Apache Hudi提供了MVCC并发模型,保证写入端和读取端之间快照级别隔离。在本篇博客中我们将介绍如何配置来管理多个文件版本,此外还将讨论用户可使用的清理机制,以了解如何维护所需数量的旧文件版本,以使长时间运行的读取端不会失败。
Hudi 提供不同的表管理服务来管理数据湖上表的数据,其中一项服务称为Cleaner(清理服务)。 随着用户向表中写入更多数据,对于每次更新,Hudi会生成一个新版本的数据文件用于保存更新后的记录(COPY_ON_WRITE) 或将这些增量更新写入日志文件以避免重写更新版本的数据文件 (MERGE_ON_READ)。 在这种情况下,根据更新频率,文件版本数可能会无限增长,但如果不需要保留无限的历史记录,则必须有一个流程(服务)来回收旧版本的数据,这就是 Hudi 的清理服务。
在数据湖架构中,读取端和写入端同时访问同一张表是非常常见的场景。由于 Hudi 清理服务会定期回收较旧的文件版本,因此可能会出现长时间运行的查询访问到被清理服务回收的文件版本的情况,因此需要使用正确的配置来确保查询不会失败。
针对上述场景,我们先了解一下 Hudi 提供的不同清理策略以及需要配置的相应属性,Hudi提供了异步或同步清理两种方式。在详细介绍之前我们先解释一些基本概念:
<fileId>_<writeToken>_<instantTime>.parquet。在此文件的后续写入中文件 ID 保持不变,并且提交时间会更新以显示最新版本。这也意味着记录的任何特定版本,给定其分区路径,都可以使用文件 ID 和 instantTime进行唯一定位。Hudi 清理服务目前支持以下清理策略:
假设用户每 30 分钟将数据摄取到 COPY_ON_WRITE 类型的 Hudi 数据集,如下所示:
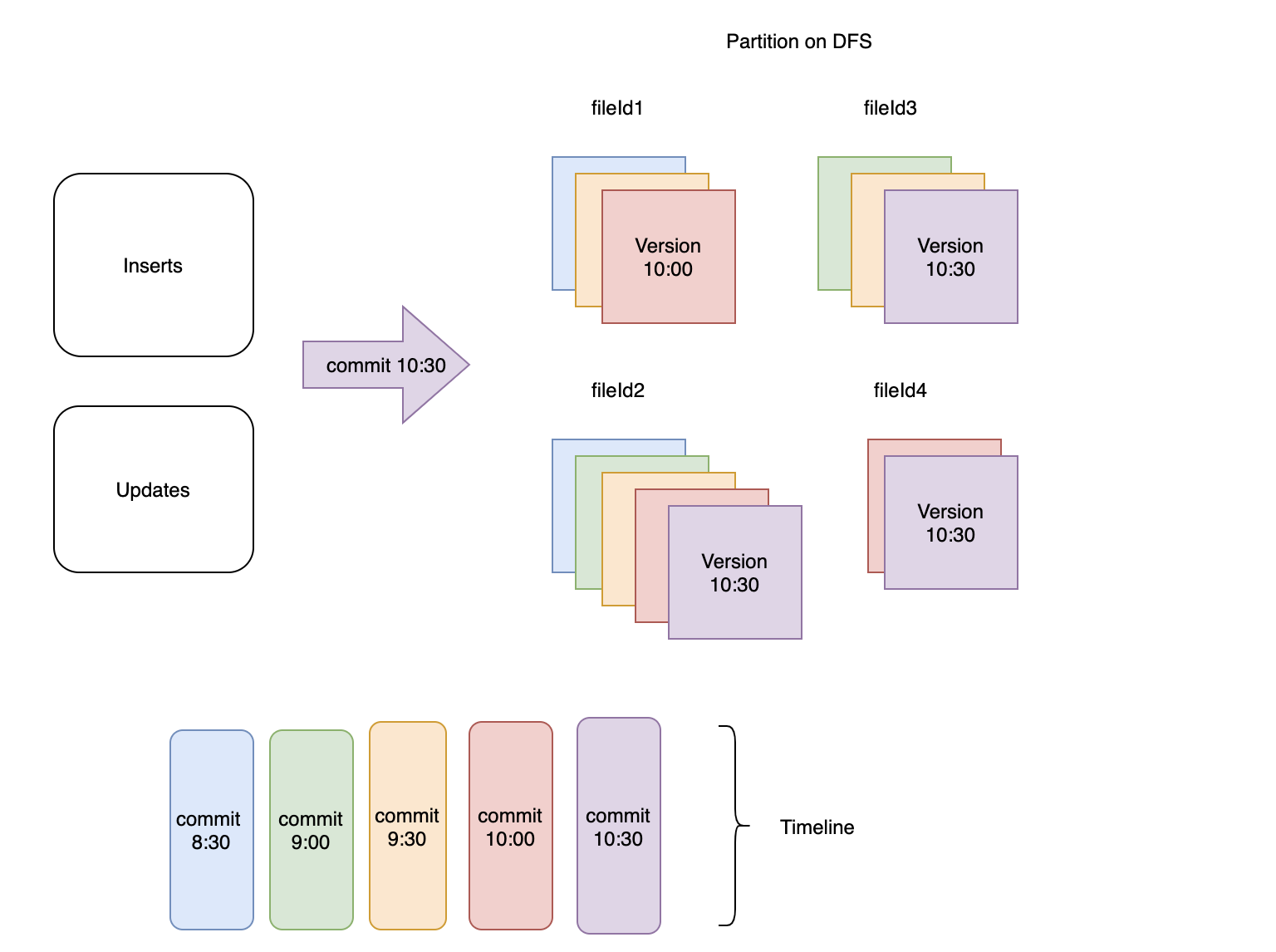
图1:每30分钟将传入的记录提取到hudi数据集中
该图显示了 DFS 上的一个特定分区,其中提交和相应的文件版本是彩色编码的。在该分区中创建了 4 个不同的文件组,如 fileId1、fileId2、fileId3 和 fileId4 所示。 fileId2 对应的文件组包含所有 5 次提交的记录,而 fileId4 对应的组仅包含最近 2 次提交的记录。
假设使用以下配置进行清理:
hoodie.cleaner.policy=KEEP_LATEST_COMMITS
hoodie.cleaner.commits.retained=2
Cleaner 通过处理以下事项来选择要清理的文件版本:
commit 10:30 和 commit 10:00 对应于时间线中最新的 2 个提交。包含一个额外的提交,因为保留提交的时间窗口本质上等于最长的查询运行时间。因此如果最长的查询需要 1 小时才能完成,并且每 30 分钟发生一次摄取,则您需要保留自 2*30 = 60(1 小时)以来的最后 2 次提交。此时最长的查询仍然可以使用以相反顺序在第 3 次提交中写入的文件。这意味着如果一个查询在 commit 9:30 之后开始执行,当在 commit 10:30 之后触发清理操作时,它仍然会运行,如图 2 所示。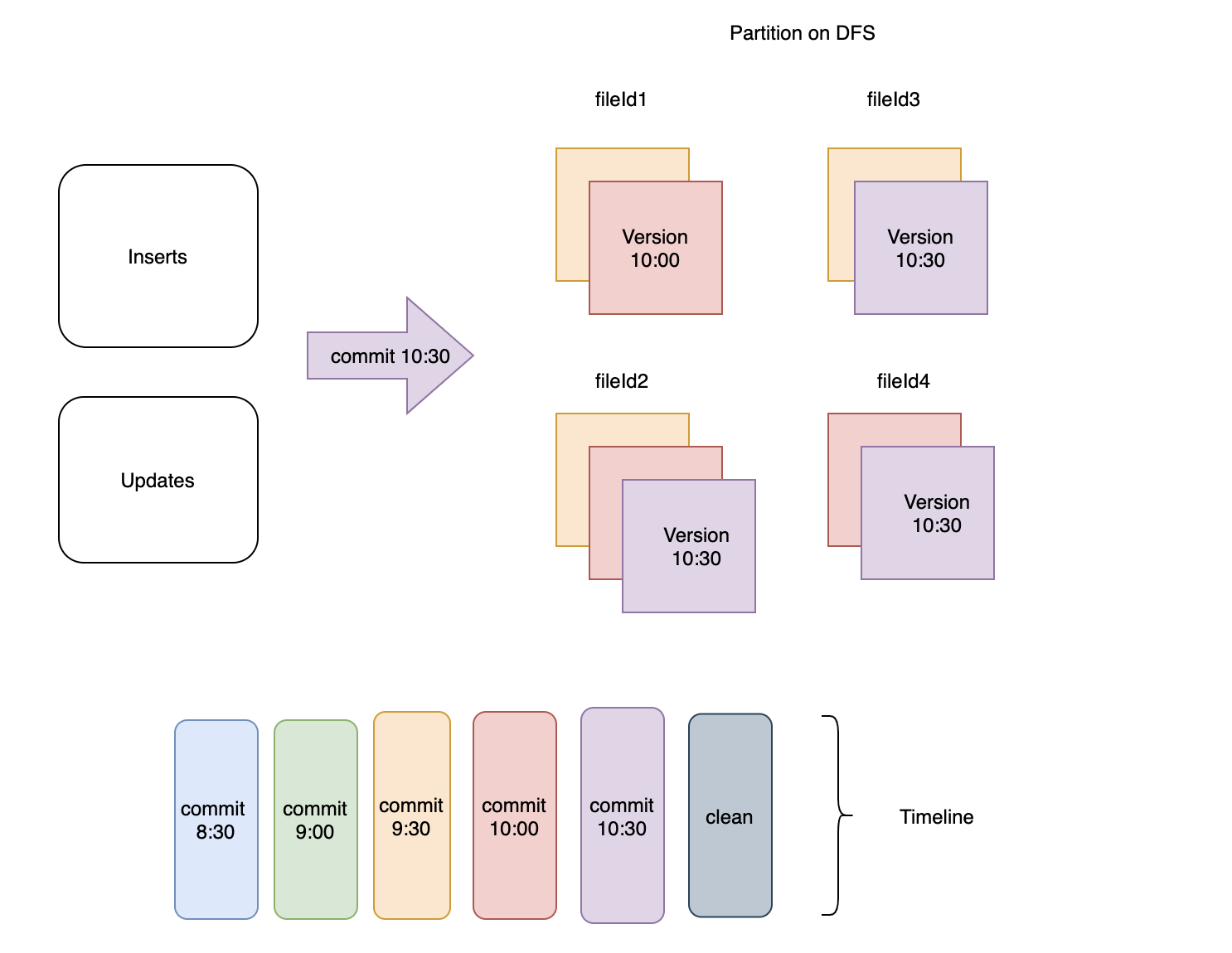
图2:保留最近3次提交对应的文件
假设使用以下配置进行清理:
hoodie.cleaner.policy=KEEP_LATEST_FILE_VERSIONS
hoodie.cleaner.fileversions.retained=1
清理服务执行以下操作:
commit 10:30 之后立即触发清理操作,清理服务将简单地保留每个文件组中的最新版本并删除其余的。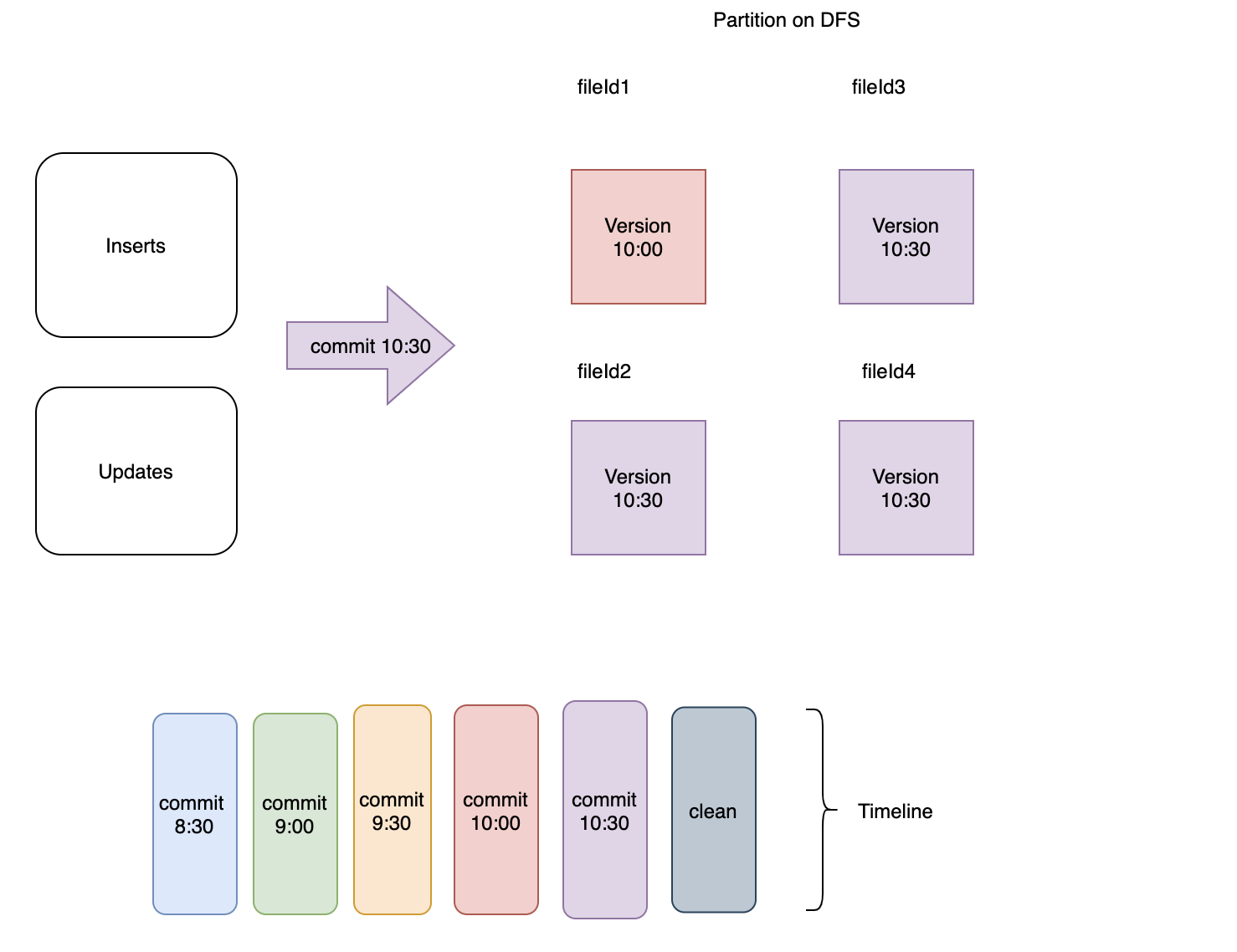
图3:保留每个文件组中的最新文件版本
可以在 此处 中找到有关所有可能配置的详细信息以及默认值。
Hudi 的清理表服务可以作为单独的进程运行,可以与数据摄取一起运行。正如前面提到的,它会清除了任何陈旧文件。如果您想将它与摄取数据一起运行,可以使用配置同步或异步运行。或者可以使用以下命令独立运行清理服务:
[hoodie]$ spark-submit --class org.apache.hudi.utilities.HoodieCleaner --props s3:///temp/hudi-ingestion-config/config.properties --target-base-path s3:///temp/hudi --spark-master yarn-cluster
如果您希望与写入异步运行清理服务,可以配置如下内容:
hoodie.clean.automatic=true
hoodie.clean.async=true
此外还可以使用 Hudi CLI 来管理 Hudi 数据集。CLI 为清理服务提供了以下命令:
cleans showclean showpartitionsclean run可以在 org.apache.hudi.cli.commands.CleansCommand 类 中找到这些命令的更多详细信息和相关代码。
目前正在进行根据已流逝的时间间隔引入新的清理策略,即无论摄取发生的频率如何,都可以保留想要的文件版本,可以在 此处 跟踪进度。
我们希望这篇博客能让您了解如何配置 Hudi 清理服务和支持的清理策略。请访问博客部分 以更深入地了解各种 Hudi 概念。
原文:https://www.cnblogs.com/leesf456/p/14897817.html