该数据是对砖石的一些属性进行可视化分析,共53940条数据,共10个字段,下面开始介绍个字段:

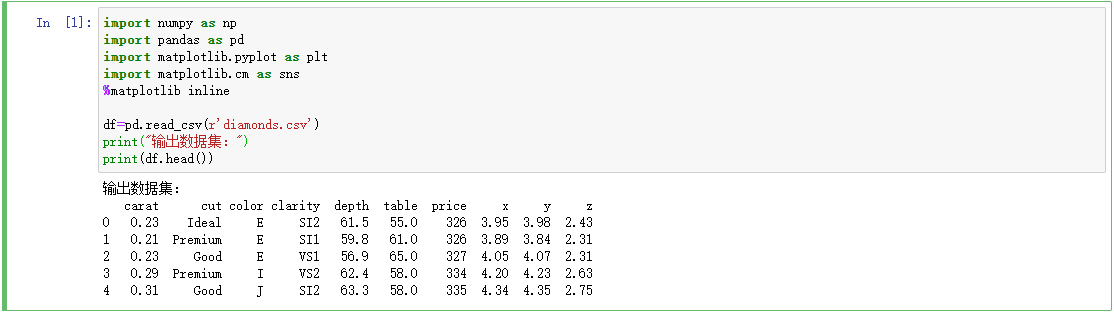
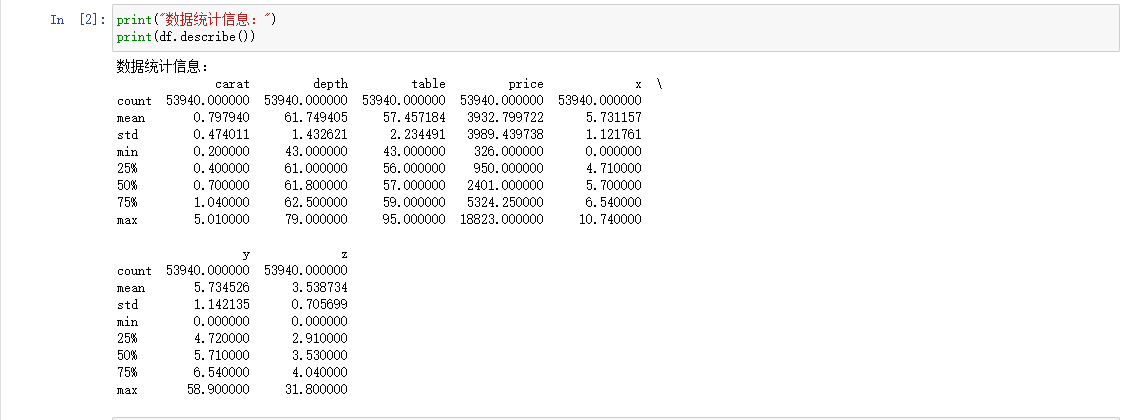
从统计信息可以看出数字型的总数、count,数据个数(非空数据),mean,均值,std,标准差,min,最小值,25%,第1四分位数,即第25百分位数,50%,第2四分位数,即第50百分位数,75%,第3四分位数,即第75百分位数,max,最大值等信息。
1.砖石的各个属性之间是否有关?
2.砖石的属性和砖石的数量是否有关系?
3.砖石的长、宽、深之间有关系吗?
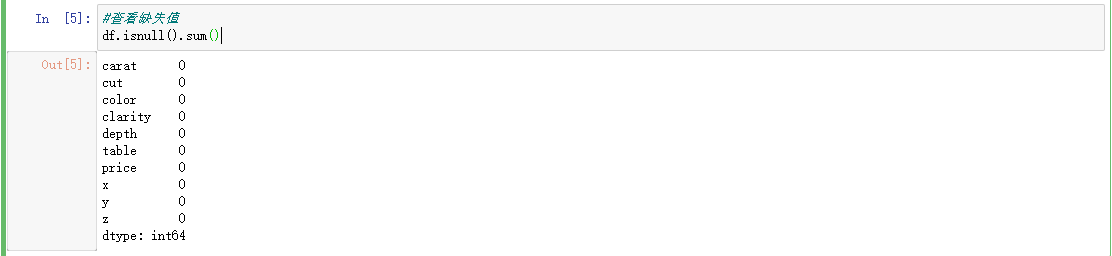
从数据集中,可以看到没有缺失值。
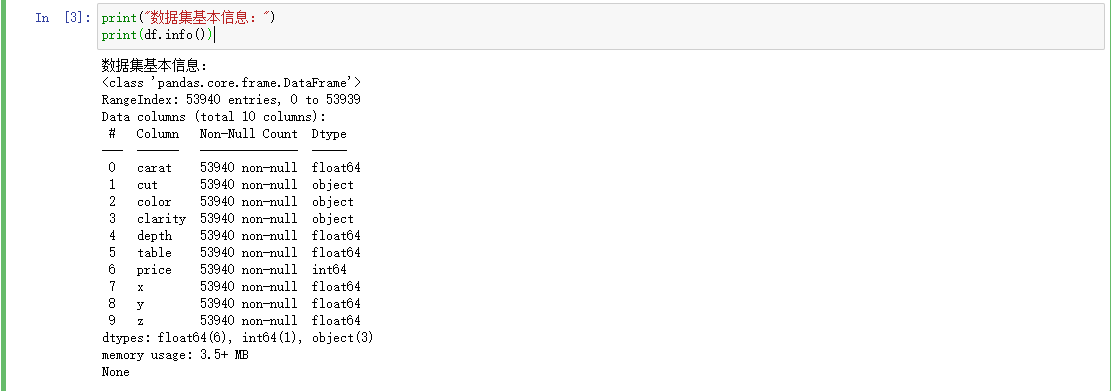
可以看到有三个属性是非数字型的,后面可以对其进行处理,把它转换为数字型。
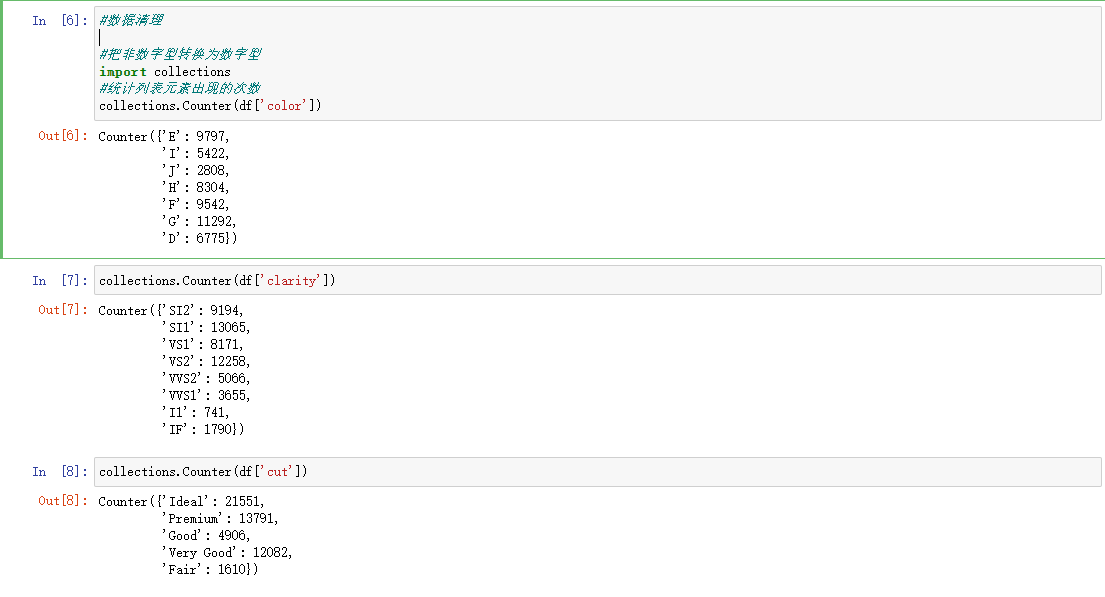

把缺失值删除。
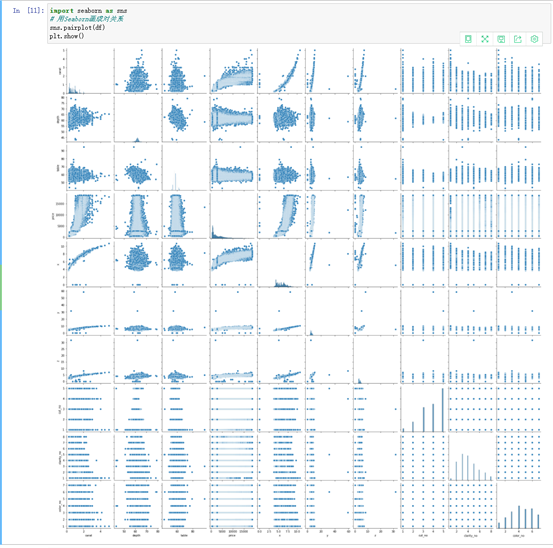
把数据放大,查看关系

从图中可以看出它们之间都有关系。
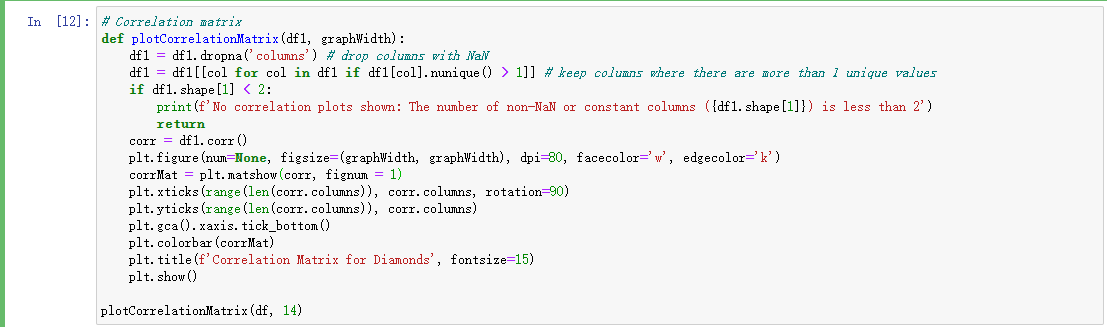
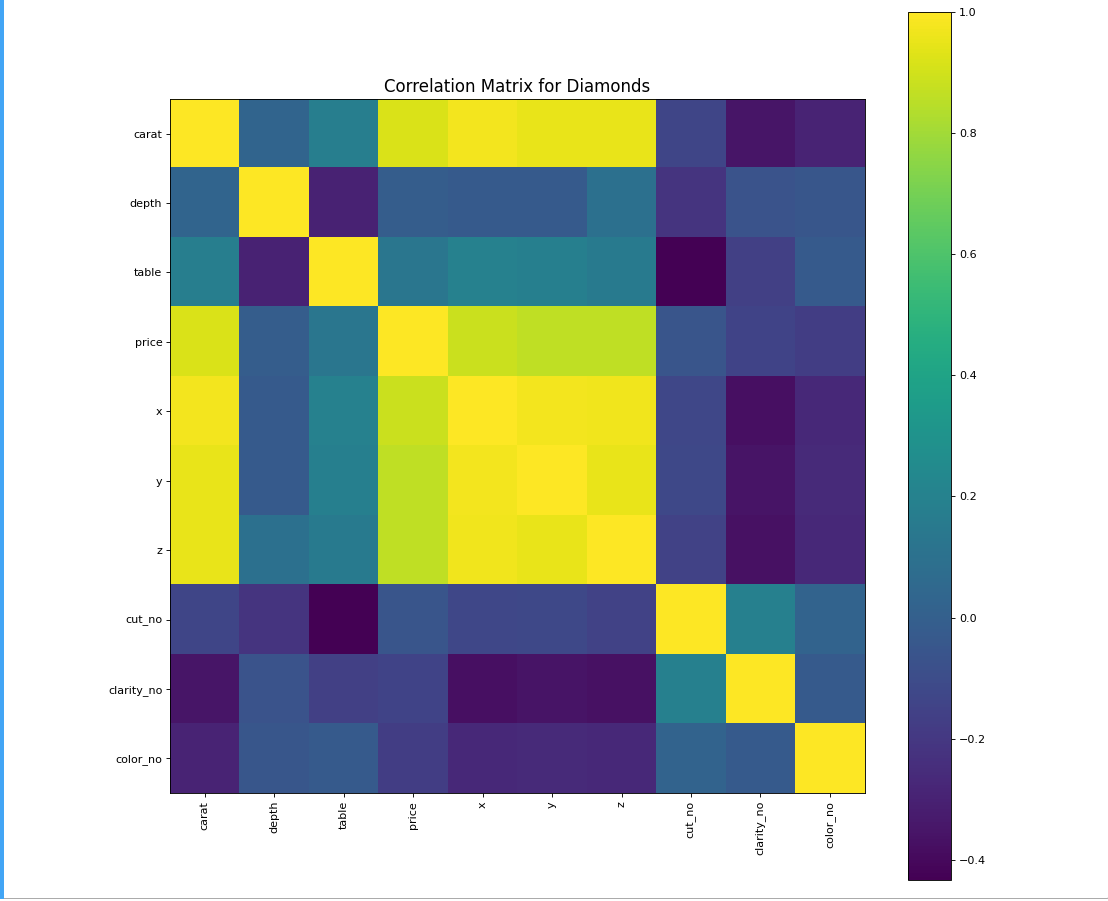
从图中可以看到,砖石的每个属性都存在较强的相关性。
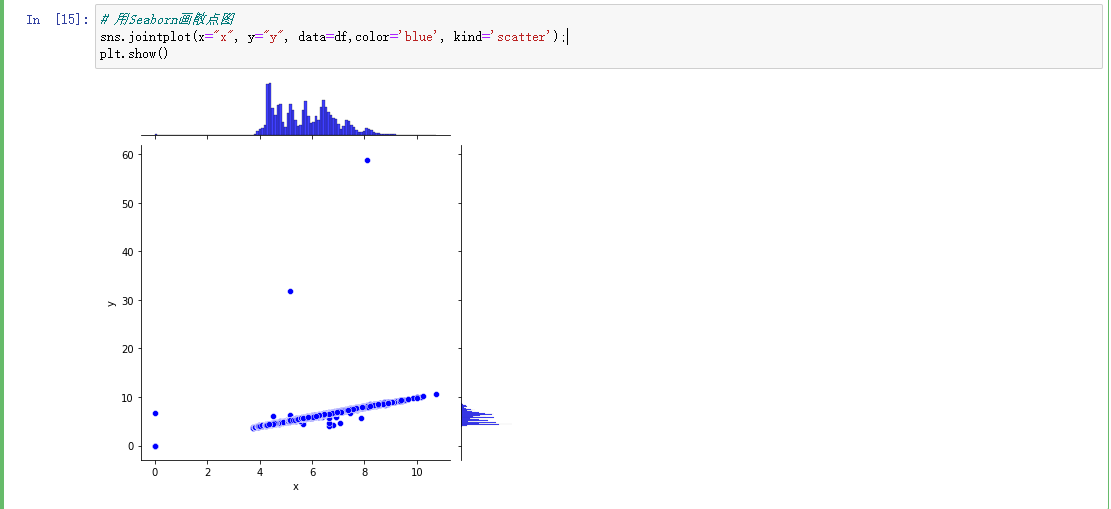
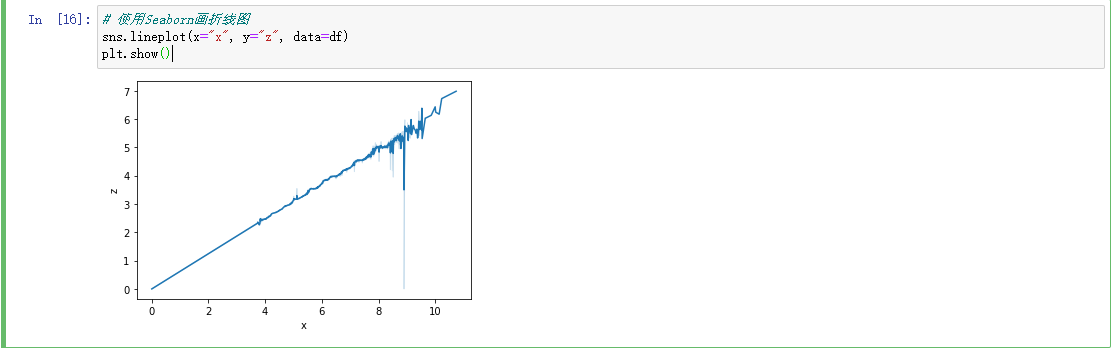
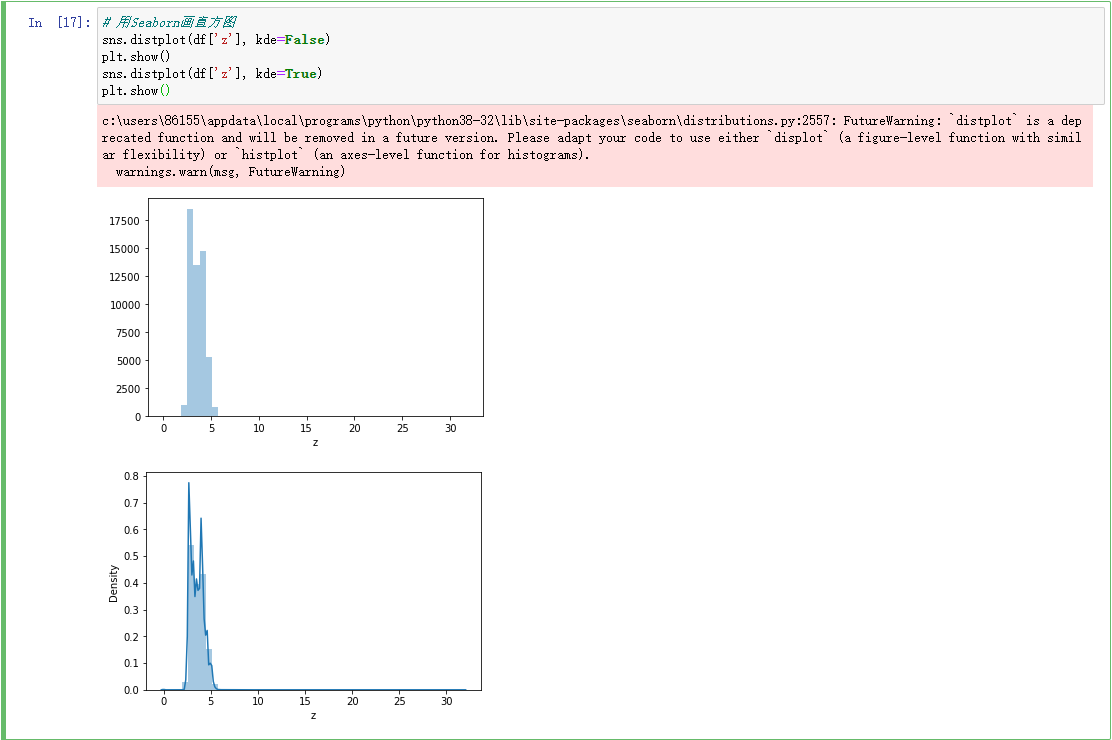
从图中看x,y,z的相关性还是很高的。
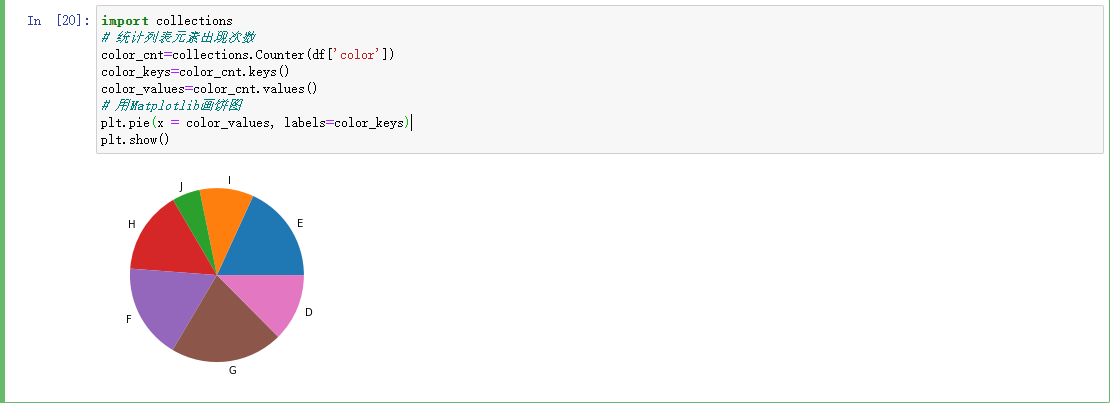
下面来做个饼图看看从色彩,切割等属性来看看不同品质的钻石数量占比:

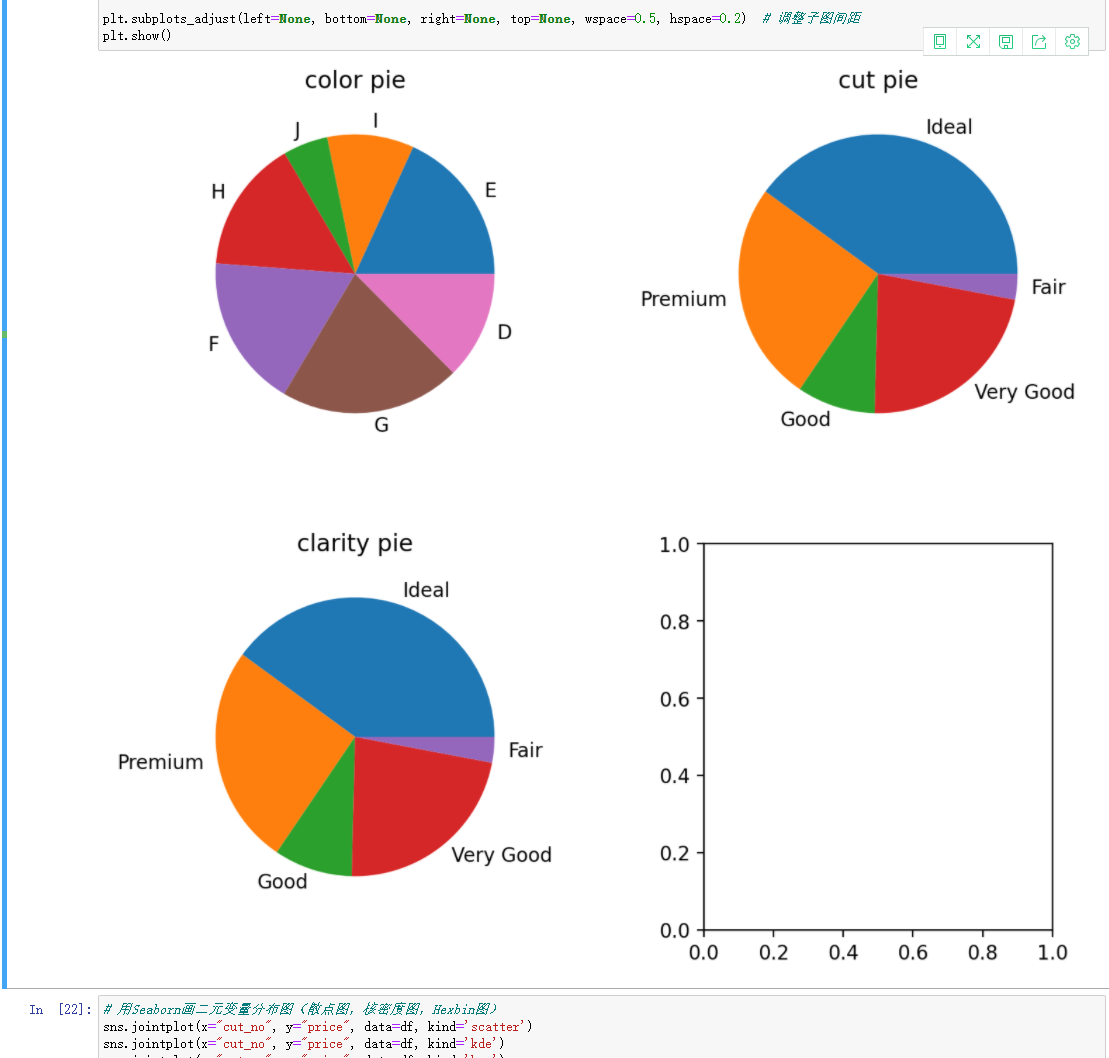
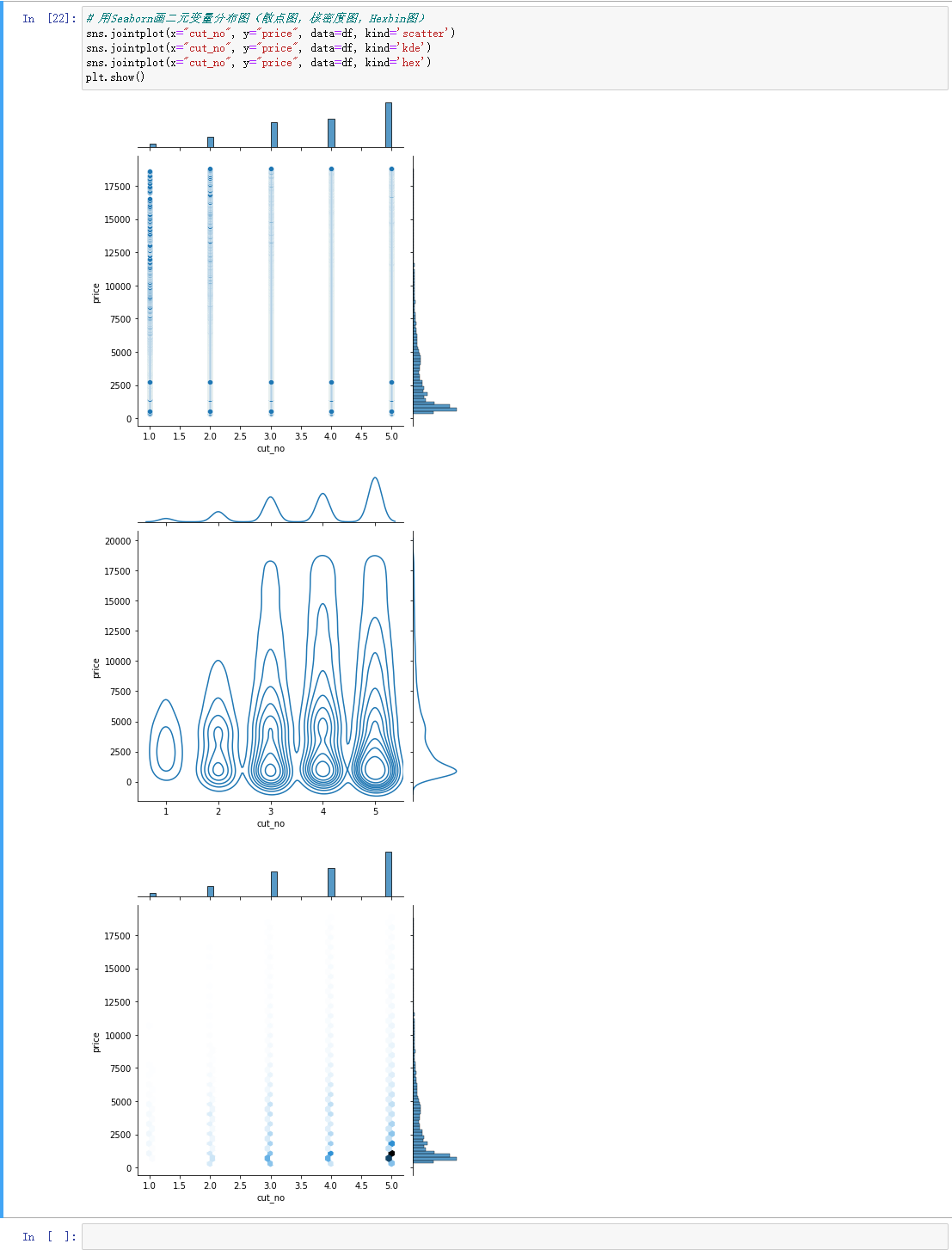
从图中可以看出,切割质量越好,价格越高。
使用箱线图查看数据是否存在异常值:
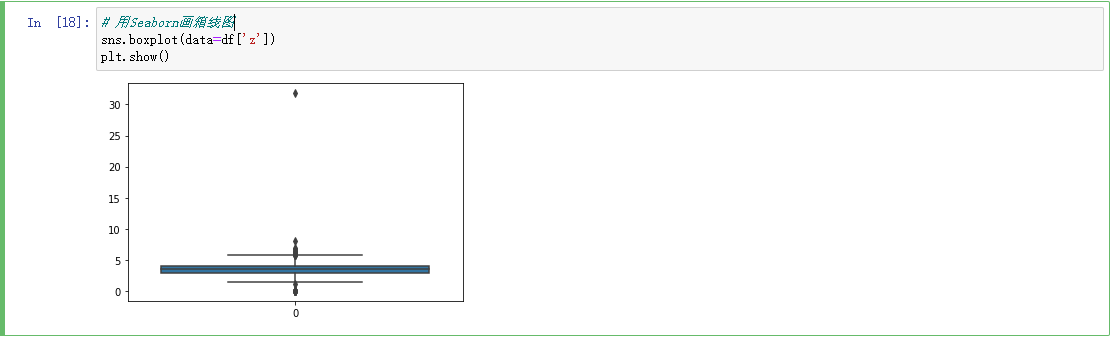
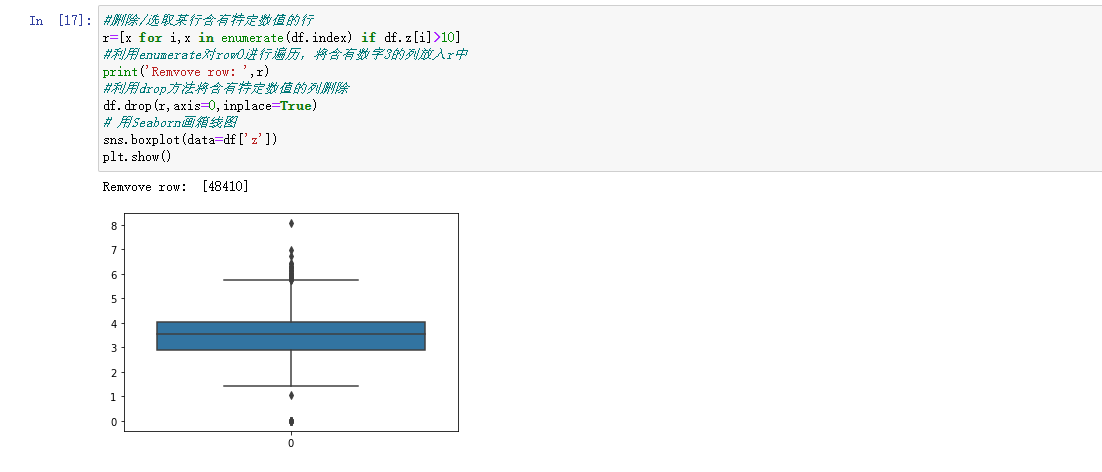
从图中可以看出,不存在明显的异常值。
1.从以上分析可以看出,各个属性之间的相关性很高
2.砖石的各个属性与砖石的数量有关系,砖石色彩越差或越小砖石数量就少,切割质量最差的,数量最少,净度最差的,数量也相对其它的要少。
3.砖石越长,宽度越低,深度越高
4.切割质量越好,砖石的价格越高
5.价格与砖石的长宽深有很强的相关性,而且基本都是正相关。
# coding: utf-8 # In[1]: import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.cm as sns get_ipython().run_line_magic(‘matplotlib‘, ‘inline‘) df=pd.read_csv(r‘diamonds.csv‘) print("输出数据集:") print(df.head()) # In[2]: print("数据统计信息:") print(df.describe()) # In[3]: print("数据集基本信息:") print(df.info()) # In[4]: #查看数据集 df.value_counts() # In[5]: #查看缺失值 df.isnull().sum() # In[6]: #数据清理 #把非数字型转换为数字型 import collections #统计列表元素出现的次数 collections.Counter(df[‘color‘]) # In[7]: collections.Counter(df[‘clarity‘]) # In[8]: collections.Counter(df[‘cut‘]) # In[9]: df[‘cut_no‘]=df[‘cut‘] df[‘clarity_no‘]=df[‘clarity‘] df[‘color_no‘]=df[‘color‘] # 准备好替换map cut_rp_map={‘Fair‘:1,‘Good‘:2,‘Very Good‘:3,‘Premium‘:4,‘Ideal‘:5} co_rp_map={‘J‘:1,‘I‘:2,‘H‘:3,‘G‘:4,‘F‘:5,‘E‘:6,‘D‘:7} cl_rp_map={‘I1‘: 1,‘SI2‘: 2,‘SI1‘: 3,‘VS2‘: 4,‘VS1‘: 5,‘VVS2‘: 6,‘VVS1‘: 7,‘IF‘: 8} # inplace 默认值是False,为True则替换原数据集,否则不替换原数据而是返回替换结果 df[‘cut_no‘].replace(cut_rp_map,inplace=True) df[‘clarity_no‘].replace(cl_rp_map,inplace=True) df[‘color_no‘].replace(co_rp_map,inplace=True) # In[14]: # 应用于原数据集 df.dropna(inplace=True) # 删除至少两个空值的行 df.dropna(thresh=2) # 删除所有值都是空的行 df.dropna(how=‘all‘) # 删除列 df.dropna(axis=‘columns‘) # In[13]: import seaborn as sns # 用Seaborn画成对关系 sns.pairplot(df) plt.show() # In[11]: # Correlation matrix def plotCorrelationMatrix(df1, graphWidth): df1 = df1.dropna(‘columns‘) # drop columns with NaN df1 = df1[[col for col in df1 if df1[col].nunique() > 1]] # keep columns where there are more than 1 unique values if df1.shape[1] < 2: print(f‘No correlation plots shown: The number of non-NaN or constant columns ({df1.shape[1]}) is less than 2‘) return corr = df1.corr() plt.figure(num=None, figsize=(graphWidth, graphWidth), dpi=80, facecolor=‘w‘, edgecolor=‘k‘) corrMat = plt.matshow(corr, fignum = 1) plt.xticks(range(len(corr.columns)), corr.columns, rotation=90) plt.yticks(range(len(corr.columns)), corr.columns) plt.gca().xaxis.tick_bottom() plt.colorbar(corrMat) plt.title(f‘Correlation Matrix for Diamonds‘, fontsize=15) plt.show() plotCorrelationMatrix(df, 14) # In[15]: # 用Seaborn画散点图 sns.jointplot(x="x", y="y", data=df,color=‘blue‘, kind=‘scatter‘); plt.show() # In[16]: # 使用Seaborn画折线图 sns.lineplot(x="x", y="z", data=df) plt.show() # In[17]: # 用Seaborn画直方图 sns.distplot(df[‘z‘], kde=False) plt.show() sns.distplot(df[‘z‘], kde=True) plt.show() # In[18]: # 用Seaborn画箱线图 sns.boxplot(data=df[‘z‘]) plt.show() # In[17]: #删除/选取某行含有特定数值的行 r=[x for i,x in enumerate(df.index) if df.z[i]>10] #利用enumerate对row0进行遍历,将含有数字3的列放入r中 print(‘Remvove row: ‘,r) #利用drop方法将含有特定数值的列删除 df.drop(r,axis=0,inplace=True) # 用Seaborn画箱线图 sns.boxplot(data=df[‘z‘]) plt.show() # In[19]: new_df=df[~df[‘z‘].isin([31.8])] #通过取反 print(new_df.z) # In[20]: import collections # 统计列表元素出现次数 color_cnt=collections.Counter(df[‘color‘]) color_keys=color_cnt.keys() color_values=color_cnt.values() # 用Matplotlib画饼图 plt.pie(x = color_values, labels=color_keys) plt.show() # In[21]: fig,axj=plt.subplots(nrows=2,ncols=2,figsize=(8, 8),dpi=200) #建立饼图坑 axes = axj.flatten() #子图展平 color_cnt=collections.Counter(df[‘color‘]) color_keys=[x for x in color_cnt.keys()] color_values=[x for x in color_cnt.values()] c_cnt=collections.Counter(df[‘cut‘]) c_keys=[x for x in c_cnt.keys()] c_values=[x for x in c_cnt.values()] cl_cnt=collections.Counter(df[‘clarity‘]) cl_keys=[x for x in c_cnt.keys()] cl_values=[x for x in c_cnt.values()] axes[0].set_title("color pie") axes[0].pie(x=color_values,labels=color_keys) axes[1].set_title("cut pie") axes[1].pie(x=c_values,labels=c_keys) axes[2].set_title("clarity pie") axes[2].pie(x=cl_values,labels=cl_keys) plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.5, hspace=0.2) # 调整子图间距 plt.show() # In[23]: # 用Seaborn画二元变量分布图(散点图,核密度图,Hexbin图) sns.jointplot(x="cut_no", y="price", data=df, kind=‘scatter‘) sns.jointplot(x="cut_no", y="price", data=df, kind=‘kde‘) sns.jointplot(x="cut_no", y="price", data=df, kind=‘hex‘) plt.show() # In[24]: # 使用Seaborn画折线图 sns.lineplot(x="cut_no", y="price", data=df) plt.show() # In[ ]:
原文:https://www.cnblogs.com/LJLHDH3/p/14897145.html