一、数据描述
1、数据字段及解释
2、导入数据
1 import pandas as pd 2 data = pd.read_csv(r‘Drug.csv‘) 3 data 4 data.describe()
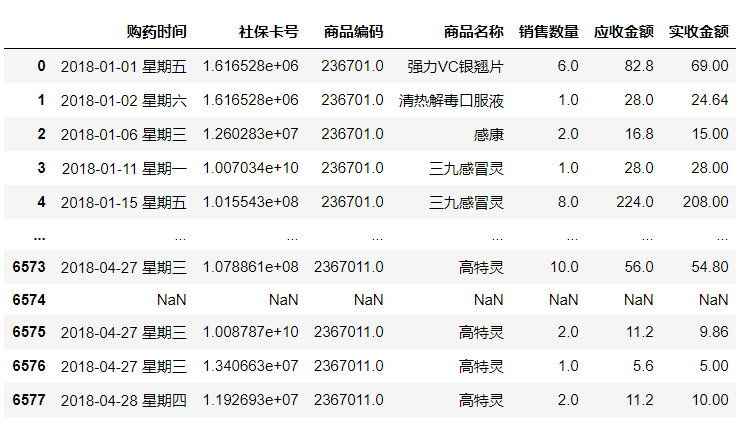
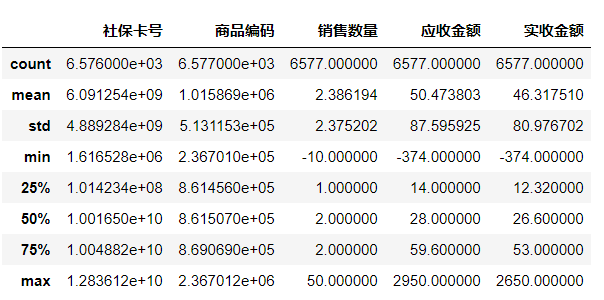
通过描述统计信息可以看到,“销售数量”、“应收金额”、“实收金额”这三列数据的最小值出现了负数,这明显不符合常理,数据中存在异常值的干扰,因此要对数据进一步处理,以排除异常值的影响:
1 pop = data.loc[:,‘销售数量‘] > 0 2 data = data.loc[pop,:] 3 data.describe()
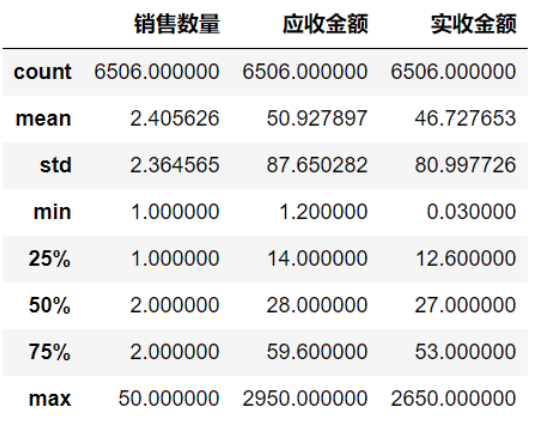
从数据输出结果可知,一共统计了6577份销售记录。其中,有2367钟商品,销售数量最大达到一次50份。
二、提出问题
1、药品的销售量是否与商品价格有关;
2、药品的销售量是否与药品的种类有关;
3、药品的销售数量是否与社保卡减少的价格有关;
三、数据清洗和预处理
1、查找缺失值
1 pd.isnull(data).sum()

2、处理缺失值
删除文件中的缺失值
1 data = data.dropna(subset=[‘销售时间‘,‘社保卡号‘], how=‘any‘) 2 data
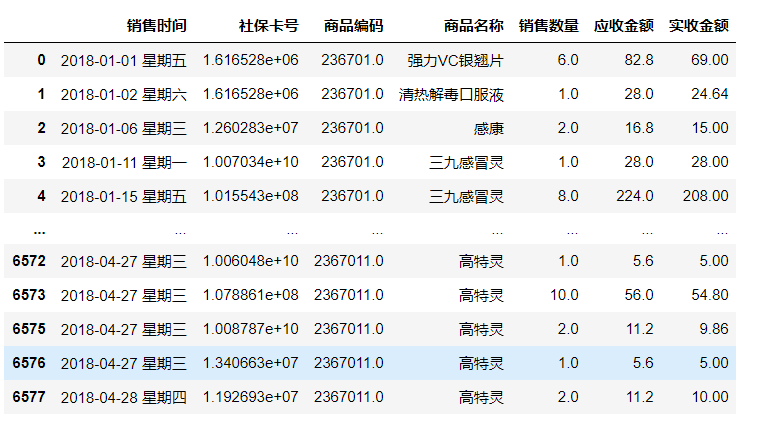
与初始表相比,明显6574行的数据被删除了。
3、进行数据清洗,将数据按时间排序
在“销售时间”这一列数据中存在星期这样的数据,但在数据分析过程中不需要用到,因此要把销售时间列中日期和星期使用split函数进行分割,分割后的时间,返回的是Series数据类型:
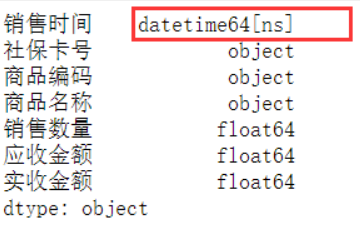
1 def splitSaletime(timeColSer): 2 timeList=[] 3 for value in timeColSer: 4 dateStr=value.split(‘ ‘)[0] #用空格进行分割 5 timeList.append(dateStr) 6 timeSer=pd.Series(timeList) #将列表转行为一维数据Series类型 7 return timeSer 8 #获取“销售时间”这一列 9 timeSer = data.loc[:,‘销售时间‘] 10 #对字符串进行分割,提取销售日期 11 dateSer = splitSaletime(timeSer) 12 #修改销售时间这一列的值 13 data.loc[:,‘销售时间‘] = dateSer 14 data.head() 15 data.loc[:,‘销售时间‘]=pd.to_datetime(data.loc[:,‘销售时间‘],format=‘%Y-%m-%d‘, errors=‘coerce‘) 16 print(data.dtypes)
1 data.isnull().sum()

此时时间是没有按顺序排列的,所以还是需要排序一下,排序之后索引会被打乱,所以也需要重置一下索引。
其中by:表示按哪一列进行排序,ascending=True表示升序排列,ascending=False表示降序排列
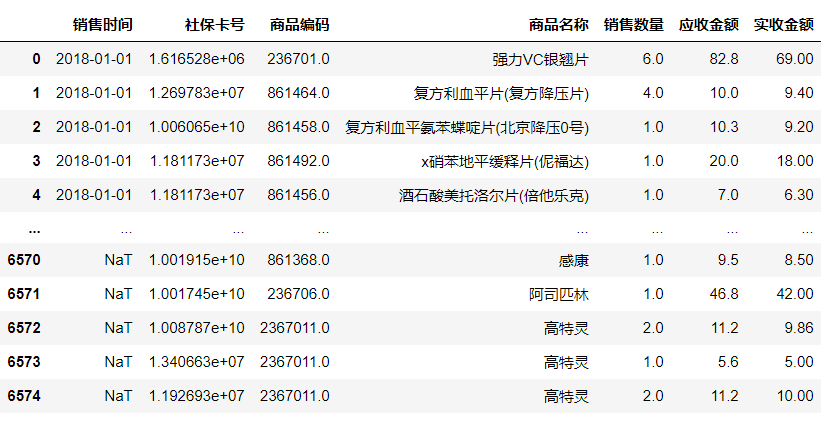
1 data = data.sort_values(by=‘销售时间‘, ascending=True) 2 data = data.reset_index(drop=True) 3 data
四、数据可视化
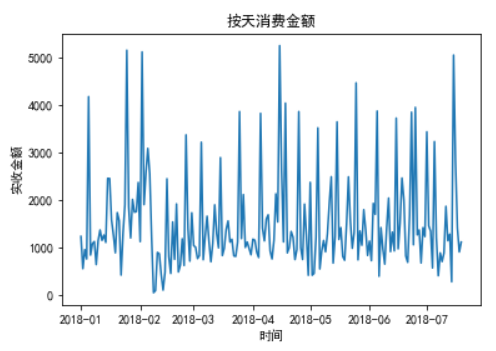
1、分析每天的消费金额
1 import matplotlib.pyplot as plt 2 import matplotlib 3 #画图时用于显示中文字符 4 from pylab import mpl 5 mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # SimHei是黑体的意思 6 #在操作之前先复制一份 7 #在操作之前先复制一份数据,防止影响清洗后的数据 8 groupDF = data 9 #将‘销售时间‘设置为index 10 groupDF.index = groupDF[‘销售时间‘] 11 print(groupDF.head()) 12 gb = groupDF.groupby(groupDF.index) 13 print(gb) 14 dayDF = gb.sum() 15 print(dayDF) 16 #画图 17 plt.plot(dayDF[‘实收金额‘]) 18 plt.title(‘按天消费金额‘) 19 plt.xlabel(‘时间‘) 20 plt.ylabel(‘实收金额‘) 21 plt.show()
2、分析每月的消费金额
1 #将销售时间聚合按月分组 2 gb = groupDF.groupby(groupDF.index.month) 3 print(gb) 4 monthDF = gb.sum() 5 print(monthDF) 6 plt.plot(monthDF[‘实收金额‘]) 7 plt.title(‘按月消费金额‘) 8 plt.xlabel(‘时间‘) 9 plt.ylabel(‘实收金额‘) 10 plt.show()
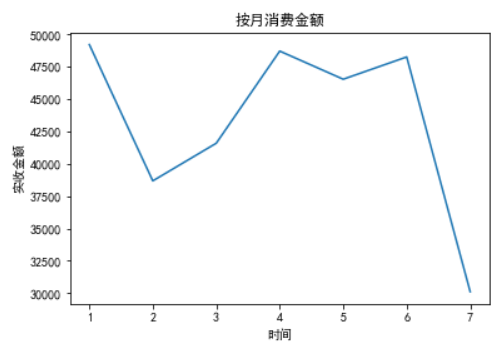
结果显示,7月消费金额最少,这是因为7月份的数据不完整,所以不具参考价值。
1月、4月、5月和6月的月消费金额差异不大.
2月和3月的消费金额迅速降低,这可能是2月和3月处于春节期间,大部分人都回家过年的原因。
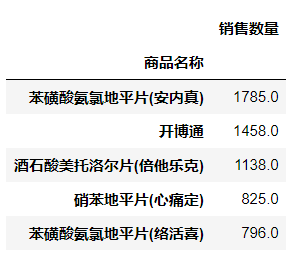
1 #聚合统计各种药品数量 2 medicine = groupDF[[‘商品名称‘,‘销售数量‘]] 3 bk = medicine.groupby(‘商品名称‘)[[‘销售数量‘]] 4 re_medicine = bk.sum() 5 #对销售药品数量按将序排序 6 re_medicine = re_medicine.sort_values(by=‘销售数量‘, ascending=False) 7 re_medicine.head()
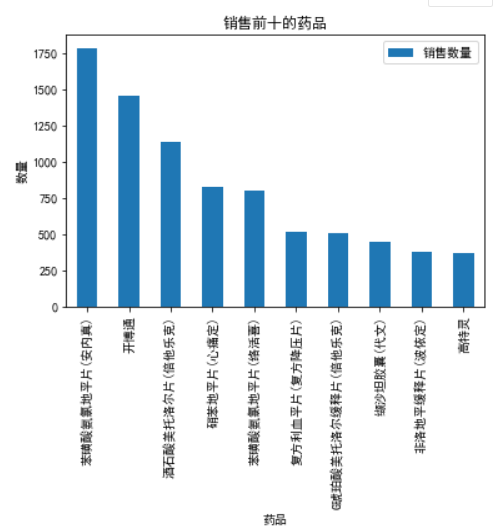
截取销售数量最多的前十种药品,并用条形图展示结果:
1 top_medicine = re_medicine.iloc[:10,:] 2 top_medicine 3 # 数据可视化,用条形图展示前十的药品 4 top_medicine.plot(kind = ‘bar‘) 5 plt.title(‘销售前十的药品‘) 6 plt.xlabel(‘药品‘) 7 plt.ylabel(‘数量‘) 8 plt.show()
每天的消费金额分布情况:一横轴为时间,纵轴为实收金额画散点图。
1 plt.scatter(data[‘销售时间‘],data[‘实收金额‘]) 2 plt.title(‘每天销售金额‘) 3 plt.xlabel(‘时间‘) 4 plt.ylabel(‘实收金额‘) 5 plt.show()
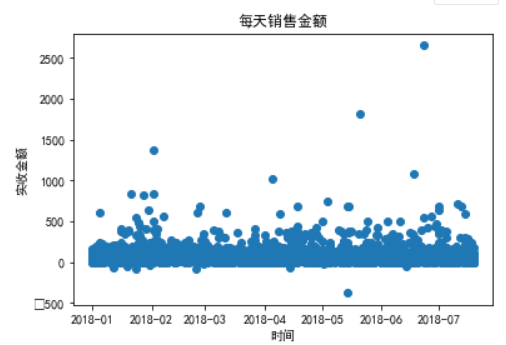
结论:从散点图可以看出,每天消费金额在500以下的占绝大多数,个别天存在消费金额很大的情况。
五、总结
对于销售量排在前几位的药品,医院应该时刻关注,保证药品不会短缺而影响患者。得到销售数量最多的前十种药品的信息,这些信息也会有助于加强医院对药房的管理。
从结果可以看出,每天消费总额差异较大,除了个别天出现比较大笔的消费,大部分人消费情况维持在1000-2000元以内。
原文:https://www.cnblogs.com/1762806175asd/p/14900996.html