
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.metrics import pairwise_distances_argmin from sklearn.datasets import load_sample_image from sklearn.utils import shuffle
china = load_sample_image("china.jpg") china china.dtype china.shape china[0][0] newimage = china.reshape((427 * 640,3)) import pandas as pd pd.DataFrame(newimage).drop_duplicates().shape plt.figure(figsize=(15,15)) plt.imshow(china) flower = load_sample_image("flower.jpg") plt.figure(figsize=(15,15)) plt.imshow(flower)
n_clusters = 64 china = np.array(china, dtype=np.float64) / china.max() w, h, d = original_shape = tuple(china.shape) assert d == 3 image_array = np.reshape(china, (w * h, d)) china = np.array(china, dtype=np.float64) / china.max() w, h, d = original_shape = tuple(china.shape) w h d assert d == 3 d_ = 5 assert d_ == 3, "一个格子中的特征数目不等于3种" image_array = np.reshape(china, (w * h, d)) image_array image_array.shape a = np.random.random((2,4)) a a.reshape((4,2)) np.reshape(a,(4,2)) np.reshape(a,(2,2,2)) np.reshape(a,(3,2))
image_array_sample = shuffle(image_array, random_state=0)[:1000] kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample) kmeans.cluster_centers_
labels = kmeans.predict(image_array) labels.shape
image_kmeans = image_array.copy() for i in range(w*h): image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
image_kmeans pd.DataFrame(image_kmeans).drop_duplicates().shape
image_kmeans = image_kmeans.reshape(w,h,d) image_kmeans.shape
centroid_random = shuffle(image_array, random_state=0)[:n_clusters] labels_random = pairwise_distances_argmin(centroid_random,image_array,axis=0) labels_random.shape len(set(labels_random)) image_random = image_array.copy() for i in range(w*h): image_random[i] = centroid_random[labels_random[i]] image_random = image_random.reshape(w,h,d) image_random.shape
plt.figure(figsize=(10,10)) plt.axis(‘off‘) plt.title(‘Original image (96,615 colors)‘) plt.imshow(china) plt.figure(figsize=(10,10)) plt.axis(‘off‘) plt.title(‘Quantized image (64 colors, K-Means)‘) plt.imshow(image_kmeans) plt.figure(figsize=(10,10)) plt.axis(‘off‘) plt.title(‘Quantized image (64 colors, Random)‘) plt.imshow(image_random) plt.show()
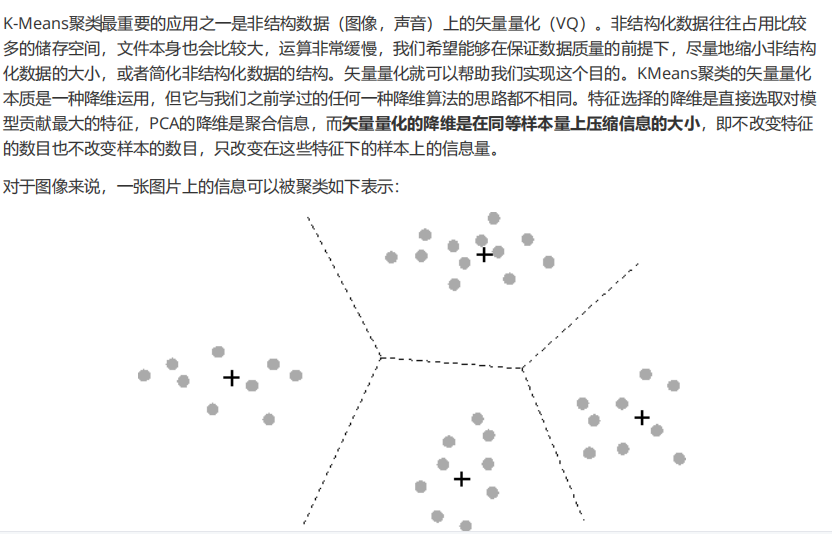
机器学习sklearn(64):算法实例(二十一)聚类(四)KMeans (三) 案例:聚类算法用于降维,KMeans的矢量量化应用
原文:https://www.cnblogs.com/qiu-hua/p/14948046.html