基于python厦门思明区二手房价分析和构建基于机器学习的房价预测模型
一,选题背景
网上有条段子,某地房价5w每平,月收入刚好过万,掐指一算,命中注定买房是不可能的,这辈子都不可能买房,所以要定个小目标:“我真的还想再活500年······”。当然,房子虽贵,但是我可以学学科学的方法了解房价趋势,做到心中有数,万一买的起呢?
二,设计方案
1,爬虫名称:基于python厦门思明区二手房价分析和预测
2,爬虫爬取的内容与数据特征分析:内容主要是:房屋信息;数据特征:房屋信息的归一化与存储
3,设计方案概述:房屋信息的爬取并归一化与存储,进行数据预处理与数据可视化,构建房价预测模型进行多特征模型训练,得到构建基于机器学习的房价预测模型结果
三,结果特征分析
1,利用网络爬虫获取厦门市思明区二手房信息
四,爬虫程序设计
1,数据爬取与采集
# 使用 HTML.parser 解析器
1 import requests 2 from bs4 import BeautifulSoup 3 # requests返回网页内容 4 res = requests.get(r‘https://xm.esf.fang.com/house-a0352/‘) 5 #res.text 6 7 # BeautifulSoup解析网页 8 soup = BeautifulSoup(res.text,‘html.parser‘) # 使用 HTML.parser 解析器
1 def get_house(url): 2 ‘获取页面中每个房子的信息‘ 3 information = {} # 存储房屋所有信息 4 res = requests.get(url) 5 soup = BeautifulSoup(res.text,‘html.parser‘) 6 7 # 获取户型、建筑面积、单价、朝向、楼层、装修情况 8 houses = soup.select(‘.tab-cont-right .trl-item1‘) 9 #print(houses) 10 for house in houses: 11 me = house.text.strip().split(‘\n‘) 12 information[me[1]] = me[0].strip() 13 14 # 获取小区名字 15 name = soup.select(‘.rcont .blue‘) 16 information[‘小区名称‘] = name[0].text 17 18 # 获取房屋总价 19 price = soup.select(‘.trl-item‘) 20 information[‘房屋总价‘] = price[0].text 21 print(information) 22 23 # 函数测试 24 get_house("https://xm.esf.fang.com/chushou/3_346676334.htm?channel=1,2&psid=1_15_60") # 每一页中房子的url(注意:链接可能失效)

1 def get_page(n): 2 ‘分页爬取数据‘ 3 for i in range(1,n+1): # n:爬取页数 4 url = r‘https://xm.esf.fang.com/house-a0352/i3{}/‘.format(i) # 总共多少页 5 res = requests.get(url) 6 houses = BeautifulSoup(res.text,‘html.parser‘) 7 print(url) 8 j = 1 9 houses = houses.select(‘.shop_list .clearfix h4 a‘) # 获取每套房子的href 10 for house in houses: 11 try: 12 demo_url = house[‘href‘] 13 url = r‘https://xm.esf.fang.com‘ + demo_url + ‘?channel=1,2&psid=1_{}_60‘.format(j) # 每一页中有多少套房子 14 # 获取当前页面中每套房子的信息 15 #get_house(url) 16 j += 1 17 except Exception as e: 18 print(‘-------->‘,e) 19 get_page(1)

1 import requests 2 from bs4 import BeautifulSoup 3 4 def get_house(url): 5 ‘获取页面中每个房子的信息‘ 6 information = {} # 存储房屋所有信息 7 res = requests.get(url) 8 soup = BeautifulSoup(res.text,‘html.parser‘) 9 10 # 获取户型、建筑面积、单价、朝向、楼层、装修情况 11 houses = soup.select(‘.tab-cont-right .trl-item1‘) 12 for house in houses: 13 m = house.text.strip().split(‘\n‘) 14 me = m[1] 15 if ‘朝向‘ in me: 16 me = me.strip(‘进门‘) 17 if ‘楼层‘in me: 18 me = me[0:2] 19 if ‘地上层数‘ in me: 20 me = ‘楼层‘ 21 if ‘装修程度‘ in me: 22 me = ‘装修‘ 23 information[me] = m[0].strip() 24 25 # 获取小区名字 26 name = soup.select(‘.rcont .blue‘) 27 information[‘小区名称‘] = name[0].text 28 29 # 获取房屋总价 30 price = soup.select(‘.trl-item‘) 31 information[‘房屋总价‘] = price[0].text 32 return information 33 34 # 函数测试 35 get_house("https://xm.esf.fang.com/chushou/3_346676334.htm?channel=1,2&psid=1_15_60") # 每一页中房子的url

1 import pandas as pd 2 import time 3 4 def get_page(i): 5 ‘分页爬取数据‘ 6 url = r‘https://xm.esf.fang.com/house-a0352/i3{}/‘.format(i) # 总共多少页 7 res = requests.get(url) 8 houses = BeautifulSoup(res.text,‘html.parser‘) 9 #print(url) 10 j = 1 11 houses = houses.select(‘.shop_list .clearfix h4 a‘) 12 page_information = [] # 数据存储 13 for house in houses: 14 try: 15 demo_url = house[‘href‘] 16 url = r‘https://xm.esf.fang.com‘ + demo_url + ‘?channel=1,2&psid=1_{}_60‘.format(j) # 每一页中有多少套房子 17 # 获取当前页中每套房子的信息 18 information = get_house(url) 19 print(‘正在爬取第{}页第{}套房子···‘.format(i,j),end=‘\r‘) 20 page_information.append(information) 21 j += 1 22 time.sleep(0.5) # 预防爬取频繁,防止ip被封 23 except Exception as e: 24 print(‘-------->‘,e) 25 #将爬取的数据转换为DataFrame格式 26 df = pd.DataFrame(page_information) 27 #df.to_csv(‘house_information.csv‘) 28 return df 29 #get_page(1)
1 # 正式爬取数据并保存为csv数据 2 3 df = pd.DataFrame() # 创建一个空的DataFrame 4 name_csv = ‘house_information_‘ 5 for i in range(1,101): # 总共爬取100页数据 6 try: 7 df_get = get_page(i) 8 df = df.append(df_get) 9 print(df) 10 except Exception as e: 11 print(‘------->‘,e) 12 if i/100 == 1: 13 df.to_csv(name_csv+str(i)+‘.csv‘) 14 df = pd.DataFrame() # 清空当前爬取完成的数据,防止内存溢出

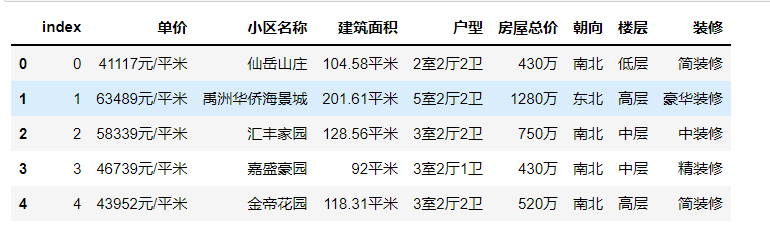
1 import numpy as np 2 import pandas as pd 3 4 data = pd.read_csv(r‘house_information.csv‘) # 如果用pandas打不开数据,可以使用记事本打开把编码格式改成utf-8另存 5 data.head()
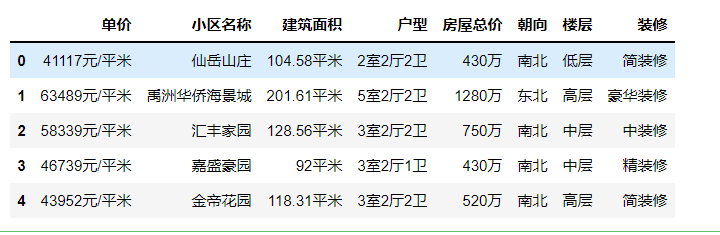
1 data.drop(‘index‘,axis=1,inplace=True) # 删除index列(用del更方便) 2 data.head()
1 # Series的extract支持正则匹配抽取,返回的值是字符串 2 data[[‘室‘,‘厅‘,‘卫‘]] = data[‘户型‘].str.extract(r‘(\d+)室(\d+)厅(\d+)卫‘) 3 4 # 把字符串格式转化为float,并删除户型 5 data[‘室‘] = data[‘室‘].astype(float) 6 data[‘厅‘] = data[‘厅‘].astype(float) 7 data[‘卫‘] = data[‘卫‘].astype(float) 8 del data[‘户型‘] 9 data.head()
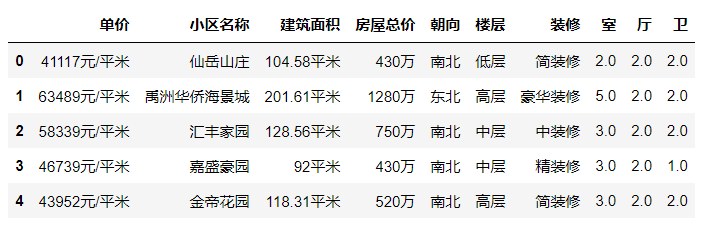
1 # 将建筑面积后的平方米去除,并将数据类型改成浮点型 2 data[‘建筑面积‘] = data[‘建筑面积‘].map(lambda e:e.replace(‘平米‘,‘‘))# Series中的map 3 data[‘建筑面积‘] = data[‘建筑面积‘].astype(float) 4 data.head()
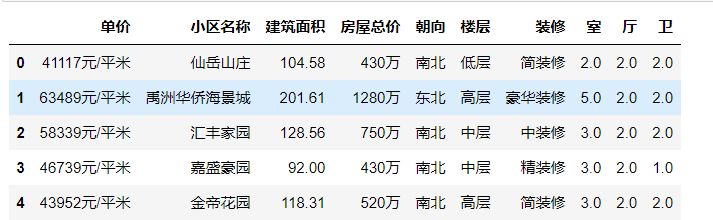
1 # 将单价后的元/平米去除,并将数据类型改成浮点型 2 data[‘单价‘] = data[‘单价‘].map(lambda e:e.replace(r‘元/平米‘,‘‘)) 3 data[‘单价‘] = data[‘单价‘].astype(float) 4 data.head()
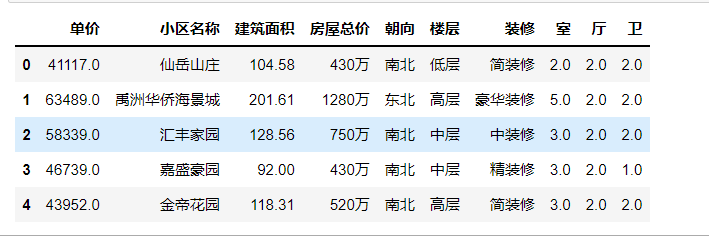
1 # 将房屋总价后的万去除,并将数据类型改成浮点型 2 data[‘房屋总价‘] = data[‘房屋总价‘].map(lambda e:e.replace(‘万‘,‘‘)) 3 data[‘房屋总价‘] = data[‘房屋总价‘].astype(float) 4 data.head()
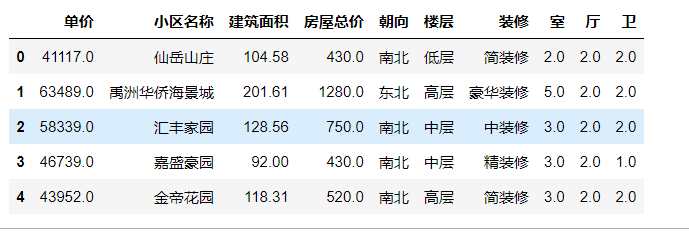
1 # 使用pd.get_dummies() 量化数据 2 data_direction = pd.get_dummies(data[‘朝向‘]) 3 data_direction.head()
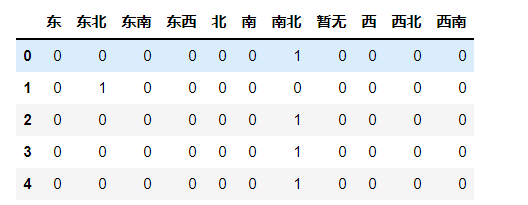
1 # 使用pd.get_dummies() 量化数据 2 data_floor = pd.get_dummies(data[‘楼层‘]) 3 data_floor.head()
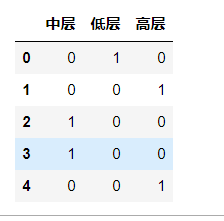
1 # 使用pd.get_dummies() 量化数据 2 data_decoration = pd.get_dummies(data[‘装修‘]) 3 data_decoration.head()
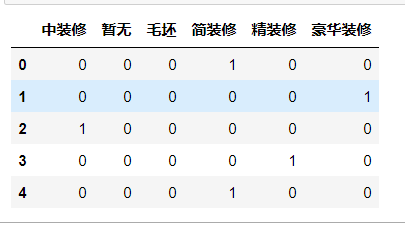
1 # 使用pd.concat矩阵拼接,axis=1:水平拼接 2 data = pd.concat([data,data_direction,data_floor,data_decoration],axis=1)
1 # 拼接后的列名 2 data.columns

1 # 特征帅选 2 del data[‘小区名称‘] 3 del data[‘朝向‘] 4 del data[‘楼层‘] 5 del data[‘装修‘] 6 del data[‘东西‘] 7 del data[‘南北‘] 8 del data[‘暂无‘] # 两列都删除 9 del data[‘中层‘] # 多重共线性问题(线性回归) 10 del data[‘中装修‘] 11 data.columns

1 data.head()
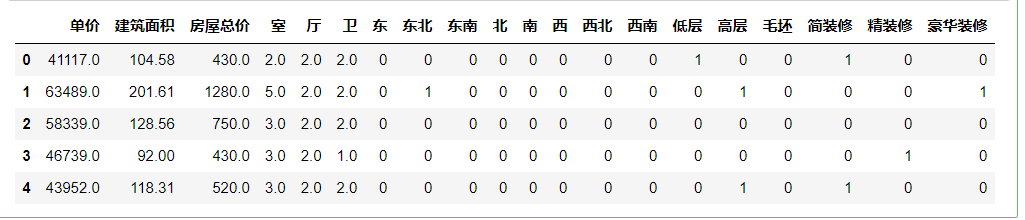
1 data.info() # 发现 室厅卫中 有缺失值
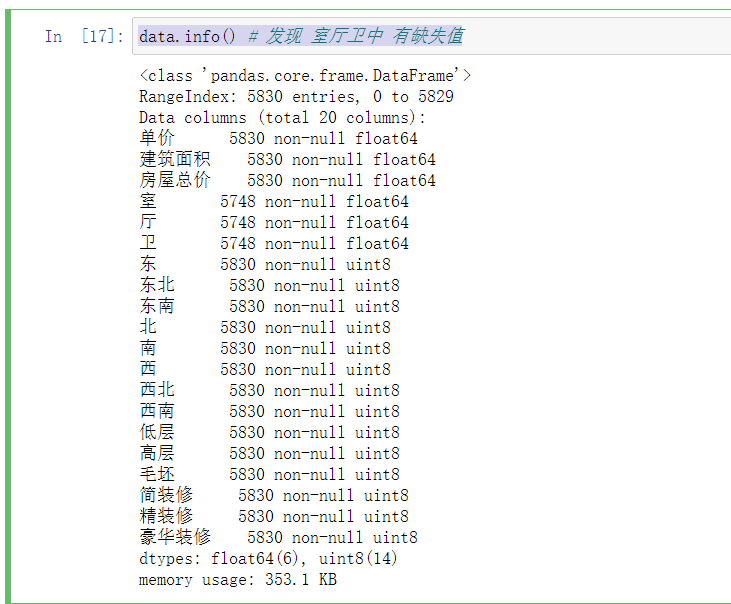
1 import matplotlib.pyplot as plt 2 area = data[‘建筑面积‘] 3 price = data[‘房屋总价‘] 4 plt.scatter(area,price) 5 plt.show() # 有离群点数据,对线性分析不利,需要过滤
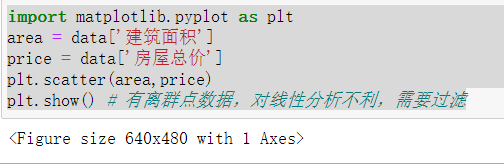
1 df = data[data[‘建筑面积‘] <=300] # 正常住宅面积小于等于300平米 2 area = df[‘建筑面积‘] 3 price = df[‘房屋总价‘] 4 #print(area.count()) #过滤后的数据量 5 plt.scatter(area,price) 6 plt.xlabel("area") 7 plt.ylabel("price") 8 plt.show()
1 # 先根据建筑面积和房屋总价训练模型(一元线性回归) 2 from sklearn.linear_model import LinearRegression 3 linear = LinearRegression() 4 area = np.array(area).reshape(-1,1) # 这里需要注意新版的sklearn需要将数据转换为矩阵才能进行计算 5 price = np.array(price).reshape(-1,1) 6 # 训练模型 7 model = linear.fit(area,price) 8 # 打印截距和回归系数 9 print(model.intercept_, model.coef_)

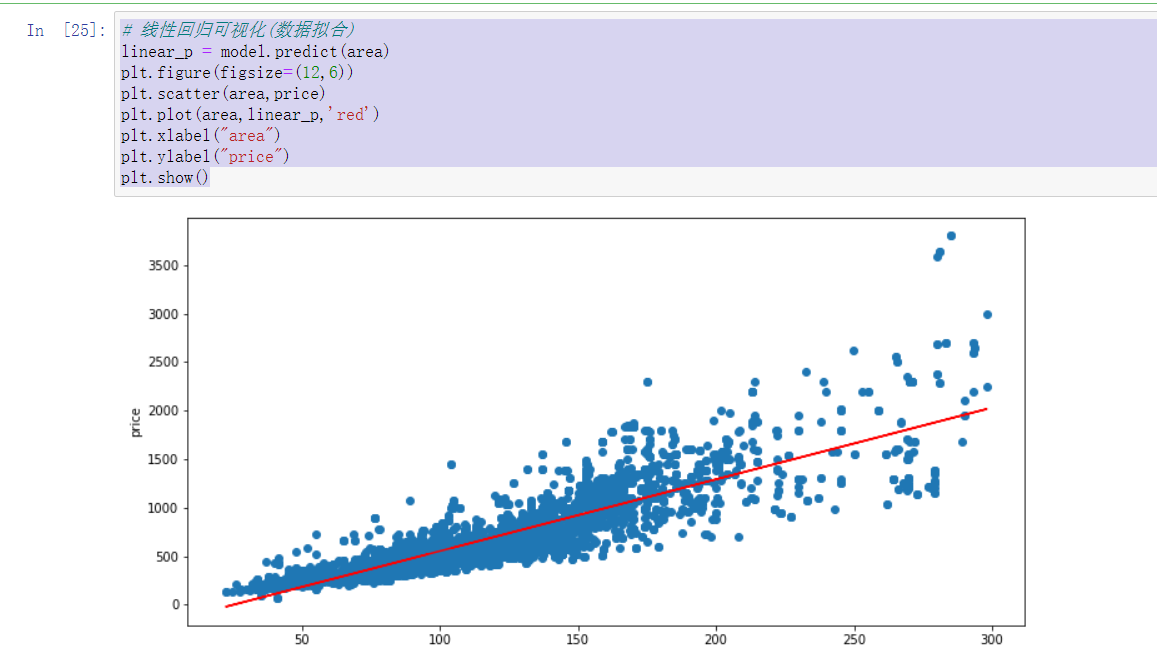
1 # 线性回归可视化(数据拟合) 2 linear_p = model.predict(area) 3 plt.figure(figsize=(12,6)) 4 plt.scatter(area,price) 5 plt.plot(area,linear_p,‘red‘) 6 plt.xlabel("area") 7 plt.ylabel("price") 8 plt.show()
1 cols = [‘建筑面积‘,‘室‘, ‘厅‘, ‘卫‘, ‘东‘, ‘东北‘, ‘东南‘, ‘北‘, ‘南‘, ‘西‘, 2 ‘西北‘, ‘西南‘, ‘低层‘, ‘高层‘, ‘毛坯‘, ‘简装修‘, ‘精装修‘, ‘豪华装修‘]
1 X = df[cols] 2 X.head()
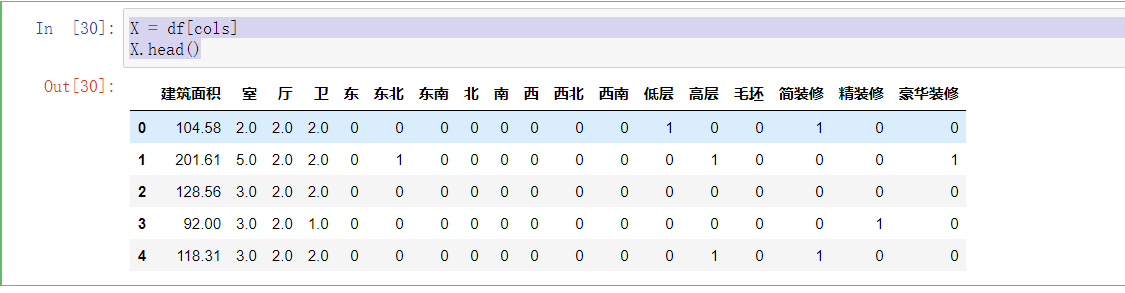
1 y = df[‘房屋总价‘] 2 y.head()
1 print(type(X)) 2 print(type(y)) 3 # 使用train_test_split进行交叉验证 4 from sklearn.model_selection import train_test_split 5 x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=12) 6 print(x_train.shape,y_train.shape) 7 print(x_test.shape,y_test.shape)
1 # 模型训练 2 linear = LinearRegression() 3 model = linear.fit(x_train,y_train) 4 print(model.intercept_, model.coef_)

1 # 模型性能评分 2 price_end = model.predict(x_test) 3 score = model.score(x_test,y_test) 4 print("模型得分:",score)# 一般模型在0.6以上就表现的不错

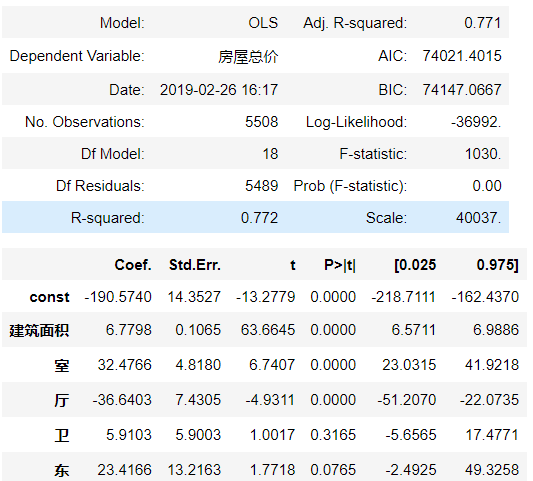
1 # 使用假设验证法,选出最佳特征组合 2 cols = [‘建筑面积‘,‘室‘, ‘厅‘, ‘卫‘, ‘东‘, ‘东北‘, ‘东南‘, ‘北‘, ‘南‘, ‘西‘, 3 ‘西北‘, ‘西南‘, ‘低层‘, ‘高层‘, ‘毛坯‘, ‘简装修‘, ‘精装修‘, ‘豪华装修‘] 4 import statsmodels.api as sm 5 Y = df[‘房屋总价‘] 6 X = df[cols] 7 X_ = sm.add_constant(X) #增加一列值为1的const列,保证偏置项的正常 8 #print(X_) 9 # 使用最小平方法 10 result = sm.OLS(Y,X_) 11 # 使用fit方法进行计算 12 summary = result.fit() 13 # 调用summary2方法打印出假设验证信息(性能指标) 14 summary.summary2() # R-squared:模型评分 AIC:组合完越小越好
#特征超过16个将发生异常
1 import itertools 2 3 list1 = [1, 2,3, 4, 5,6,7,8,9,10,11,12,13,14,15,16] 4 list2 = [] 5 for i in range(1, len(list1)+1): 6 iter1 = itertools.combinations(list1, i) 7 list2.append(list(iter1)) 8 #print(list2)
# 使用itertools,找出AIC最小值的特征组合作为模型训练的特征
# 寻找最小AIC值的特征组合
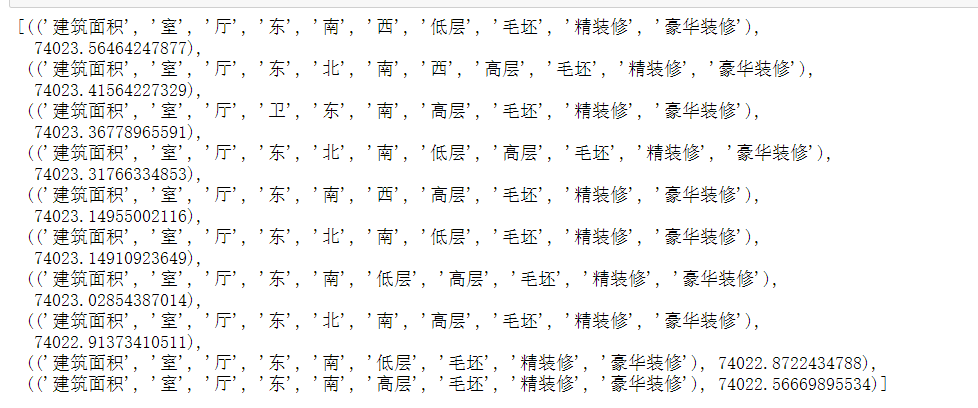
1 import itertools 2 fileds = [‘建筑面积‘,‘室‘, ‘厅‘, ‘卫‘, ‘东‘,‘北‘, ‘南‘, ‘西‘,‘低层‘, ‘高层‘, ‘毛坯‘, ‘简装修‘, ‘精装修‘, ‘豪华装修‘] 3 acis = {} 4 for i in range(1,len(fileds)+1): 5 for virables in itertools.combinations(fileds,i): #从fileds中随机选择i个特征机型组合,返回的virables为元组类型 6 x1 = sm.add_constant(df[list(virables)]) 7 x2 = sm.OLS(Y,x1) 8 res = x2.fit() 9 acis[virables] = res.aic # AIC评分越小越好
1 from collections import Counter 2 # 对字典进行统计 3 counter = Counter(acis) 4 # 降序选出AIC最小的10个数,也就是最佳特征组合 5 counter.most_common()[-10:]
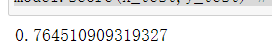
1 # 接下来使用AIC值最小的特征组合进行预测 2 col2 = [‘建筑面积‘, ‘室‘, ‘厅‘, ‘东‘, ‘南‘, ‘高层‘, ‘毛坯‘, ‘精装修‘, ‘豪华装修‘] 3 X = df[col2] 4 y = df[‘房屋总价‘] 5 x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=13) 6 linear = LinearRegression() 7 model = linear.fit(x_train,y_train) 8 model.score(x_test,y_test) # 模型性能有所提高,但是提升的不明显
现在我可以根据给定的最佳特征组合进行预测房价
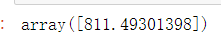
1 # 假设我要买一套房子(想想就觉得很美),房子面积120平米,3室,1厅,南面,高层,精装修 2 my_house = [120,3,1,0,1,1,0,1,0] #根据col2特征 3 my_house = np.array(my_house).reshape(-1,1).T 4 #print(x_test) 5 model.predict(my_house)# 预测价格
完整代码:
1 import requests 2 from bs4 import BeautifulSoup 3 # requests返回网页内容 4 res = requests.get(r‘https://xm.esf.fang.com/house-a0352/‘) 5 #res.text 6 7 # BeautifulSoup解析网页 8 soup = BeautifulSoup(res.text,‘html.parser‘) # 使用 HTML.parser 解析器 9 10 11 12 def get_house(url): 13 ‘获取页面中每个房子的信息‘ 14 information = {} # 存储房屋所有信息 15 res = requests.get(url) 16 soup = BeautifulSoup(res.text,‘html.parser‘) 17 18 # 获取户型、建筑面积、单价、朝向、楼层、装修情况 19 houses = soup.select(‘.tab-cont-right .trl-item1‘) 20 #print(houses) 21 for house in houses: 22 me = house.text.strip().split(‘\n‘) 23 information[me[1]] = me[0].strip() 24 25 # 获取小区名字 26 name = soup.select(‘.rcont .blue‘) 27 information[‘小区名称‘] = name[0].text 28 29 # 获取房屋总价 30 price = soup.select(‘.trl-item‘) 31 information[‘房屋总价‘] = price[0].text 32 print(information) 33 34 # 函数测试 35 get_house("https://xm.esf.fang.com/chushou/3_346676334.htm?channel=1,2&psid=1_15_60") # 每一页中房子的url(注意:链接可能失效) 36 37 38 39 def get_page(n): 40 ‘分页爬取数据‘ 41 for i in range(1,n+1): # n:爬取页数 42 url = r‘https://xm.esf.fang.com/house-a0352/i3{}/‘.format(i) # 总共多少页 43 res = requests.get(url) 44 houses = BeautifulSoup(res.text,‘html.parser‘) 45 print(url) 46 j = 1 47 houses = houses.select(‘.shop_list .clearfix h4 a‘) # 获取每套房子的href 48 for house in houses: 49 try: 50 demo_url = house[‘href‘] 51 url = r‘https://xm.esf.fang.com‘ + demo_url + ‘?channel=1,2&psid=1_{}_60‘.format(j) # 每一页中有多少套房子 52 # 获取当前页面中每套房子的信息 53 #get_house(url) 54 j += 1 55 except Exception as e: 56 print(‘-------->‘,e) 57 get_page(1) 58 59 60 61 import requests 62 from bs4 import BeautifulSoup 63 64 def get_house(url): 65 ‘获取页面中每个房子的信息‘ 66 information = {} # 存储房屋所有信息 67 res = requests.get(url) 68 soup = BeautifulSoup(res.text,‘html.parser‘) 69 70 # 获取户型、建筑面积、单价、朝向、楼层、装修情况 71 houses = soup.select(‘.tab-cont-right .trl-item1‘) 72 for house in houses: 73 m = house.text.strip().split(‘\n‘) 74 me = m[1] 75 if ‘朝向‘ in me: 76 me = me.strip(‘进门‘) 77 if ‘楼层‘in me: 78 me = me[0:2] 79 if ‘地上层数‘ in me: 80 me = ‘楼层‘ 81 if ‘装修程度‘ in me: 82 me = ‘装修‘ 83 information[me] = m[0].strip() 84 85 # 获取小区名字 86 name = soup.select(‘.rcont .blue‘) 87 information[‘小区名称‘] = name[0].text 88 89 # 获取房屋总价 90 price = soup.select(‘.trl-item‘) 91 information[‘房屋总价‘] = price[0].text 92 return information 93 94 # 函数测试 95 get_house("https://xm.esf.fang.com/chushou/3_346676334.htm?channel=1,2&psid=1_15_60") # 每一页中房子的url 96 97 98 99 import pandas as pd 100 import time 101 102 def get_page(i): 103 ‘分页爬取数据‘ 104 url = r‘https://xm.esf.fang.com/house-a0352/i3{}/‘.format(i) # 总共多少页 105 res = requests.get(url) 106 houses = BeautifulSoup(res.text,‘html.parser‘) 107 #print(url) 108 j = 1 109 houses = houses.select(‘.shop_list .clearfix h4 a‘) 110 page_information = [] # 数据存储 111 for house in houses: 112 try: 113 demo_url = house[‘href‘] 114 url = r‘https://xm.esf.fang.com‘ + demo_url + ‘?channel=1,2&psid=1_{}_60‘.format(j) # 每一页中有多少套房子 115 # 获取当前页中每套房子的信息 116 information = get_house(url) 117 print(‘正在爬取第{}页第{}套房子···‘.format(i,j),end=‘\r‘) 118 page_information.append(information) 119 j += 1 120 time.sleep(0.5) # 预防爬取频繁,防止ip被封 121 except Exception as e: 122 print(‘-------->‘,e) 123 #将爬取的数据转换为DataFrame格式 124 df = pd.DataFrame(page_information) 125 #df.to_csv(‘house_information.csv‘) 126 return df 127 #get_page(1) 128 129 130 131 132 # 正式爬取数据并保存为csv数据 133 134 df = pd.DataFrame() # 创建一个空的DataFrame 135 name_csv = ‘house_information_‘ 136 for i in range(1,101): # 总共爬取100页数据 137 try: 138 df_get = get_page(i) 139 df = df.append(df_get) 140 print(df) 141 except Exception as e: 142 print(‘------->‘,e) 143 if i/100 == 1: 144 df.to_csv(name_csv+str(i)+‘.csv‘) 145 df = pd.DataFrame() # 清空当前爬取完成的数据,防止内存溢出 146 147 148 149 import numpy as np 150 import pandas as pd 151 152 data = pd.read_csv(r‘house_information.csv‘) # 如果用pandas打不开数据,可以使用记事本打开把编码格式改成utf-8另存 153 data.head() 154 155 156 data.drop(‘index‘,axis=1,inplace=True) # 删除index列(用del更方便) 157 data.head() 158 159 160 # Series的extract支持正则匹配抽取,返回的值是字符串 161 data[[‘室‘,‘厅‘,‘卫‘]] = data[‘户型‘].str.extract(r‘(\d+)室(\d+)厅(\d+)卫‘) 162 163 164 # 把字符串格式转化为float,并删除户型 165 data[‘室‘] = data[‘室‘].astype(float) 166 data[‘厅‘] = data[‘厅‘].astype(float) 167 data[‘卫‘] = data[‘卫‘].astype(float) 168 del data[‘户型‘] 169 data.head() 170 171 172 173 # 将建筑面积后的平方米去除,并将数据类型改成浮点型 174 data[‘建筑面积‘] = data[‘建筑面积‘].map(lambda e:e.replace(‘平米‘,‘‘))# Series中的map 175 data[‘建筑面积‘] = data[‘建筑面积‘].astype(float) 176 data.head() 177 178 179 180 # 将单价后的元/平米去除,并将数据类型改成浮点型 181 data[‘单价‘] = data[‘单价‘].map(lambda e:e.replace(r‘元/平米‘,‘‘)) 182 data[‘单价‘] = data[‘单价‘].astype(float) 183 data.head() 184 185 186 187 # 将房屋总价后的万去除,并将数据类型改成浮点型 188 data[‘房屋总价‘] = data[‘房屋总价‘].map(lambda e:e.replace(‘万‘,‘‘)) 189 data[‘房屋总价‘] = data[‘房屋总价‘].astype(float) 190 data.head() 191 192 193 194 # 使用pd.get_dummies() 量化数据 195 data_direction = pd.get_dummies(data[‘朝向‘]) 196 data_direction.head() 197 198 199 200 # 使用pd.get_dummies() 量化数据 201 data_floor = pd.get_dummies(data[‘楼层‘]) 202 data_floor.head() 203 204 205 206 # 使用pd.get_dummies() 量化数据 207 data_decoration = pd.get_dummies(data[‘装修‘]) 208 data_decoration.head() 209 210 211 212 # 使用pd.concat矩阵拼接,axis=1:水平拼接 213 data = pd.concat([data,data_direction,data_floor,data_decoration],axis=1) 214 215 216 217 # 拼接后的列名 218 data.columns 219 220 221 # 特征帅选 222 del data[‘小区名称‘] 223 del data[‘朝向‘] 224 del data[‘楼层‘] 225 del data[‘装修‘] 226 del data[‘东西‘] 227 del data[‘南北‘] 228 del data[‘暂无‘] # 两列都删除 229 del data[‘中层‘] # 多重共线性问题(线性回归) 230 del data[‘中装修‘] 231 data.columns 232 233 234 235 data.head() 236 237 data.info() # 发现 室厅卫中 有缺失值 238 239 240 # 删除缺失值 241 data.dropna(inplace=True) 242 data.info() 243 244 245 import matplotlib.pyplot as plt 246 area = data[‘建筑面积‘] 247 price = data[‘房屋总价‘] 248 plt.scatter(area,price) 249 plt.show() # 有离群点数据,对线性分析不利,需要过滤 250 251 252 253 df = data[data[‘建筑面积‘] <=300] # 正常住宅面积小于等于300平米 254 area = df[‘建筑面积‘] 255 price = df[‘房屋总价‘] 256 #print(area.count()) #过滤后的数据量 257 plt.scatter(area,price) 258 plt.xlabel("area") 259 plt.ylabel("price") 260 plt.show() 261 262 263 264 265 # 先根据建筑面积和房屋总价训练模型(一元线性回归) 266 from sklearn.linear_model import LinearRegression 267 linear = LinearRegression() 268 area = np.array(area).reshape(-1,1) # 这里需要注意新版的sklearn需要将数据转换为矩阵才能进行计算 269 price = np.array(price).reshape(-1,1) 270 # 训练模型 271 model = linear.fit(area,price) 272 # 打印截距和回归系数 273 print(model.intercept_, model.coef_) 274 275 276 277 # 线性回归可视化(数据拟合) 278 linear_p = model.predict(area) 279 plt.figure(figsize=(12,6)) 280 plt.scatter(area,price) 281 plt.plot(area,linear_p,‘red‘) 282 plt.xlabel("area") 283 plt.ylabel("price") 284 plt.show() 285 286 287 288 289 cols = [‘建筑面积‘,‘室‘, ‘厅‘, ‘卫‘, ‘东‘, ‘东北‘, ‘东南‘, ‘北‘, ‘南‘, ‘西‘, 290 ‘西北‘, ‘西南‘, ‘低层‘, ‘高层‘, ‘毛坯‘, ‘简装修‘, ‘精装修‘, ‘豪华装修‘] 291 292 X = df[cols] 293 X.head() 294 295 y = df[‘房屋总价‘] 296 y.head() 297 298 print(type(X)) 299 print(type(y)) 300 # 使用train_test_split进行交叉验证 301 from sklearn.model_selection import train_test_split 302 x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=12) 303 print(x_train.shape,y_train.shape) 304 print(x_test.shape,y_test.shape) 305 306 307 308 # 模型训练 309 linear = LinearRegression() 310 model = linear.fit(x_train,y_train) 311 print(model.intercept_, model.coef_) 312 313 314 315 # 模型性能评分 316 price_end = model.predict(x_test) 317 score = model.score(x_test,y_test) 318 print("模型得分:",score)# 一般模型在0.6以上就表现的不错 319 320 321 322 # 使用假设验证法,选出最佳特征组合 323 cols = [‘建筑面积‘,‘室‘, ‘厅‘, ‘卫‘, ‘东‘, ‘东北‘, ‘东南‘, ‘北‘, ‘南‘, ‘西‘, 324 ‘西北‘, ‘西南‘, ‘低层‘, ‘高层‘, ‘毛坯‘, ‘简装修‘, ‘精装修‘, ‘豪华装修‘] 325 import statsmodels.api as sm 326 Y = df[‘房屋总价‘] 327 X = df[cols] 328 X_ = sm.add_constant(X) #增加一列值为1的const列,保证偏置项的正常 329 #print(X_) 330 # 使用最小平方法 331 result = sm.OLS(Y,X_) 332 # 使用fit方法进行计算 333 summary = result.fit() 334 # 调用summary2方法打印出假设验证信息(性能指标) 335 summary.summary2() # R-squared:模型评分 AIC:组合完越小越好 336 337 338 339 340 import itertools 341 342 list1 = [1, 2,3, 4, 5,6,7,8,9,10,11,12,13,14,15,16] 343 list2 = [] 344 for i in range(1, len(list1)+1): 345 iter1 = itertools.combinations(list1, i) 346 list2.append(list(iter1)) 347 #print(list2) 348 349 350 351 352 import itertools 353 fileds = [‘建筑面积‘,‘室‘, ‘厅‘, ‘卫‘, ‘东‘,‘北‘, ‘南‘, ‘西‘,‘低层‘, ‘高层‘, ‘毛坯‘, ‘简装修‘, ‘精装修‘, ‘豪华装修‘] 354 acis = {} 355 for i in range(1,len(fileds)+1): 356 for virables in itertools.combinations(fileds,i): #从fileds中随机选择i个特征机型组合,返回的virables为元组类型 357 x1 = sm.add_constant(df[list(virables)]) 358 x2 = sm.OLS(Y,x1) 359 res = x2.fit() 360 acis[virables] = res.aic # AIC评分越小越好 361 362 363 364 from collections import Counter 365 # 对字典进行统计 366 counter = Counter(acis) 367 # 降序选出AIC最小的10个数,也就是最佳特征组合 368 counter.most_common()[-10:] 369 370 371 372 373 # 接下来使用AIC值最小的特征组合进行预测 374 col2 = [‘建筑面积‘, ‘室‘, ‘厅‘, ‘东‘, ‘南‘, ‘高层‘, ‘毛坯‘, ‘精装修‘, ‘豪华装修‘] 375 X = df[col2] 376 y = df[‘房屋总价‘] 377 x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=13) 378 linear = LinearRegression() 379 model = linear.fit(x_train,y_train) 380 model.score(x_test,y_test) # 模型性能有所提高,但是提升的不明显 381 382 383 384 385 # 假设我要买一套房子(想想就觉得很美),房子面积120平米,3室,1厅,南面,高层,精装修 386 my_house = [120,3,1,0,1,1,0,1,0] #根据col2特征 387 my_house = np.array(my_house).reshape(-1,1).T 388 #print(x_test) 389 model.predict(my_house)# 预测价格
五,总结
经过对数据的分析与可视化,可以得到:使用假设验证法,选出最佳特征组合,打印出假设验证性能指标,对预期的目标已经达到了,这设计多特征模型训练机器学习的模型结果表现不错。
原文:https://www.cnblogs.com/csy123/p/14929316.html