
pipeline = [$statge1, $stage2, ...$stageN];
db.<COLLECTION>.aggregate(
pipeline,
{ options }
);
| 步骤 | 作用 | SQL等价运算符 |
|---|---|---|
| $match | 过滤 | WHERE |
| $project | 投影 | AS |
| $sort | 排序 | ORDER BY |
| $group | 分组 | GROUP BY |
$skip/$limit |
结果限制 | SKIP/LIMIT |
| $lookup | 左外连接 | LEFT OUTER JOIN |
| $match | $project | $group |
|---|---|---|
$eq/$gt/$gte/$lt/$lte |
选择需要的或排除不需要的字段 | $sum/$avg |
$and/$or/$not/$in |
$map/$reduce/$filter |
$push/$addToSet |
$geoWithin/$intersect |
$range |
$first/$last/$max/$min |
$multiply/$divide/$substract/$add |
||
$year/$month/$dayOfMonth/$hour/$minute/$second |
| 步骤 | 作用 | SQL等价运算符 |
|---|---|---|
| $unwind | 展开数组 | N/A |
| $graphLookup | 图搜索 | N/A |
| N/A |
聚合查询可以用于OLAP和OLTP场景。例如:
| OLTP | OLAP |
|---|---|
| 计算 | 分析一段时间内的销售总额、均值 计算一段时间内的净利润 分析购买人的年龄分布 分析学生成绩分布 统计员工绩效 |
SELECT
FIRST_NAME AS `名`,
LAST_NAME AS `姓`,
FORM Users
WHERE GENDER = ‘男‘
SKIP 100
LIMIT 20
db.users.aggregate([
{$match: {gender: "男"}},
{$skip: 100},
{$limit: 20},
{$project: {
"名": $first_name,
"姓": $last_name
}}
]);
SELECT DEPARTMENT,
COUNT(NULL) AS EMP_QTY
FROM Users
WHERE GENDER = ‘女‘
GROUP BY DEPARTMENT HAVING
COUNT(*) < 10
db.users.aggregate([
{$match: {gender: ‘女‘}},
{$group: {
_id: $DEPARTMENT,
emp_qty: {$sum: 1}
}},
{$match: {$emp_qty: {$lt: 10}}}
]);
$unwind指定字段进行子文档展开,其他字段不动
> db.students.findOne()
{
name: "张三",
score: [
{subject: "语文", score: 84},
{subject: "数学", score: 90},
{subject: "外语", score: 69},
]
}
> db.students.aggregate([$unwind: $score])
{name: "张三", score: {subject: "语文", score: 84}}
{name: "张三", score: {subject: "数学", score: 90}}
{name: "张三", score: {subject: "外语", score: 69}}
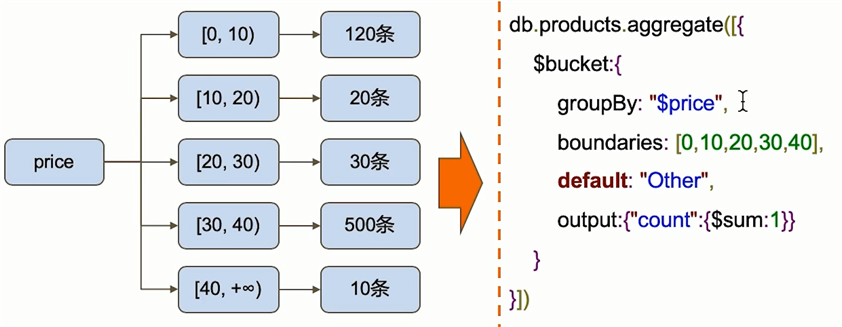
$bucket指定字段按指定区间进行分组统计
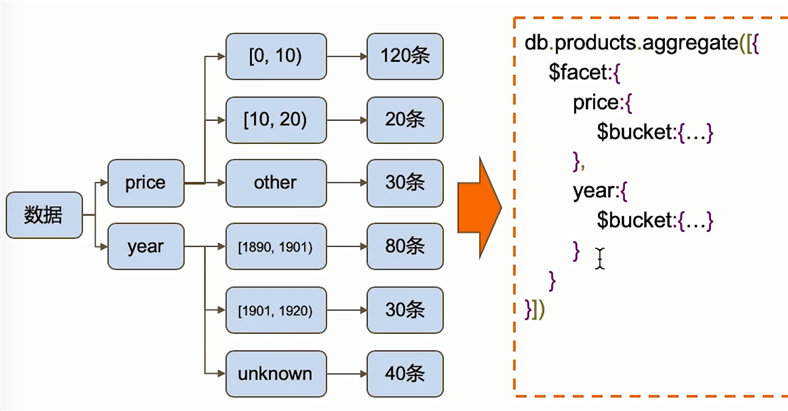
$facet指定多个字段分别$bucket分组统计
原文:https://www.cnblogs.com/niuben/p/14887485.html