1.覆盖索引
1.1 定义
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。
1.2 覆盖索引不能生效的情况有2种
- 查询列是表的所有列的情况
- 解决方案有
- 子查询,走覆盖索引,然后进行表关联即可
- 查询列中进行索引列的显示
- 查询条件使用like且是前缀的方式
2.聚簇索引
- 如果表设置了
主键,则主键就是聚簇索引
- 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
- InnoDB的聚簇索引的
叶子节点存储的是行记录(其实是页结构,一个页包含多行数据)
- InnoDB必须要有
至少一个聚簇索引。
- 由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
3.普通索引
- 普通索引也叫二级索引,除聚簇索引外的索引,即非聚簇索引。
- InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
4.聚簇索引与普通索引的区别
- InnoDB聚集索引的叶子节点
存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
- 如果表定义了PK,则PK就是聚集索引;
- 如果表没有定义PK,则第一个not NULL unique列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
- InnoDB普通索引的叶子节点
存储主键值。
5.索引覆盖使用场景
场景1:全表count查询优化
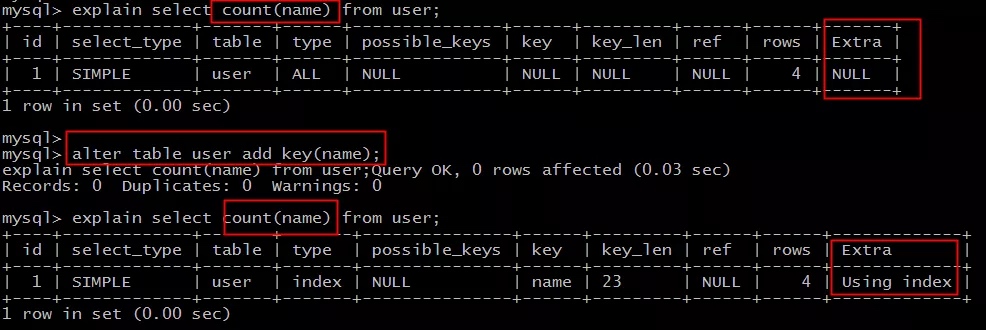
-- 原表为:
user(PK id, name, sex);
-- 直接:
select count(name) from user;
-- 不能利用索引覆盖。
-- 添加索引:
alter table user add key(name);
-- 就能够利用索引覆盖提效。
场景2:列查询回表优化
-- 将单列索引(name)升级为联合索引(name, sex),即可避免回表
select id,name,sex ... where name=‘shenjian‘;
场景3:分页查询
select id,name,sex ... order by name limit 500,100;
-- 但是这个分页不是最优的,当前是从索引覆盖角度考虑的,如果综合考虑性能,需要在where id >=500, 主要考虑 id 很大时,IO的分页加载到内存是很耗时的
6.回表查询
先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
7.如何创建有效的索引
7.1 索引选择性
这个针对列是字符串类型的。需要对字符串的一部分前缀作为索引。这时需要引入索引选择性,索引选择性是指不重复的索引值与数据表的记录总数的比值,可以看出索引选择性越高则查询效率越高,当索引选择性为1时,效率是最高的,但是在这种场景下,很明显索引选择性为1的话我们会付出比较高的代价,索引会很大(存放索引的物理空间增大,同时加载索引到内存页的IO频繁)
7.2 如果创建有效索引
- 选择前缀
- 计算该列完整列的选择性,使得前缀选择性接近于完整列的选择性
- 使用多列索引
- 选择合适的索引列顺序
- 经验是将选择性最高的列放到索引最前列,可以在查询的时候过滤出更少的结果集
- 但这样并不总是最好的,如果考虑到
group by或者 order by 等情况,再比如考虑到一些特别场景下的 guest 账号等数据情况,上面的经验法则可能就不是最适用的
- 覆盖索引
- 所谓覆盖索引就是指索引中包含了查询中的所有字段,这种情况下就不需要再进行回表查询了
- MySQL 中只能使用
B-Tree索引做覆盖索引,因为哈希索引等都不存储索引的列的值,覆盖索引对于 MyISAM 和 InnoDB 都非常有效,可以减少系统调用和数据拷贝等时间
- Tips:减少
select *操作
- 使用索引扫描来做排序
- MySQL 生成有序的结果有两种方法:通过排序操作,或者按照索引顺序扫描;使用排序操作需要占用大量的 CPU 和内存资源,而使用 index 性能是很好的,所以,当我们查询有序结果时,尽量使用索引顺序扫描来生成有序结果集
- 怎样保证使用索引顺序扫描
- 索引列顺序和 ORDER BY 顺序一致
- 所有列的排序方向一致
- 如果关联多表,那么只有当 ORDER BY 子句引用的字段全部为第一张表时,才能使用索引做排序,限制依然是需要满足索引的最左前缀要求
- 压缩索引
- MyISAM 中使用了前缀压缩技术,会减少索引的大小,可以在内存中存储更多的索引,这部分优化默认也是只针对字符串的,但是可以自定义对整数做压缩
- 这个优化在一定情况下性能比较好,但是对于某些情况可能会导致更慢,因为前缀压缩决定了每个关键字都必须依赖于前面的值,所以无法使用二分查找等,只能顺序扫描,所以如果查找的是逆序那么性能可能不佳
- 减少重复、冗余以及未使用的索引
- MySQL 的唯一限制和主键限制都是通过索引实现的,所以不需要在同一列上增加主键、唯一限制再创建索引,这样是重复索引
- 尽量减少新增索引,而应该扩展已有的索引,因为新增索引可能会导致 INSERT、UPDATE、DELETE 等操作更慢
- 可以考虑删除没有使用到的索引,定位未使用的索引,有两个办法,在
Percona Server 或者 MariaDB 中打开 userstates 服务器变量,然后等服务器运行一段时间后,通过查询 INFORMATION_SCHEMA.INDEX_STATISTICS 就可以查询到每个索引的使用频率
- 索引和锁
- InnoDB 支持行锁和表锁,默认使用行锁,而 MyISAM 使用的是表锁,所以使用索引可以让查询锁定更少的行,这样也会提升查询的性能,如果查询中锁定了1000行,但实际只是用了100行,那么在 5.1 之前都需要提交事务之后才能释放这些锁,5.1 之后可以在服务器端过滤掉行之后就释放锁,不过依然会导致一些锁冲突
- 减少索引和数据碎片
- 首先我们需要了解一下为什么会产生碎片,比如 InnoDB 删除数据时,这一段空间就会被留空,如果一段时间内大量删除数据,就会导致留空的空间比实际的存储空间还要大,这时候如果进行新的插入操作时,MySQL 会尝试重新使用这部分空间,但是依然无法彻底占用,这样就会产生碎片
- 产生碎片带来的后果当然是,降低查询性能,因为这种情况会导致随机磁盘访问
- 可以通过
OPTIMIZE TABLE或者重新导入数据表来整理数据
8.索引下推
MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数。
8.1示例说明
需求
查询表中“名字第一个字是张,性别男,年龄为10岁的所有记录”。那么,查询语句是这么写的:
select * from tuser where name like ‘张 %‘ and age=10 and ismale=1;
根据前面说的“最左前缀原则”,该语句在搜索索引树的时候,只能匹配到名字第一个字是‘张’的记录(即记录ID3),接下来是怎么处理的呢?当然就是从ID3开始,逐个回表,到主键索引上找出相应的记录,再比对age和ismale这两个字段的值是否符合。
原理推论
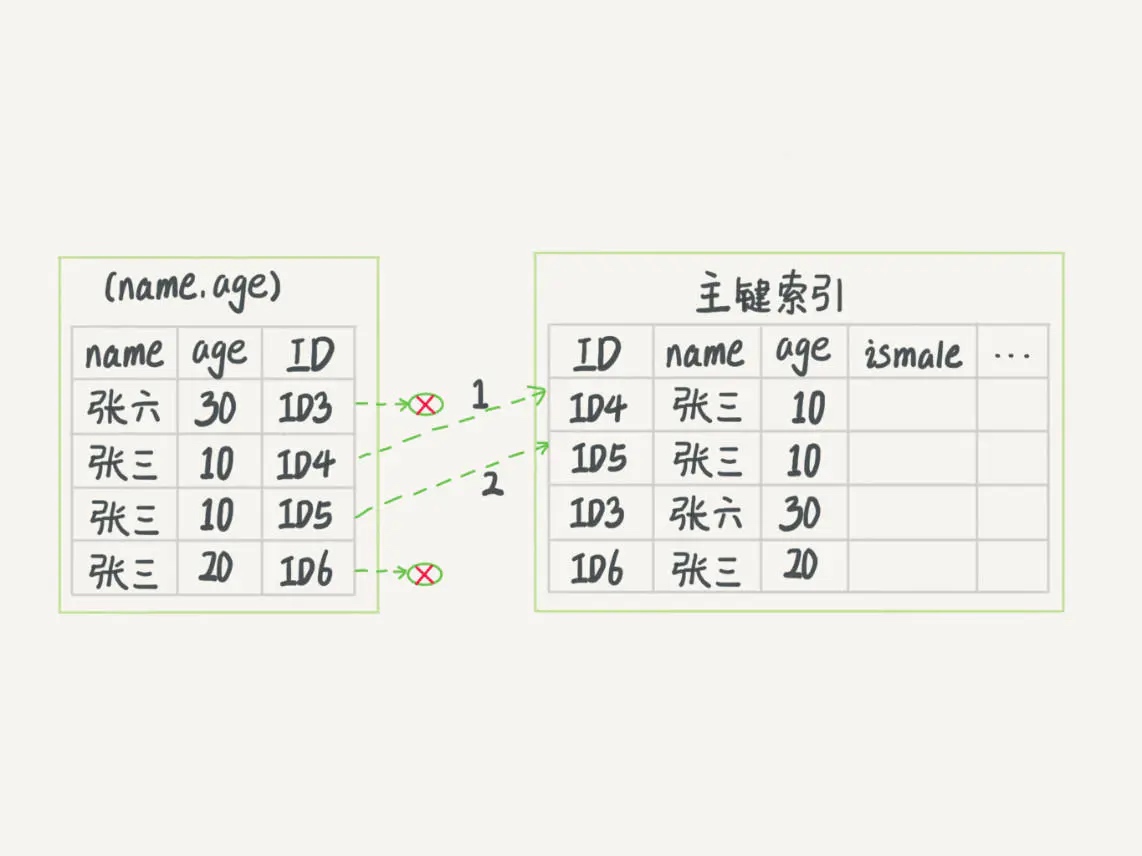
下面图1、图2分别展示这两种情况。
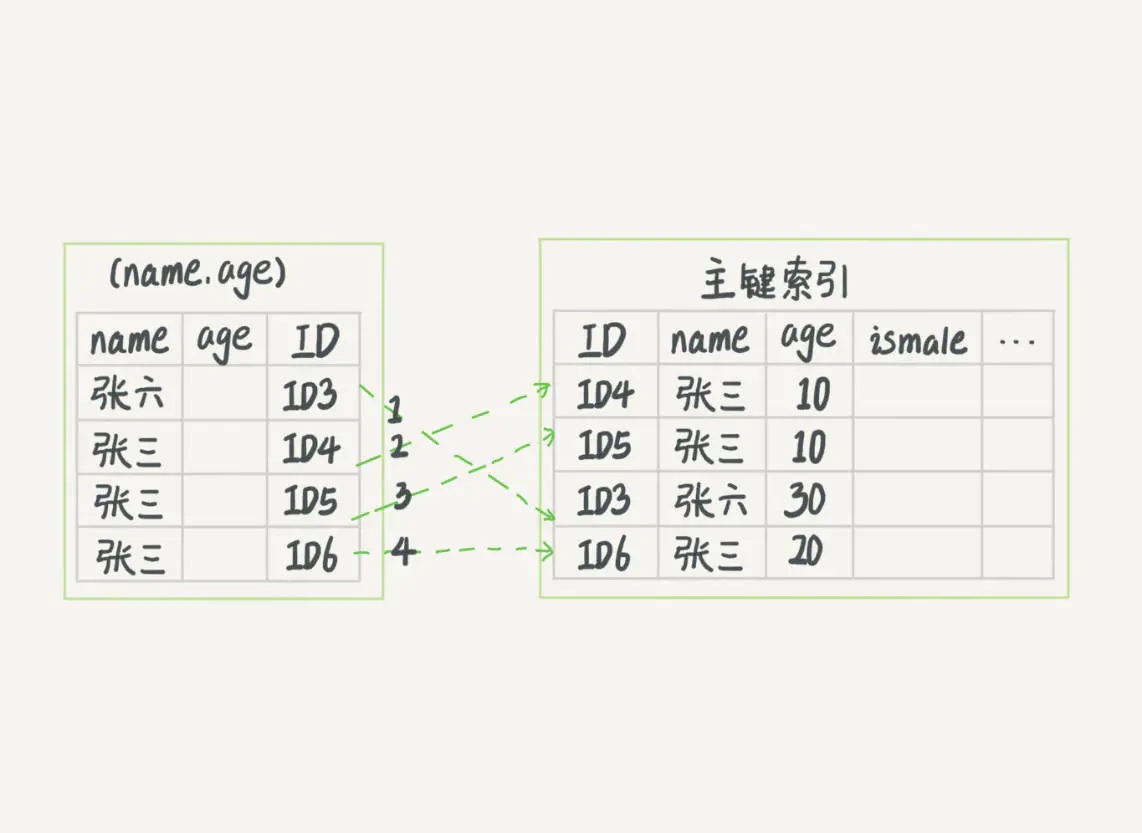
- 图 1 中,在 (name,age) 索引里面我特意去掉了 age 的值,这个过程 InnoDB 并不会去看 age 的值,只是按顺序把“name 第一个字是’张’”的记录一条条取出来回表。因此,需要回表 4 次。
- 图 2 跟图 1 的区别是,InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过。在我们的这个例子中,只需要对 ID4、ID5 这两条记录回表取数据判断,就只需要回表 2 次。
总结
如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
0001.索引
原文:https://www.cnblogs.com/zsh2871/p/0001-suo-yin.html