场景描述:某系统新上线,老系统的会员数据要导入新系统中,包含手机号,上级信息和会员余额。有1万多条数据,手工对比过于繁琐,用python自动化处理
思路:系统导入数据后,脚本读取文件,先把会员数据取出来,合并成一个数列,然后传入查询函数,把查询结果和读取的数据进行比对,判断导入情况
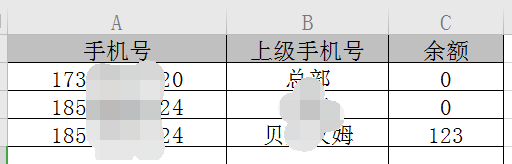
数据文件内容如下图
系统查询接口信息如下:

第一步,读取数据文件,合并成新的数列。这一部分脚本主要包含取excel中任意一列数据、循环读取列数据传到数列中、合并多个数列生成新数列
def phone(): wb = xlrd.open_workbook(path+‘\\2021.xlsx‘)# 打开Excel文件 data = wb.sheet_by_name(‘sheet1‘)#通过excel表格名称(rank)获取工作表 data_1=data.col_values(0)#获取第一列数据(数组)#查询号码 data_2=data.col_values(1)#获取第二列数据(数组)#上级 data_3=data.col_values(2)#获取第三列数据(数组)#余额 list1=[] list2=[] list3=[] for i in data_1[1:10]:#循环读取列数据传到数列中,[1:10]代表只读取第2行到第10行数据 list1.append(i) for h in data_2[1:10]: list2.append(h) for j in data_3[1:10]: list3.append(j) name_tulpe = list(zip(list1,list2,list3))#合并多个数列生成新数列 return(name_tulpe) code=phone()
打印输出结果

第二步,合并后的新数列传到请求函数中,逐一查询匹配结果。这一部分脚本主要用到数列的取值、数据拼接、request返回值json化后提取参数值
def data(params,headers,phone): for num in code: #分割数据,取出手机、上级、余额(数列的取值) 手机 = int(num[0]) 上级 = str(num[1]) 余额 = str(num[2]) print("查询" + ‘ ‘ + str(手机)) print("导入上级"+‘ ‘+上级) print("导入余额"+‘ ‘+余额) #通过手机号查询上级(数据拼接) data = ‘{"PageIndex":1,"PageSize":10,"KeyWord":‘+ str(手机) +‘,"MemberType":"","CardIds":[],"MinLastBuyDate":"","MaxLastBuyDate":"","TagIds":[],"MinPoints":"","MaxPoints":"","MinCreateDate":"","MaxCreateDate":"","SortName":"CreateTime","Sort":"Desc","Source":0,"topAgentId":-1,"CustomProvId":0,"WorkFriendType":0,"ConcernGzhType":0,"p":0.6919700775737443}‘ response = requests.post(‘https://storeapi.xxx.com/xxx/Member/SearchMemberList‘, headers=headers, params=params, data=data) response = response.json() Id = response[‘Data‘][‘DataList‘][0][‘Id‘]#客户id FirstTwitterName = response[‘Data‘][‘DataList‘][0][‘FirstTwitterName‘]#上级昵称 #通过id查询余额(request返回值json化) res = requests.get(‘https://storeapi.xxx.com/xxx/Member/FindMemberInfoById?Id=‘+str(Id), headers=headers) res = res.json() Balance = res[‘Data‘][‘Balance‘]#余额(提取参数值) #打印上级和余额信息 print("查询上级"+‘ ‘+FirstTwitterName) print("查询余额"+‘ ‘+str(Balance)) #判断结果 if 上级 == FirstTwitterName and str(Balance) == 余额: print("匹配成功") else: print("匹配失败") print("---------------") data(params,headers,phone)
执行后的结果

有个问题,如果数据太多,第一步合并新数列会花费很多时间,这里还需要寻找更好的方案,或者用jmeter实现
全部脚本
# -*-coding:utf8-*- # encoding:utf-8 import requests import os import sys import xlrd path = os.path.abspath(os.path.dirname(sys.argv[0])) headers = { ‘authority‘: ‘storeapi.xxxxx.com‘, ‘pragma‘: ‘no-cache‘, ‘cache-control‘: ‘no-cache‘, ‘access-control-request-method‘: ‘POST‘, ‘origin‘: ‘https://adminstore.xxxx.com‘, ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘, ‘access-control-request-headers‘: ‘authorization,content-type,req-host‘, ‘accept‘: ‘application/json‘, ‘sec-fetch-site‘: ‘same-site‘, ‘sec-fetch-mode‘: ‘cors‘, ‘referer‘: ‘https://adminstore.xxxx.com/‘, ‘accept-encoding‘: ‘gzip, deflate, br‘, ‘accept-language‘: ‘zh-CN,zh;q=0.9‘, ‘req-host‘: ‘adminstore.smallmitao.com‘, ‘authorization‘: ‘Bearer xxxx.xxxxx.eKlCnRt8PCC8qdfjS3rOuhAywaulFc3Ad2ujrmNo8uQ‘, ‘content-type‘: ‘application/json; charset=utf-8‘, } params = ( (‘rend‘, ‘0.4068877130021684‘), ) #读取表格内的会员数据 def phone(): wb = xlrd.open_workbook(path+‘\\2021.xlsx‘)# 打开Excel文件 data = wb.sheet_by_name(‘sheet1‘)#通过excel表格名称(rank)获取工作表 data_1=data.col_values(0)#获取第一列数据(数组)#查询号码 data_2=data.col_values(1)#获取第二列数据(数组)#上级 data_3=data.col_values(2)#获取第三列数据(数组)#余额 list1=[] list2=[] list3=[] for i in data_1[1:10]:#循环读取列数据传到数列中,[1:10]代表只读取第2行到第10行数据 list1.append(i) for h in data_2[1:10]: list2.append(h) for j in data_3[1:10]: list3.append(j) name_tulpe = list(zip(list1,list2,list3))#合并多个数列生成新数列 return(name_tulpe) code=phone() def data(params,headers,phone): for num in code: #分割数据,取出手机、上级、余额 手机 = int(num[0]) 上级 = str(num[1]) 余额 = str(num[2]) print("查询" + ‘ ‘ + str(手机)) print("导入上级"+‘ ‘+上级) print("导入余额"+‘ ‘+余额) #通过手机号查询上级 data = ‘{"PageIndex":1,"PageSize":10,"KeyWord":‘+ str(手机) +‘,"MemberType":"","CardIds":[],"MinLastBuyDate":"","MaxLastBuyDate":"","TagIds":[],"MinPoints":"","MaxPoints":"","MinCreateDate":"","MaxCreateDate":"","SortName":"CreateTime","Sort":"Desc","Source":0,"topAgentId":-1,"CustomProvId":0,"WorkFriendType":0,"ConcernGzhType":0,"p":0.6919700775737443}‘ response = requests.post(‘https://storeapi.xxx.com/xxxx/Member/SearchMemberList‘, headers=headers, params=params, data=data) response = response.json() Id = response[‘Data‘][‘DataList‘][0][‘Id‘]#客户id FirstTwitterName = response[‘Data‘][‘DataList‘][0][‘FirstTwitterName‘]#上级昵称 #通过id查询余额 res = requests.get(‘https://storeapi.xxxx.com/xxxx/Member/FindMemberInfoById?Id=‘+str(Id), headers=headers) res = res.json() Balance = res[‘Data‘][‘Balance‘]#余额 #打印上级和余额信息 print("查询上级"+‘ ‘+FirstTwitterName) print("查询余额"+‘ ‘+str(Balance)) #判断结果 if 上级 == FirstTwitterName and str(Balance) == 余额: print("匹配成功") else: print("匹配失败") print("---------------") data(params,headers,phone)
python实例:导入会员数据后,读取数据文件,检查导入正确性(整列取excel值、合并列、response取值)
原文:https://www.cnblogs.com/becks/p/14926257.html