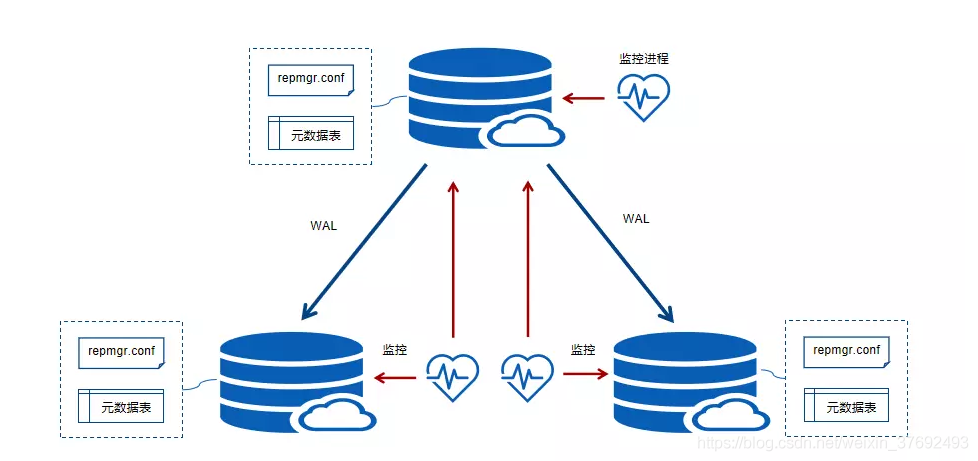
Repmgr流复制管理工具对集群节点的管理是基于一个分布式的管理方式。每个节点都有自己的repmgr.conf配置文件,用来记录本节点的ID,节点名称,连接信息,数据库KBDATA目录等配置参数。在配置好这些参数后,就可以通过repmgr命令实现对集群节点的“一键式”部署。
部署完成后,每个节点都有自己的repmgrd守护进程来监控节点数据库状态,且每个节点维护自己的元数据表,用于记录所有集群节点的信息。其中主节点守护进程主要用来监控本节点数据库服务状态,备节点守护进程主要用来监控主节点和本节点数据库服务状态。在发生Auto Failover时,备节点在尝试N次连接主节点失败后,repmgrd会在所有备节点中选举一个候选备节点提升为新主节点,然后其他备节点去Follow到该新主上,至此,形成一个新的集群状态。
如下图所示: repmgr集群架构原理图
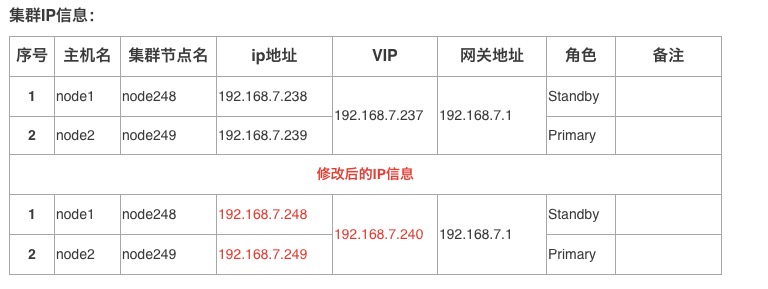
案例测试环境:
操作系统:
[kingbase@node1 bin]$ cat /etc/centos-release
CentOS Linux release 7.2.1511 (Core)
数据库环境:
[kingbase@node1 bin]$ ./ksql -U system test
ksql (V8.0)
Type "help" for help.
test=# select version();
version
-----------------------------------------------------------------------------------------------------------
KingbaseES V008R006C003B0010 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
(1 row)
操作步骤总结:
1、查看和确定主备库后,关闭集群(cluster和db)服务。
2、修改系统ip及/etc/hosts文件中ip。
3、修改集群主备库配置文件repmgr.conf中的物理ip和vip信息。
4、重启系统网络服务应用新的物理ip。
5、启动主备库数据库服务。
6、注册主库到集群。
7、关闭备库数据库服务,注册备库到集群并将备库节点重新加入到集群。
8、查看集群服务状态(cluster和db)并启动主备库repmgrd服务。
9、重启集群(sys_monitor.sh)服务验证。
一、查看集群主备库状态信息
1、节点状态信息
[kingbase@node1 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+---------------------------------------------------------------------------------------------------------------------------------------------------
1 | node248 | standby | running | node249 | default | 100 | 4 | host=192.168.7.238 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.239 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2、查看repmgr.conf配置文件信息(主备库)
[kingbase@node1 etc]$ cat repmgr.conf
on_bmj=off
node_id=1
node_name=‘node248‘
promote_command=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin/repmgr standby promote -f /home/kingbase/cluster/R6HA/KHA/kingbase/etc/repmgr.conf‘
follow_command=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin/repmgr standby follow -f /home/kingbase/cluster/R6HA/KHA/kingbase/etc/repmgr.conf -W --upstream-node-id=%n‘
conninfo=‘host=192.168.7.238 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3‘
log_file=‘/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log‘
data_directory=‘/home/kingbase/cluster/R6HA/KHA/kingbase/data‘
sys_bindir=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin‘
ssh_options=‘-q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -o ServerAliveInterval=2 -o ServerAliveCountMax=5 -p 22‘
reconnect_attempts=3
reconnect_interval=5
failover=‘automatic‘
recovery=‘manual‘
monitoring_history=‘no‘
trusted_servers=‘192.168.7.1‘
virtual_ip=‘192.168.7.237/24‘
net_device=‘enp0s3‘
ipaddr_path=‘/sbin‘
arping_path=‘/sbin‘
synchronous=‘quorum‘
repmgrd_pid_file=‘/home/kingbase/cluster/R6HA/KHA/kingbase/hamgrd.pid‘
ping_path=‘/usr/bin‘
3、查看系统 ip 信息
** 主库:**
[kingbase@node2 ~]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.7.238 node1
192.168.7.239 node2
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:48:34:53 brd ff:ff:ff:ff:ff:ff
inet 192.168.7.239/24 brd 192.168.7.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet 192.168.7.237/24 scope global secondary enp0s3:3
valid_lft forever preferred_lft forever
备库:
[kingbase@node1 bin]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.7.238 node1
192.168.7.239 node2
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:73:47:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.7.238/24 brd 192.168.7.255 scope global enp0s3
二、修改系统IP并应用新的物理IP
1、关闭集群(cluster和db)
[kingbase@node2 bin]$ ./sys_monitor.sh stop
2021-03-01 12:19:00 Ready to stop all DB ...
Service process "node_export" was killed at process 4629
Service process "postgres_ex" was killed at process 4630
Service process "node_export" was killed at process 9260
Service process "postgres_ex" was killed at process 9261
2021-03-01 12:19:07 begin to stop repmgrd on "[192.168.7.238]".
2021-03-01 12:19:08 repmgrd on "[192.168.7.238]" stop success.
2021-03-01 12:19:08 begin to stop repmgrd on "[192.168.7.239]".
2021-03-01 12:19:09 repmgrd on "[192.168.7.239]" stop success.
2021-03-01 12:19:09 begin to stop DB on "[192.168.7.238]".
waiting for server to shut down.... done
server stopped
2021-03-01 12:19:10 DB on "[192.168.7.238]" stop success.
2021-03-01 12:19:10 begin to stop DB on "[192.168.7.239]".
waiting for server to shut down.... done
server stopped
2021-03-01 12:19:11 DB on "[192.168.7.239]" stop success.
2021-03-01 12:19:11 Done.
2、修改系统IP
主备库修改:
[root@node2 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.7.248 node1
192.168.7.249 node2
主库:
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:48:34:53 brd ff:ff:ff:ff:ff:ff
inet 192.168.7.249/24 brd 192.168.7.255 scope global enp0s3
valid_lft forever preferred_lft forever
备库:
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:73:47:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.7.248/24 brd 192.168.7.255 scope global enp0s3
valid_lft forever preferred_lft forever
三、修改repmgr.conf配置文件(主备库所有node)
--- 修改配置文件中的节点的ip和vip
[kingbase@node1 etc]$ cat repmgr.conf
on_bmj=off
node_id=1
node_name=‘node248‘
promote_command=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin/repmgr standby promote -f /home/kingbase/cluster/R6HA/KHA/kingbase/etc/repmgr.conf‘
follow_command=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin/repmgr standby follow -f /home/kingbase/cluster/R6HA/KHA/kingbase/etc/repmgr.conf -W --upstream-node-id=%n‘
conninfo=‘host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3‘
log_file=‘/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log‘
data_directory=‘/home/kingbase/cluster/R6HA/KHA/kingbase/data‘
sys_bindir=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin‘
ssh_options=‘-q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -o ServerAliveInterval=2 -o ServerAliveCountMax=5 -p 22‘
reconnect_attempts=3
reconnect_interval=5
failover=‘automatic‘
recovery=‘manual‘
monitoring_history=‘no‘
trusted_servers=‘192.168.7.1‘
virtual_ip=‘192.168.7.240/24‘
net_device=‘enp0s3‘
ipaddr_path=‘/sbin‘
arping_path=‘/sbin‘
synchronous=‘quorum‘
repmgrd_pid_file=‘/home/kingbase/cluster/R6HA/KHA/kingbase/hamgrd.pid‘
ping_path=‘/usr/bin‘
[kingbase@node2 etc]$ cat repmgr.conf
on_bmj=off
node_id=2
node_name=node249
promote_command=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin/repmgr standby promote -f /home/kingbase/cluster/R6HA/KHA/kingbase/etc/repmgr.conf‘
follow_command=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin/repmgr standby follow -f /home/kingbase/cluster/R6HA/KHA/kingbase/etc/repmgr.conf -W --upstream-node-id=%n‘
conninfo=‘host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3‘
log_file=‘/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log‘
data_directory=‘/home/kingbase/cluster/R6HA/KHA/kingbase/data‘
sys_bindir=‘/home/kingbase/cluster/R6HA/KHA/kingbase/bin‘
ssh_options=‘-q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -o ServerAliveInterval=2 -o ServerAliveCountMax=5 -p 22‘
reconnect_attempts=3
reconnect_interval=5
failover=‘automatic‘
recovery=‘manual‘
monitoring_history=‘no‘
trusted_servers=‘192.168.7.1‘
virtual_ip=‘192.168.7.240/24‘
net_device=‘enp0s3‘
ipaddr_path=‘/sbin‘
arping_path=‘/sbin‘
synchronous=‘quorum‘
repmgrd_pid_file=‘/home/kingbase/cluster/R6HA/KHA/kingbase/hamgrd.pid‘
ping_path=‘/usr/bin‘
四、启动主备库数据库服务
[kingbase@node2 bin]$ ./sys_ctl start -D ../data
waiting for server to start....2021-03-01 12:06:25.776 CST [4661] LOG: sepapower extension initialized
2021-03-01 12:06:25.818 CST [4661] LOG: starting KingbaseES V008R006C003B0010 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
2021-03-01 12:06:25.818 CST [4661] LOG: listening on IPv4 address "0.0.0.0", port 54321
2021-03-01 12:06:25.818 CST [4661] LOG: listening on IPv6 address "::", port 54321
2021-03-01 12:06:25.905 CST [4661] LOG: listening on Unix socket "/tmp/.s.KINGBASE.54321"
.2021-03-01 12:06:26.425 CST [4661] LOG: redirecting log output to logging collector process
2021-03-01 12:06:26.425 CST [4661] HINT: Future log output will appear in directory "sys_log".
done
server started
五、注册主库到集群
1、注册primary到集群
[kingbase@node2 bin]$ ./repmgr primary register -F
INFO: connecting to primary database...
INFO: "repmgr" extension is already installed
NOTICE: PING 192.168.7.240 (192.168.7.240) 56(84) bytes of data.
--- 192.168.7.240 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1000ms
WARNING: ping host"192.168.7.240" failed
DETAIL: average RTT value is not greater than zero
NOTICE: node (ID: 2) acquire the virtual ip 192.168.7.240/24 success
NOTICE: primary node record (ID: 2) updated
2、查看集群节点状态
[`kingbase@node2 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+---------------+----------+----------+----------+-------
1 | node248 | standby | ? unreachable | node249 | default | 100 | ? | host=192.168.7.238 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected
- unable to connect to node "node248" (ID: 1)
- node "node248" (ID: 1) is registered as an active standby but is unreachable
六、注册备库到集群
1、直接注册备库到集群会出现无法连接的故障(需要关闭备库数据库服务)
[kingbase@node1 bin]$ ./repmgr standby register -h 192.168.7.249 -d esrep -U esrep -W -F
WARNING: following problems with command line parameters detected:
--no-wait will be ignored when executing STANDBY REGISTER
INFO: connecting to local node "node248" (ID: 1)
WARNING: database connection parameters not required when the standby to be registered is running
DETAIL: repmgr uses the "conninfo" parameter in "repmgr.conf" to connect to the standby
INFO: connecting to primary database
ERROR: connection to database failed
DETAIL:
could not connect to server: No route to host
Is the server running on host "192.168.7.239" and accepting
TCP/IP connections on port 54321?
DETAIL: attempted to connect using:
user=esrep connect_timeout=10 dbname=esrep host=192.168.7.239 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr
ERROR: connection to database failed
DETAIL:
could not connect to server: No route to host
Is the server running on host "192.168.7.238" and accepting
TCP/IP connections on port 54321?
DETAIL: attempted to connect using:
user=esrep connect_timeout=10 dbname=esrep host=192.168.7.238 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr
ERROR: unable to connect to the primary database
HINT: a primary node must be configured before registering a standby node
2、关闭备库数据库服务后将备库节点重新加入到集群
1)关闭数据库服务
[kingbase@node1 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down.... done
server stopped
2)注册standby到集群
[kingbase@node1 bin]$ ./repmgr standby register -h 192.168.7.249 -U esrep -d esrep -F
INFO: connecting to local node "node248" (ID: 1)
INFO: connecting to primary database
INFO: standby registration complete
NOTICE: standby node "node248" (ID: 1) successfully registered
3)将备库节点重新加入到集群
[kingbase@node1 bin]$ ./repmgr node rejoin -h 192.168.7.249 -U esrep -d esrep
INFO: timelines are same, this server is not ahead
DETAIL: local node lsn is 1/EEFF5AB0, rejoin target lsn is 1/EEFF7E78
NOTICE: setting node 1‘s upstream to node 2
WARNING: unable to ping "host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: begin to start server at 2021-03-01 12:18:21.290629
NOTICE: starting server using "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/sys_ctl -w -t 90 -D ‘/home/kingbase/cluster/R6HA/KHA/kingbase/data‘ -l /home/kingbase/cluster/R6HA/KHA/kingbase/bin/logfile start"
NOTICE: start server finish at 2021-03-01 12:18:21.906449
NOTICE: NODE REJOIN successful
DETAIL: node 1 is now attached to node 2
[kingbase@node1 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+
1 | node248 | standby | running | node249 | default | 100 | 4 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
3、主库查看集群状态和主备流复制状态
1)查看集群节点状态
[kingbase@node2 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+
1 | node248 | standby | running | node249 | default | 100 | 4 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2)查看主备流复制状态
test=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_st
art | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag
| replay_lag | sync_priority | sync_state | reply_time
------+----------+---------+------------------+---------------+-----------------+
4939 | 16384 | esrep | node248 | 192.168.7.248 | | 44492 | 2021-03-01 12:17:4
1.036448+08 | | streaming | 1/EEFF7FC0 | 1/EEFF7FC0 | 1/EEFF7FC0 | 1/EEFF7FC0 | |
| | 1 | quorum | 2021-03-01 12:20:49.634460+08
(1 row)
4、启动主备库repmgrd服务
[kingbase@node2 bin]$ ./repmgrd -d
[2021-03-01 12:32:27] [NOTICE] redirecting logging output to "/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log"
七、重启集群服务验证
1、通过sys_monitor.sh启动集群
[kingbase@node2 bin]$ ./sys_monitor.sh restart
2021-03-01 12:20:29 Ready to stop all DB ...
There is no service "node_export" running currently.
There is no service "postgres_ex" running currently.
There is no service "node_export" running currently.
There is no service "postgres_ex" running currently.
2021-03-01 12:20:34 begin to stop repmgrd on "[192.168.7.248]".
2021-03-01 12:20:35 repmgrd on "[192.168.7.248]" already stopped.
2021-03-01 12:20:35 begin to stop repmgrd on "[192.168.7.249]".
2021-03-01 12:20:36 repmgrd on "[192.168.7.249]" already stopped.
2021-03-01 12:20:36 begin to stop DB on "[192.168.7.248]".
waiting for server to shut down.... done
server stopped
2021-03-01 12:20:37 DB on "[192.168.7.248]" stop success.
2021-03-01 12:20:37 begin to stop DB on "[192.168.7.249]".
waiting for server to shut down..... done
server stopped
2021-03-01 12:20:39 DB on "[192.168.7.249]" stop success.
2021-03-01 12:20:39 Done.
2021-03-01 12:20:39 Ready to start all DB ...
2021-03-01 12:20:39 begin to start DB on "[192.168.7.249]".
waiting for server to start.... done
server started
2021-03-01 12:20:41 execute to start DB on "[192.168.7.249]" success, connect to check it.
2021-03-01 12:20:42 DB on "[192.168.7.249]" start success.
2021-03-01 12:20:42 Try to ping trusted_servers on host 192.168.7.248 ...
2021-03-01 12:20:45 Try to ping trusted_servers on host 192.168.7.249 ...
2021-03-01 12:20:47 begin to start DB on "[192.168.7.248]".
waiting for server to start.... done
server started
2021-03-01 12:20:49 execute to start DB on "[192.168.7.248]" success, connect to check it.
2021-03-01 12:20:50 DB on "[192.168.7.248]" start success.
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+
1 | node248 | standby | running | node249 | default | 100 | 4 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2021-03-01 12:20:50 The primary DB is started.
2021-03-01 12:20:55 Success to load virtual ip [192.168.7.240/24] on primary host [192.168.7.249].
2021-03-01 12:20:55 Try to ping vip on host 192.168.7.248 ...
2021-03-01 12:20:57 Try to ping vip on host 192.168.7.249 ...
2021-03-01 12:21:00 begin to start repmgrd on "[192.168.7.248]".
[2021-03-01 12:21:42] [NOTICE] using provided configuration file "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/../etc/repmgr.conf"
[2021-03-01 12:21:42] [NOTICE] redirecting logging output to "/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log"
2021-03-01 12:21:01 repmgrd on "[192.168.7.248]" start success.
2021-03-01 12:21:01 begin to start repmgrd on "[192.168.7.249]".
[2021-03-01 12:21:02] [NOTICE] using provided configuration file "/home/kingbase/cluster/R6HA/KHA/kingbase/bin/../etc/repmgr.conf"
[2021-03-01 12:21:02] [NOTICE] redirecting logging output to "/home/kingbase/cluster/R6HA/KHA/kingbase/hamgr.log"
2021-03-01 12:21:03 repmgrd on "[192.168.7.249]" start success.
ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
----+---------+---------+-----------+----------+---------+------+---------+--------------------
1 | node248 | standby | running | node249 | running | 5135 | no | 1 second(s) ago
2 | node249 | primary | * running | | running | 6723 | no | n/a
2021-03-01 12:21:10 Done.
2、查看集群节点状态
[kingbase@node2 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+--------
1 | node248 | standby | running | node249 | default | 100 | 4 | host=192.168.7.248 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node249 | primary | * running | | default | 100 | 4 | host=192.168.7.249 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
3、查看主备流复制状态
[kingbase@node2 bin]$ ./ksql -U system test
ksql (V8.0)
Type "help" for help.
test=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_st
art | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag
| replay_lag | sync_priority | sync_state | reply_time
------+----------+---------+------------------+---------------+-----------------+--------
6203 | 16384 | esrep | node248 | 192.168.7.248 | | 44499 | 2021-03-01 12:20:4
9.781155+08 | | streaming | 1/EEFF9090 | 1/EEFF9090 | 1/EEFF9090 | 1/EEFF9090 | |
| | 1 | quorum | 2021-03-01 12:22:02.817815+08
(1 row)
八、总结
集群物理IP和VIP修改成功,对于集群IP的修改需要停止集群服务(cluster和db),将影响业务的正常运行,所以在集群部署前需要做好IP的规划,避免在后期修改给业务正常运行带来影响。原文:https://www.cnblogs.com/tiany1224/p/14890749.html