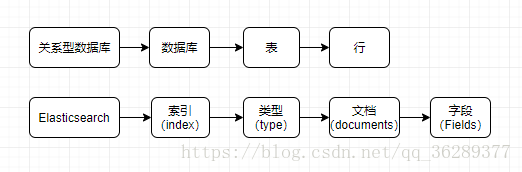
Elasticsearch 使用的是标准的 RESTful API 和 JSON,它的交互可以通过HTTP请求,也可以通过java API,如果插入一条记录,可以发送一个HTTP请求来实现:
POST /user/add
{
"name":"tino",
"age":"25",
"department":"DC",
"hobies":[
"sports",
"music",
"movie"
]
}
更新和查询也是类似的操作。
Elasticsearch最强大的就是为每个字段提供了倒排索引,当查询的时候不用担心没有索引可以利用,什么是倒排索引,举个简单例子:
|
文档ID |
年龄 |
性别 |
|
1 |
25 |
女 |
|
2 |
32 |
女 |
|
3 |
25 |
男 |
每一行是一个文档(document),每个document都有一个文档ID。那么给这些文档建立的倒排索引就是:
年龄的索引:
|
25 |
[1,3] |
|
32 |
[2] |
性别的索引:
|
女 |
[1,2] |
|
男 |
[3] |
可以看到,倒排索引是针对每个字段的,每个字段都有自己的倒排索引,25、32这些叫做term,[1,3]这种叫做posting list,
它是一个int的数组,存储了所有符合某个term的文档id,这时候我们想找出年龄为25的人,就会很快速,但是这里只有两个term,如果有成百上千个term呢,那找出某个term就会很慢,因为term还没有排序,解决这个问题需要了解两个概念:Term Dictionary 和 Term Index。
Elasticsearch为了能快速找到某个term,将所有的term进行了排序,然后二分法查找term,类似于上学时候老师教我们的翻新华字典的方式,所以这叫做Term Dictionary,这种查询方式其实和传统关系型数据库的B-Tree的方式很相似,所以这并不是Elasticsearch快的原因。
如果说Term Dictionary是直接去二分法翻字典,那么Term Index就是字典的目录页(当然这比我们真的去翻字典目录快多了),假设我们的term如果全是英文单词,那么Term Index就是26个字母表,但是通常term未必都是英文,而可以是任意的byte数组。因为就算26个英文字符也不一定都有对应的term,比如:a开头的term只有一个,c开头的term有一百万个,x开头的term一个也没有,这样查询到c的时候又会很慢了。所以通常情况下Term Index 是包含term的一些前缀的一棵树,例如这样的一个Term Index:
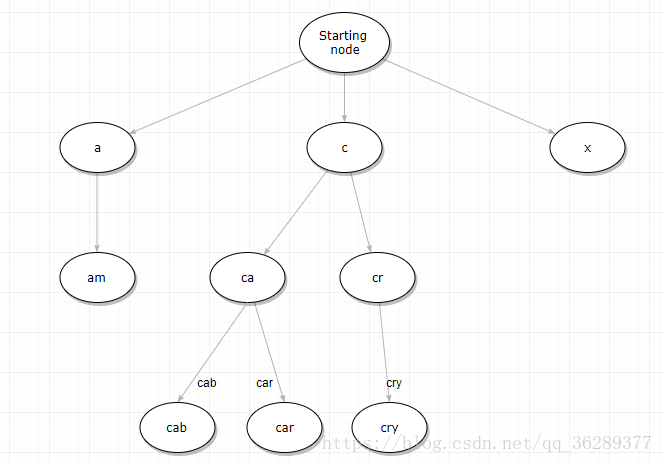
这样的情况下通过Term Index据可以快速定位到某个offset(分支的开端),然后以此位置向下查找,再加上FST(Finite-State Transducer,Lucene4.0开始使用该算法来查找Term 在Dictionary中的位置)的压缩技术,将Term Index 缓存到内存中,通过Term Index 找到对应的Term Dictionary的 block,然后再去磁盘直接找到term,减少磁盘的随机读写次数,大大的提升查询效率。(FST在下个章节单独介绍)
什么是bitmap?
postingList=[2,3,5,7,9] bitmap=[0,1,1,0,1,0,1,0,1,0]
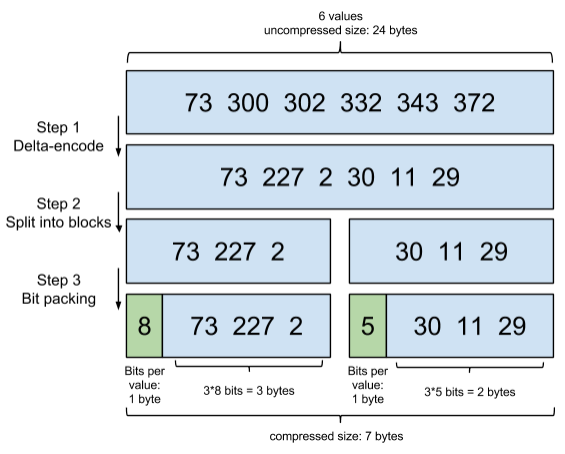
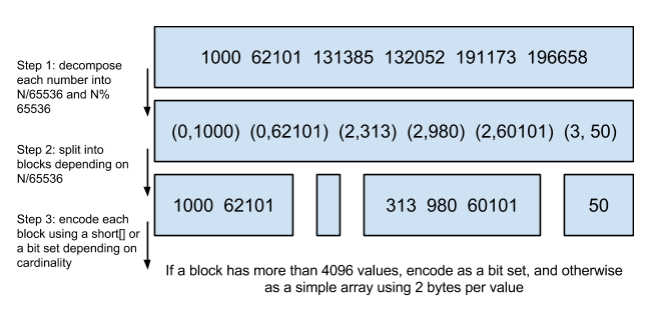
压缩技巧解读:
step1:从小到大进行排序。
step2:将大数除以65536,用除得的结果和余数来表示这个大数。
step3::以65535为界进行分块。
注意:如果一块超过了4096 个值,直接用bitset存,2个字节就用个简单的数组存放好了,比如short[],修正一下:1KB=1024B=1024byte=8192bit,每个值一个bytes,4096*2bytes = 8192bytes,刚好达到每一个block的界限 4096 = 65536 / 2 / 8
如何使用联合索引查询?
先了解跳表需要先知道跳表应该具有以下性质:
这是一个有序列链表:

从链表中搜索(27,44,61)需要查找的次数为:2+4+6 = 12次,可以得到所有结果,这样做其实没有用到链表的有序性,我们在查询44、66时候其实都做了一些重复查找,势必会造成效率低的问题,这时候可以用Skip List算法来优化查找次数,把某些节点提取出来,将链表分成两级:

这样我们在查找44和61的时候次数就得到了简化,因为列表时有序的,所以当我们查到27的时候,44的大概位置就知道了,查到44的时候,61的大概位置也就知道了,避免了一部分重复查查找,这时候我们找到所以结果的次数为2+3+4 = 9次,查询61的时候似乎又对44的查找重复了一次,似乎还有优化的空间,那我们再对二级链表再进行一次分级:
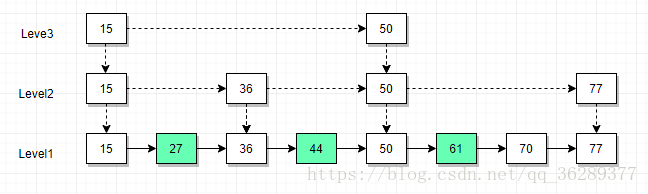
这时候可以看到我们查找61的时候只需要从15-50-61,三次就可以查找到结果,没有去走查找44时的36,所以现在查询次数得到了再次优化,也就是2+3+3 = 8次,有人说:就优化了一次查询,需要做得这么复杂吗,能有那么大的性能优势吗?的确,这里数据量很少,组合查询的索引也只有三个,看起来确实没有优势,但是当面对PB级数据的时候,链表的分级将无限扩大大,我们在查询结果时所"跳" 的跨度也会非常大,原先需要查找一百万次的结果,可能仅仅三次就查找到了,这个时候就会显得非常高效,从Skip List的查找原理可以看出,它的高效其实是牺牲了一定的空间冗余换来的,所以在有些情况下还是使用bitset更加的直观,比如下面这种数据结构:
| 111 | 222 | 333 | 444 | ||||
| 111 | 222 | 333 | 444 | 555 | 666 | 777 | |
| 111 | 222 | 333 | 444 | 555 | 666 | 777 | 888 |
如果使用跳表,查找第一行数据在另外两行中查找看是否存在,为了得到最后得到交集的结果,操作就要繁琐的多。
如果使用bitset直接进行压缩,按位与,得到的结果就是最后的交集。
转载自:Elasticsearch底层原理基本解析_Tino‘s Space-CSDN博客

原文:https://www.cnblogs.com/acestart/p/14884380.html