弹幕视频,弹幕指直接显现在视频上的评论,可以以滚动、停留甚至更多动作特效方式出现在视频上,是观看视频的人发送的简短评论。
2014年12月9日,弹幕正在真正从小众走向台前,"逐渐"侵蚀主流平台。用户可通过弹幕寻找到有共同兴趣爱好的其他用户,搭建有别以往的兴趣圈子。
一般情况,该类网站能允许观看视频者发表评论或感想,但与普通视频分享网站只在播放器下专用点评区显示不同,其会以滑动字幕的方式实时出现视频画面上,
保证所有观看者都能注意到,从而实现观看者间的互动,甚至可以一起表达对作品的赞叹或批评,增加观看乐趣。
本篇文章爬取了腾讯视频上电视剧《想见你》的部分弹幕。
1.爬取弹幕
首先先找到弹幕的链接网址
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery1910014051953985803944_1579443369825&target_id=4576819405%26vid%3Di0033qa01p1&session_key=23873%2C84%2C1579443370×tamp=75&_=1579443369830
多看几集多找几个弹幕链接,发现主要改变的就是target_id和timestamp,然后简化链接,最终实验出了只要target_id和timestamp的url。
# ‘https://mfm.video.qq.com/danmu?otype=json×tamp=2385&target_id=4576819404%26vid%3Du0033tu6jy5&count=80‘#无数据 # #最后一页1995=133*15 # ‘2385‘ #最后就是 #https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id={}%26vid%3D{}&count=400&second_count=5
找到每一集对应的target_id和v_id才能得到每一集的弹幕,所以再去找找哪里有那些target_id和v_id。
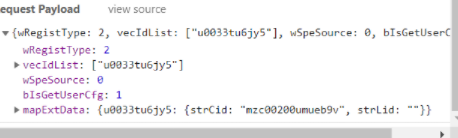

大概思路就是这样,到处找我们想要的最后得到就行。
2.爬取弹幕爬虫代码
import requests import json import pandas as pd import time import random # 页面基本信息解析,获取构成弹幕网址所需的后缀ID、播放量、集数等信息。 def parse_base_info(url, headers): df = pd.DataFrame() html = requests.get(url, headers=headers) bs = json.loads(html.text[html.text.find(‘{‘):-1]) for i in bs[‘results‘]: v_id = i[‘id‘] title = i[‘fields‘][‘title‘] view_count = i[‘fields‘][‘view_all_count‘] episode = int(i[‘fields‘][‘episode‘]) if episode == 0: pass else: cache = pd.DataFrame({‘id‘: [v_id], ‘title‘: [title], ‘播放量‘: [view_count], ‘第几集‘: [episode]}) df = pd.concat([df, cache]) return df # 传入后缀ID,获取该集的target_id并返回 def get_episode_danmu(v_id, headers): base_url = ‘https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1‘ pay = {"wRegistType": 2, "vecIdList": [v_id], "wSpeSource": 0, "bIsGetUserCfg": 1, "mapExtData": {v_id: {"strCid": "mzc00200umueb9v", "strLid": ""}}} html = requests.post(base_url, data=json.dumps(pay), headers=headers) bs = json.loads(html.text) danmu_key = bs[‘data‘][‘stMap‘][v_id][‘strDanMuKey‘] target_id = danmu_key[danmu_key.find(‘targetid‘) + 9: danmu_key.find(‘vid‘) - 1] return [v_id, target_id] # 解析单个弹幕页面,需传入target_id,v_id(后缀ID)和集数(方便匹配),返回具体的弹幕信息 def parse_danmu(url, target_id, v_id, headers, period): html = requests.get(url, headers=headers) bs = json.loads(html.text, strict=False) df = pd.DataFrame() try: for i in bs[‘comments‘]: content = i[‘content‘] name = i[‘opername‘] upcount = i[‘upcount‘] user_degree = i[‘uservip_degree‘] timepoint = i[‘timepoint‘] comment_id = i[‘commentid‘] cache = pd.DataFrame({‘用户名‘: [name], ‘内容‘: [content], ‘会员等级‘: [user_degree], ‘弹幕时间点‘: [timepoint], ‘弹幕点赞‘: [upcount], ‘弹幕id‘: [comment_id], ‘集数‘: [period]}) df = pd.concat([df, cache]) except: pass return df # 构造单集弹幕的循环网页,传入target_id和后缀ID(v_id),通过设置爬取页数来改变timestamp的值完成翻页操作 def format_url(target_id, v_id, page=85): urls = [] base_url = ‘https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id={}%26vid%3D{}&count=400&second_count=5‘ for num in range(15, page * 30 + 15, 30): url = base_url.format(num, target_id, v_id) urls.append(url) #print(urls) return urls def get_all_ids(part1_url,part2_url, headers): part_1 = parse_base_info(part1_url, headers) part_2 = parse_base_info(part2_url, headers) df = pd.concat([part_1, part_2]) df.sort_values(‘第几集‘, ascending=True, inplace=True) count = 1 # 创建一个列表存储target_id info_lst = [] for i in df[‘id‘]: info = get_episode_danmu(i, headers) info_lst.append(info) print(‘正在努力爬取第 %d 集的target_id‘ % count) count += 1 time.sleep(2 + random.random()) print(‘是不是发现多了一集?别担心,会去重的‘) # 根据后缀ID,将target_id和后缀ID所在的表合并 info_lst = pd.DataFrame(info_lst) info_lst.columns = [‘v_id‘, ‘target_id‘] combine = pd.merge(df, info_lst, left_on=‘id‘, right_on=‘v_id‘, how=‘inner‘) # 去重复值 combine = combine.loc[combine.duplicated(‘id‘) == False, :] return combine # 输入包含v_id,target_id的表,并传入想要爬取多少集 def crawl_all(combine, num, page, headers): c = 1 final_result = pd.DataFrame() for v_id, target_id in zip(combine[‘v_id‘][:num], combine[‘target_id‘][:num]): count = 1 urls = format_url(target_id, v_id, page) for url in urls: result = parse_danmu(url, target_id, v_id, headers, c) final_result = pd.concat([final_result, result]) time.sleep(2 + random.random()) print(‘这是 %d 集的第 %d 页爬取..‘ % (c, count)) count += 1 print(‘-------------------------------------‘) c += 1 return final_result if __name__ == ‘__main__‘: part1_url = ‘https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=x00335pmni4,u0033s6w87l,a0033ocq64d,z0033hacdb0,k30411thjyx,x00330kt2my,o0033xvtciz,r0033i8nwq5,q0033f4fhz2,a3033heyf4t,p0033giby5x,g0033iiwrkz,m0033hmbk3e,a0033m43iq4,o003381p611,c00339y0zzt,w0033ij5l6r,d0033mc7glb,k003314qjhw,x0033adrr32,h0033oqojcq,a00335xx2ud,t0033osrtb7&callback=jQuery191022356914493548485_1579090019078&_=1579090019082‘ part2_url = ‘https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=t00332is4j6,i0033qa01p1,w0033mb4upm,u0033tu6jy5,v0033x5trub,h00336e2bmu,t00332is4j6,v0033l43n4x,s0033vhz5f6,u003325xf5p,n0033a2n6sl,s00339e7vqp,p0033je4tzi,y0033a6tibn,x00333vph31,v0033d7uaui,g0033a8ii9x,e0033hhaljd,g00331f53yk,m00330w5o8v,o00336lt4vb,l0033sko92l,g00337s3skh,j30495nlv60,m3047vci34u,j3048fxjevm,q0033a3kldj,y0033k978fd,a0033xrwikg,q0033d9y0jt&callback=jQuery191022356914493548485_1579090019080&_=1579090019081‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘ } # 得到所有的后缀ID,基于后缀ID爬取target_id combine = get_all_ids(part1_url,part2_url, headers) # 设置要爬取多少集(num参数),每一集爬取多少页弹幕(1-85页,page参数) # 比如想要爬取30集,每一集85页,num = 30,page = 85 final_result = crawl_all(combine, num=5, page=80, headers=headers) final_result.to_excel(‘./想见你弹幕.xlsx‘)
3.数据处理分析
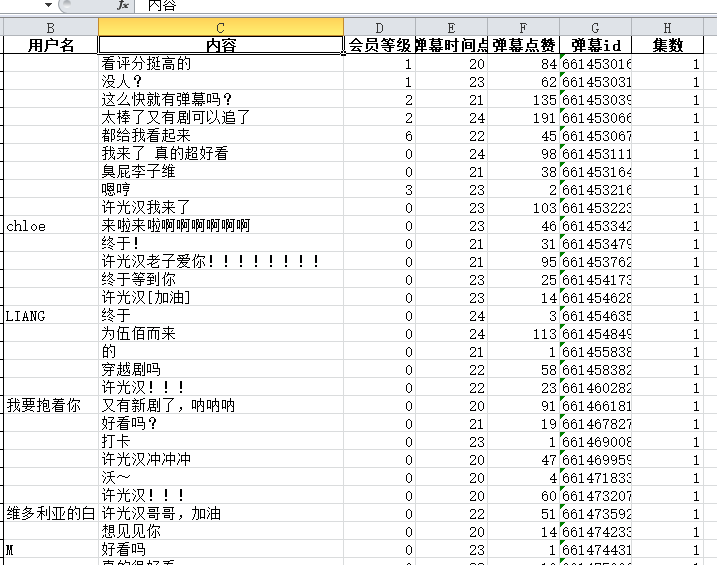
爬取之后我们的弹幕是这个样子
导入pandas数据清洗
import pandas as pd import numpy as np import matplotlib from matplotlib import pyplot as plt import seaborn as sns plt.rcParams[‘font.sans-serif‘]=‘FangSong‘ plt.rcParams[‘axex.unicode_minus‘]=False
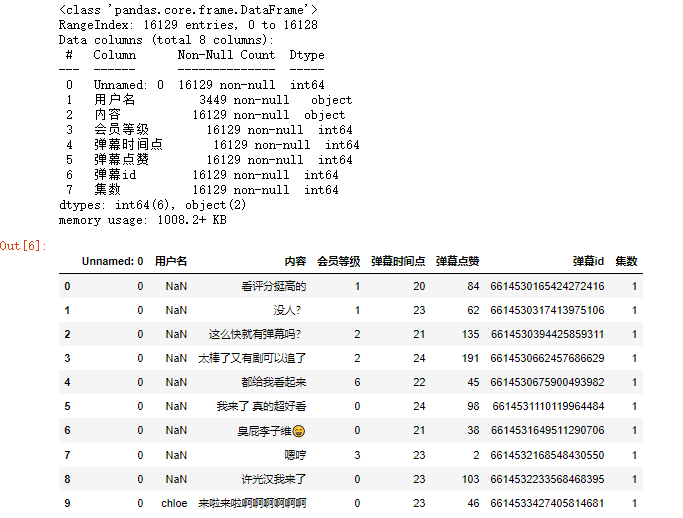
df=pd.read_excel(‘./想见你弹幕.xlsx‘) df.info() df.head(10)
df.isnull().sum() #查看缺失值情况

删除内容缺失的行,由于用户名缺失占比太大无法直接删除,将缺失的改成匿名
df=df.dropna(subset=[‘内容‘]) df[‘用户名‘].fillna(‘匿名‘,inplace=True) df.info() df.head(30)
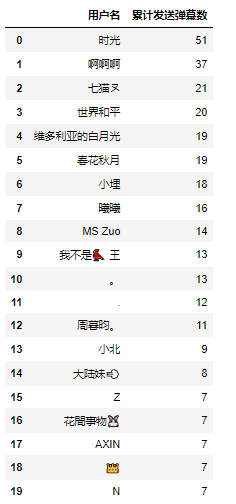
然后看看谁发的弹幕最多(只考虑有用户名的用户)
#同一个人发了多少弹幕 dmby1=df.groupby(‘用户名‘)[‘弹幕id‘].count().sort_values(ascending= False).reset_index() dmby1.columns = [‘用户名‘,‘累计发送弹幕数‘] dmby1.head(20)
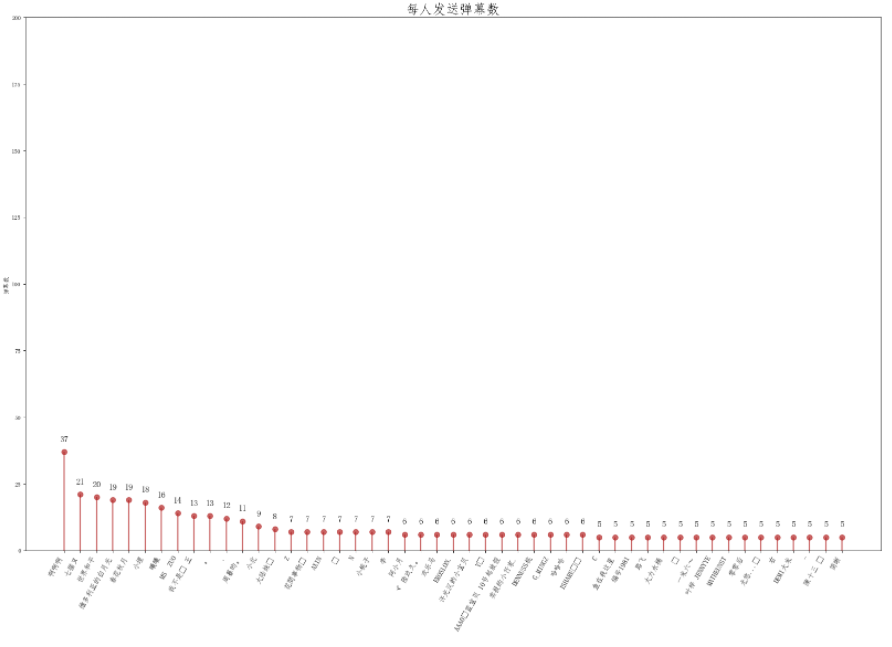
将每人的弹幕数量可视化一下
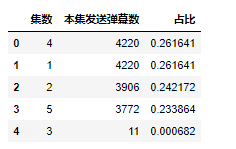
统计每集弹幕数
#每一集有多少弹幕 dm=df.groupby(‘集数‘)[‘内容‘].count().sort_values(ascending= False).reset_index() dm.columns = [‘集数‘,‘本集发送弹幕数‘] dm[‘占比‘]=dm[‘本集发送弹幕数‘]/sum(dm[‘本集发送弹幕数‘]) dm.head()
# 可视化 plt.pie(x =dm[‘占比‘], labels=dm[‘集数‘],autopct=‘%1.1f%%‘) plt.title(‘各集弹幕占比‘) plt.show()
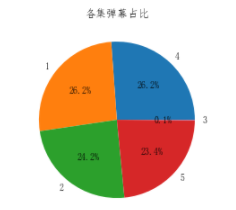
生成词云
#词云 from wordcloud import WordCloud import imageio import jieba df[‘内容‘]=df[‘内容‘].astype(str) word_list=" ".join(df[‘内容‘]) word_list=" ".join(jieba.cut(word_list)) #设置词云 wc = WordCloud( mask = imageio.imread(‘./1.jpg‘), max_words = 500, font_path = ‘C:/Windows/Fonts/simhei.ttf‘, width=400, height=860, ) #生成词云 myword = wc.generate(word_list) wc.to_file("./想见你词云.png") #展示词云图 fig = plt.figure(dpi=80) plt.imshow(myword) plt.title(‘想见你词云‘) plt.axis(‘off‘) plt.show()

#弹幕情感分析 from snownlp import SnowNLP def sentiment(row): content = str(row[‘内容‘]).strip() s = SnowNLP(content) score = float(s.sentiments) return score df[‘score‘] = df.apply(sentiment, axis = 1) df1 = df.groupby([‘弹幕时间点‘],as_index=False)[‘score‘].mean() df1.head()
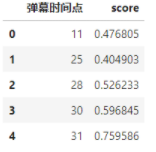
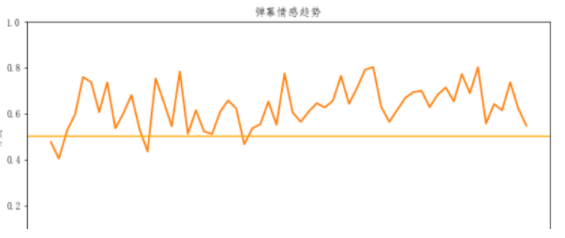
fig = plt.figure(figsize=(10, 4.5)) plt.plot(df1[0:60],lw=2) plt.title("弹幕情感趋势") plt.xlabel("时间") plt.ylabel("分数") plt.ylim(0,1) plt.axhline(0.5, color=‘orange‘) plt.show()
4.完整代码
import requests import json import pandas as pd import time import random # 页面基本信息解析,获取构成弹幕网址所需的后缀ID、播放量、集数等信息。 def parse_base_info(url, headers): df = pd.DataFrame() html = requests.get(url, headers=headers) bs = json.loads(html.text[html.text.find(‘{‘):-1]) for i in bs[‘results‘]: v_id = i[‘id‘] title = i[‘fields‘][‘title‘] view_count = i[‘fields‘][‘view_all_count‘] episode = int(i[‘fields‘][‘episode‘]) if episode == 0: pass else: cache = pd.DataFrame({‘id‘: [v_id], ‘title‘: [title], ‘播放量‘: [view_count], ‘第几集‘: [episode]}) df = pd.concat([df, cache]) return df # 传入后缀ID,获取该集的target_id并返回 def get_episode_danmu(v_id, headers): base_url = ‘https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1‘ pay = {"wRegistType": 2, "vecIdList": [v_id], "wSpeSource": 0, "bIsGetUserCfg": 1, "mapExtData": {v_id: {"strCid": "mzc00200umueb9v", "strLid": ""}}} html = requests.post(base_url, data=json.dumps(pay), headers=headers) bs = json.loads(html.text) danmu_key = bs[‘data‘][‘stMap‘][v_id][‘strDanMuKey‘] target_id = danmu_key[danmu_key.find(‘targetid‘) + 9: danmu_key.find(‘vid‘) - 1] return [v_id, target_id] # 解析单个弹幕页面,需传入target_id,v_id(后缀ID)和集数(方便匹配),返回具体的弹幕信息 def parse_danmu(url, target_id, v_id, headers, period): html = requests.get(url, headers=headers) bs = json.loads(html.text, strict=False) df = pd.DataFrame() try: for i in bs[‘comments‘]: content = i[‘content‘] name = i[‘opername‘] upcount = i[‘upcount‘] user_degree = i[‘uservip_degree‘] timepoint = i[‘timepoint‘] comment_id = i[‘commentid‘] cache = pd.DataFrame({‘用户名‘: [name], ‘内容‘: [content], ‘会员等级‘: [user_degree], ‘弹幕时间点‘: [timepoint], ‘弹幕点赞‘: [upcount], ‘弹幕id‘: [comment_id], ‘集数‘: [period]}) df = pd.concat([df, cache]) except: pass return df # 构造单集弹幕的循环网页,传入target_id和后缀ID(v_id),通过设置爬取页数来改变timestamp的值完成翻页操作 def format_url(target_id, v_id, page=85): urls = [] base_url = ‘https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id={}%26vid%3D{}&count=400&second_count=5‘ for num in range(15, page * 30 + 15, 30): url = base_url.format(num, target_id, v_id) urls.append(url) #print(urls) return urls def get_all_ids(part1_url,part2_url, headers): part_1 = parse_base_info(part1_url, headers) part_2 = parse_base_info(part2_url, headers) df = pd.concat([part_1, part_2]) df.sort_values(‘第几集‘, ascending=True, inplace=True) count = 1 # 创建一个列表存储target_id info_lst = [] for i in df[‘id‘]: info = get_episode_danmu(i, headers) info_lst.append(info) print(‘正在努力爬取第 %d 集的target_id‘ % count) count += 1 time.sleep(2 + random.random()) print(‘是不是发现多了一集?别担心,会去重的‘) # 根据后缀ID,将target_id和后缀ID所在的表合并 info_lst = pd.DataFrame(info_lst) info_lst.columns = [‘v_id‘, ‘target_id‘] combine = pd.merge(df, info_lst, left_on=‘id‘, right_on=‘v_id‘, how=‘inner‘) # 去重复值 combine = combine.loc[combine.duplicated(‘id‘) == False, :] return combine # 输入包含v_id,target_id的表,并传入想要爬取多少集 def crawl_all(combine, num, page, headers): c = 1 final_result = pd.DataFrame() for v_id, target_id in zip(combine[‘v_id‘][:num], combine[‘target_id‘][:num]): count = 1 urls = format_url(target_id, v_id, page) for url in urls: result = parse_danmu(url, target_id, v_id, headers, c) final_result = pd.concat([final_result, result]) time.sleep(2 + random.random()) print(‘这是 %d 集的第 %d 页爬取..‘ % (c, count)) count += 1 print(‘-------------------------------------‘) c += 1 return final_result if __name__ == ‘__main__‘: part1_url = ‘https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=x00335pmni4,u0033s6w87l,a0033ocq64d,z0033hacdb0,k30411thjyx,x00330kt2my,o0033xvtciz,r0033i8nwq5,q0033f4fhz2,a3033heyf4t,p0033giby5x,g0033iiwrkz,m0033hmbk3e,a0033m43iq4,o003381p611,c00339y0zzt,w0033ij5l6r,d0033mc7glb,k003314qjhw,x0033adrr32,h0033oqojcq,a00335xx2ud,t0033osrtb7&callback=jQuery191022356914493548485_1579090019078&_=1579090019082‘ part2_url = ‘https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=t00332is4j6,i0033qa01p1,w0033mb4upm,u0033tu6jy5,v0033x5trub,h00336e2bmu,t00332is4j6,v0033l43n4x,s0033vhz5f6,u003325xf5p,n0033a2n6sl,s00339e7vqp,p0033je4tzi,y0033a6tibn,x00333vph31,v0033d7uaui,g0033a8ii9x,e0033hhaljd,g00331f53yk,m00330w5o8v,o00336lt4vb,l0033sko92l,g00337s3skh,j30495nlv60,m3047vci34u,j3048fxjevm,q0033a3kldj,y0033k978fd,a0033xrwikg,q0033d9y0jt&callback=jQuery191022356914493548485_1579090019080&_=1579090019081‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘ } # 得到所有的后缀ID,基于后缀ID爬取target_id combine = get_all_ids(part1_url,part2_url, headers) # 设置要爬取多少集(num参数),每一集爬取多少页弹幕(1-85页,page参数) # 比如想要爬取30集,每一集85页,num = 30,page = 85 final_result = crawl_all(combine, num=5, page=80, headers=headers) final_result.to_excel(‘./想见你弹幕.xlsx‘) import pandas as pd import numpy as np import matplotlib from matplotlib import pyplot as plt import seaborn as sns plt.rcParams[‘font.sans-serif‘]=‘FangSong‘ plt.rcParams[‘axex.unicode_minus‘]=False df=pd.read_excel(‘./想见你弹幕.xlsx‘) df.info() df.head(10) df.isnull().sum() #查看缺失值情况 df=df.dropna(subset=[‘内容‘]) df[‘用户名‘].fillna(‘匿名‘,inplace=True) df.info() df.head(30) #同一个人发了多少弹幕 dmby1=df.groupby(‘用户名‘)[‘弹幕id‘].count().sort_values(ascending= False).reset_index() dmby1.columns = [‘用户名‘,‘累计发送弹幕数‘] dmby1.head(20) #每一集有多少弹幕 dm=df.groupby(‘集数‘)[‘内容‘].count().sort_values(ascending= False).reset_index() dm.columns = [‘集数‘,‘本集发送弹幕数‘] dm[‘占比‘]=dm[‘本集发送弹幕数‘]/sum(dm[‘本集发送弹幕数‘]) dm.head() # 可视化 plt.pie(x =dm[‘占比‘], labels=dm[‘集数‘],autopct=‘%1.1f%%‘) plt.title(‘各集弹幕占比‘) plt.show() #词云 from wordcloud import WordCloud import imageio import jieba df[‘内容‘]=df[‘内容‘].astype(str) word_list=" ".join(df[‘内容‘]) word_list=" ".join(jieba.cut(word_list)) #设置词云 wc = WordCloud( mask = imageio.imread(‘./1.jpg‘), max_words = 500, font_path = ‘C:/Windows/Fonts/simhei.ttf‘, width=400, height=860, ) #生成词云 myword = wc.generate(word_list) wc.to_file("./想见你词云.png") #展示词云图 fig = plt.figure(dpi=80) plt.imshow(myword) plt.title(‘想见你词云‘) plt.axis(‘off‘) plt.show() #弹幕情感分析 from snownlp import SnowNLP def sentiment(row): content = str(row[‘内容‘]).strip() s = SnowNLP(content) score = float(s.sentiments) return score df[‘score‘] = df.apply(sentiment, axis = 1) df1 = df.groupby([‘弹幕时间点‘],as_index=False)[‘score‘].mean() df1.head() fig = plt.figure(figsize=(10, 4.5)) plt.plot(df1[0:60],lw=2) plt.title("弹幕情感趋势") plt.xlabel("时间") plt.ylabel("分数") plt.ylim(0,1) plt.axhline(0.5, color=‘orange‘) plt.show()
5.总结
这部剧弹幕大部分都是比较正面的评价,而且往往评价高的时间点都在15分钟—35分钟之间,可能是这段时间正式进入剧情吧。弹幕的作用可以让我们看剧的同时发表分享一下自己的想法,但是尽量还是做个文明的看客,
看到有的弹幕无脑黑真的很不好。网络非法外之地,弹幕是现代科技的产物,也映射着社会文明的进步。围绕弹幕的言行也要受到他律和自律。
原文:https://www.cnblogs.com/Lmig/p/14923961.html