File file = new File("C:\\Users\\Marydon\\Desktop\\个人信用报告.pdf");
try {
FileInputStream fis = new FileInputStream(file);
// 强转成int类型大小的数组
byte[] fileBytes = new byte[(int) file.length()];
// 将pdf内容放到数组当中
fis.read(fileBytes);
// 关闭文件流
fis.close();
System.out.println(Arrays.toString(fileBytes));
} catch (IOException e) {
e.printStackTrace();
}

在这里会触发一个思考题:
将文件的长度类型long强制转换成int,真的可以吗?
起初,我觉得这样不妥,原因在于:假设当文件的长度>Integer类型的最大值时,那就这样肯定就不行了,byte[]将不是一个完整的文件数组集合,怎么办?
我首先想到的是:
我们在进行文件流的读写操作时,通常使用的是这种方式
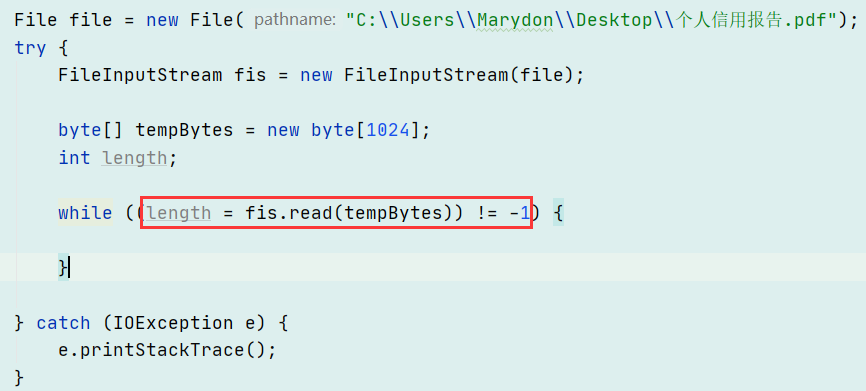
写到这里,我才明白,这种循环读取的方式是因为有地方可以接受读取到的字节,我们这里呢?本来就是要用数组接收的,现在接收不下,没有办法,要想实现的话,也就只能将文件拆分成多个数字集合,这样一来,和我的初衷背道而驰,我就是想要将它们融合到一个数组,显然,这种方式是行不通的。
接下来,我就查了在Java中,数组的最大限制相关信息:
数组的最大限制,理论值是:
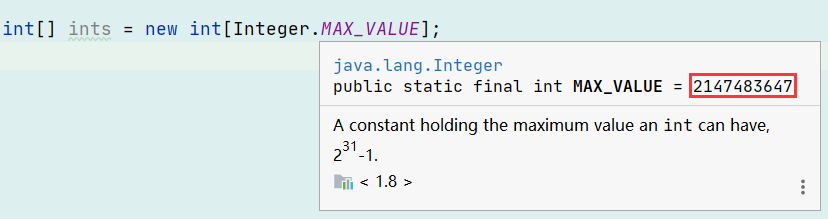
相当于2G的大小,对应应用内存的话是4G(源自网络,不知其真假性,如果有好心人进行测试一下,欢迎留言)
当我创建一个最大的数组时,结果如下:
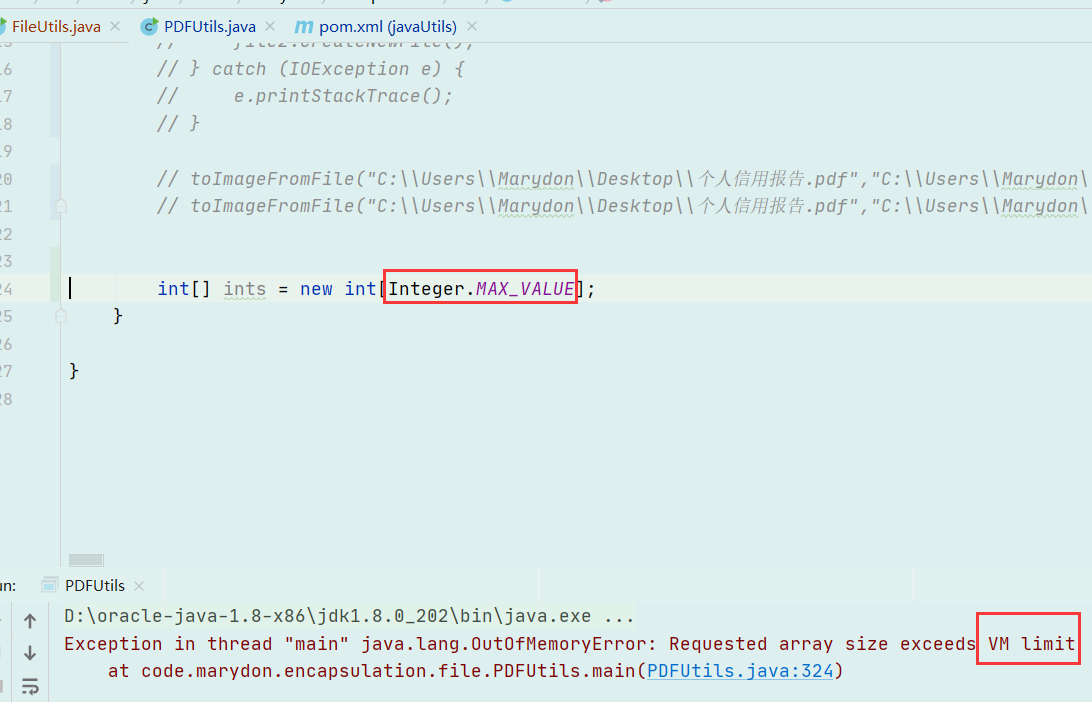
数组所需内存超过了Java虚拟机的内存,GAME OVER。
然后,继续查:
了解到:Java数组最大容量同时受两方面限制
一是:数组可索引的最大元素(也就是Integer的最大值);二是:应用程序可用的内存量(也就是JVM的容量)。
走到这里,基本上恍然大悟啦:
只要我们能将文件成功转换成单个数组,就说明:
文件的长度必然<数组容量的最大值,否则运行起来肯定报错。
所以,上述代码中将文件的长度类型long强制转换成int,是完全可以的,如果不可以(也就是文件超过了数组最大容量) ,那就不用考虑将文件转单个数组的实现方式啦。
另外,如果你想用BufferInputStream来加快读取速度的话,也是可以哒。
对于有强迫症的人来说,强转还是很让人不舒服的,可以使用下面代码,一劳永逸
推荐使用
File file = new File("C:\\Users\\Marydon\\Desktop\\个人信用报告.pdf");
try {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
// 以字节流的大小来指定数组大小
byte[] fileBytes = new byte[bis.available()];
// 将pdf内容放到数组当中
bis.read(fileBytes);
// 关闭文件流
bis.close();
System.out.println(Arrays.toString(fileBytes));
} catch (IOException e) {
e.printStackTrace();
}
使用条件:>=JDK1.8
try {
// 方式一
byte[] bytes = Files.readAllBytes(Paths.get("C:\\Users\\Marydon\\Desktop\\个人信用报告.pdf"));
// 方式二
// bytes = Files.readAllBytes(new File(("C:\\Users\\Marydon\\Desktop\\个人信用报告.pdf")).toPath());
System.out.println(Arrays.toString(bytes));
} catch (IOException e) {
e.printStackTrace();
}

但是,这种方式比较鸡肋,大文件(100多兆)读取容易内存溢出。
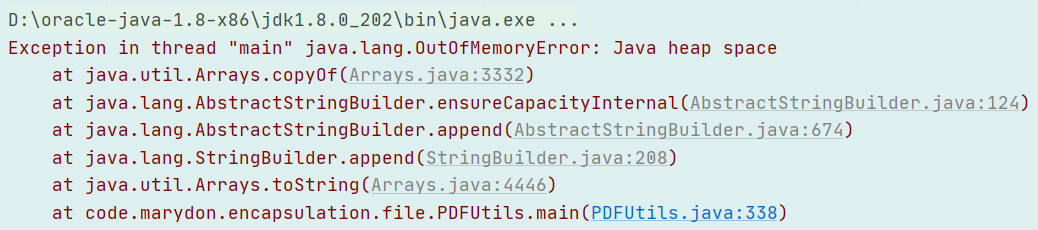
如果发现读取完毕,获得的数组始终为空[],很有可能是你的原文件已经被破坏

// 文件流
byte[] fileBytes = {37, 80, 68, 70, 45, 49, 46, 52, 10, 37, -30, -29, -49, -45, 10, 50, 32, 48, 32, 111, 98, 106, 10, 60, 60, 47, 84, 121, 112, 101, 47, 88, 79};
try {
// 将要输出的文件
File outFile = new File("C:\\Users\\Marydon\\Desktop\\aa.pdf");
// 文件转输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(outFile));
// 将文件流写入文件
bos.write(fileBytes);
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
上面提供的文件字节数组,是无法转成正常文件的哦,我这里仅提供实现方法
// 文件流
byte[] fileBytes = {37, 80, 68, 70, 45, 49, 46, 52, 10, 37, -30, -29, -49, -45, 10, 50, 32, 48, 32, 111, 98, 106, 10, 60, 60, 47, 84, 121, 112, 101, 47, 88, 79};
try {
// 将数组输出到指定文件当中
Files.write(Paths.get("C:\\Users\\Marydon\\Desktop\\aa.pdf"), fileBytes);
} catch (IOException e) {
e.printStackTrace();
}
原文:https://www.cnblogs.com/Marydon20170307/p/14915605.html