需求: 将mysql表student的数据导入到hdfs的 /datax/mysql2hdfs/ 路径下面去。
1、创建mysql数据库和需要用到的表结构,并导入实战案例需要用到的数据
[hadoop@hadoop02 ~] mysql -uroot -p123456
mysql> create database datax;
mysql> use datax;
mysql> create table student(id int,name varchar(20),age int,createtime timestamp );
mysql> insert into `student` (`id`, `name`, `age`, `createtime`) values(‘1‘,‘zhangsan‘,‘18‘,‘2021-05-10 18:10:00‘);
mysql> insert into `student` (`id`, `name`, `age`, `createtime`) values(‘2‘,‘lisi‘,‘28‘,‘2021-05-10 19:10:00‘);
mysql> insert into `student` (`id`, `name`, `age`, `createtime`) values(‘3‘,‘wangwu‘,‘38‘,‘2021-05-10 20:10:00‘);
2、创建作业的配置文件(json格式)
[hadoop@hadoop03 datax]$ cd /bigdata/install/datax
[hadoop@hadoop03 datax]$ python bin/datax.py -r mysqlreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
hdfswriter插件文档
3、根据模板写配置文件
/bigdata/install/datax/job 目录,然后创建配置文件 mysql2hdfs.json, 文件内容如下:{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": [
"select id,name,age,createtime from student where age < 30;"
],
"jdbcUrl": [
"jdbc:mysql://hadoop02:3306/datax"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hadoop01:8020",
"fileType": "text",
"path": "/datax/mysql2hdfs/",
"fileName": "student.txt",
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "INT"
},
{
"name": "createtime",
"type": "TIMESTAMP"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"gzip"
}
}
}
]
}
}
4、启HDFS, 创建目标路径
[hadoop@hadoop01 ~]$ start-dfs.sh
[hadoop@hadoop01 ~]$ hdfs dfs -mkdir -p /datax/mysql2hdfs
5、启动DataX
[hadoop@hadoop03 bin]$ cd /bigdata/install/datax
[hadoop@hadoop03 bin]$ python bin/datax.py job/mysql2hdfs.json
6、观察控制台输出结果
同步结束,显示日志如下:
2021-06-18 01:41:26.452 [job-0] INFO JobContainer -
任务启动时刻 : 2021-06-18 01:41:14
任务结束时刻 : 2021-06-18 01:41:26
任务总计耗时 : 11s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
7、查看HDFS上文件生成,并验证结果
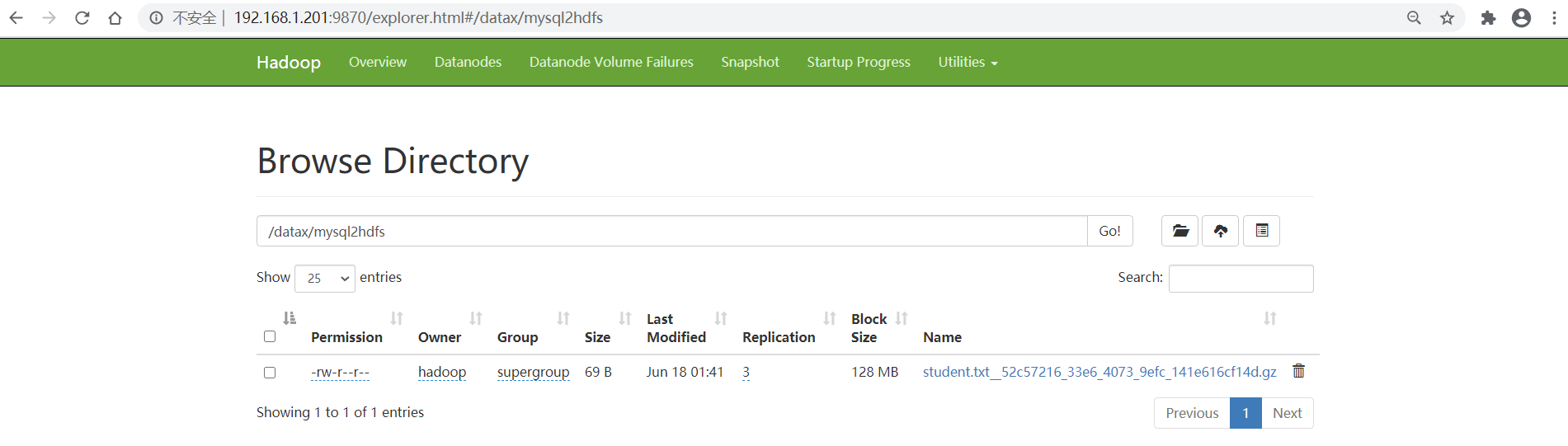
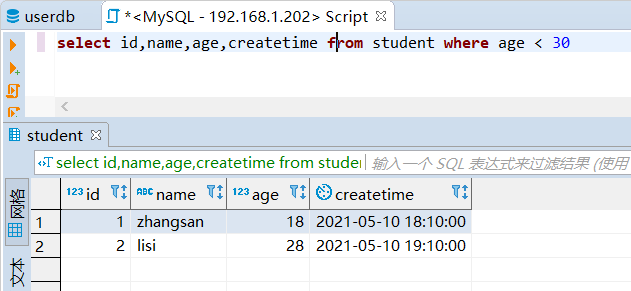
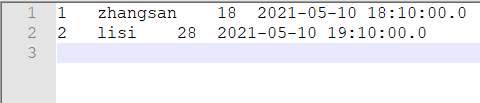
将上边结果下载解压后打开,可以看到里面的结果和mysql中结果对比
DataX 实战案例 -- 使用datax实现将mysql数据导入到hdfs
原文:https://www.cnblogs.com/tenic/p/14901689.html