原文链接:
https://data-flair.training/blogs/hadoop-reducer/
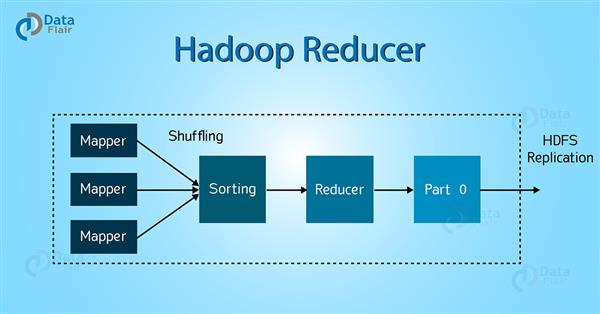
Reducer处理Mapper的输出,在处理完以后它会输出一些数据,这些输出会存储到HDFS上。
Reducer接收一个key-value对的集合作为输出,然后对集合中的每个kv对使用Reducer函数来处理。Reducer可以聚集,过滤,合并这些数据。Reducer首先处理mapper生成的中间数据然后生成输出(0或者多个kv对)。
key和Reducer是一对一的关系。多个Reducer可以并行执行,因为他们是相互独立的。Reducer的数量由用户指定,默认情况下Reducer的数量为1.
如上图所示,Reducer一共分成3个阶段。
这个阶段,mapper输出的已经排好序的数据将作为Reducer的输入。在Shuffle阶段,基于HTTP,框架会从所有的mapper中的相应的分区拉取数据(给Reducer)。
在这个阶段, 已经排好序mapper的输出数据会通过归并排序成一个大的文件(作为Reducer的输入)。shuffle和sort阶段是并发执行的。
这个阶段,在shuffle和sort之后,reduce任务会聚集kv对。OutputCollector.collect() method会将reduce的输出写入文件系统中。Reducer的输出结果不会排序。
这一个小节我们将讨论一个任务需要多少Reducer,以及如何修改Reducer的数量。
基于Job.setNumreduceTasks(int),用户可以设置一个job的Reducer的数量。合适的数量是这么计算出来的:0.95或1.75乘以 (<no. of nodes> * <no. of the maximum container per node>).
当是0.95是,所有Reducer会立刻启动,然后开始传输已经完成任务的mapper的数据。
With 0.95, all reducers immediately launch and start transferring map outputs as the maps finish.
当是1.75时,第一轮的Reducer会在快速的节点上执行,and second wave of reducers is launched doing a much better job of load balancing.
原文:https://www.cnblogs.com/ralgo/p/14890277.html