一、数据类型简介
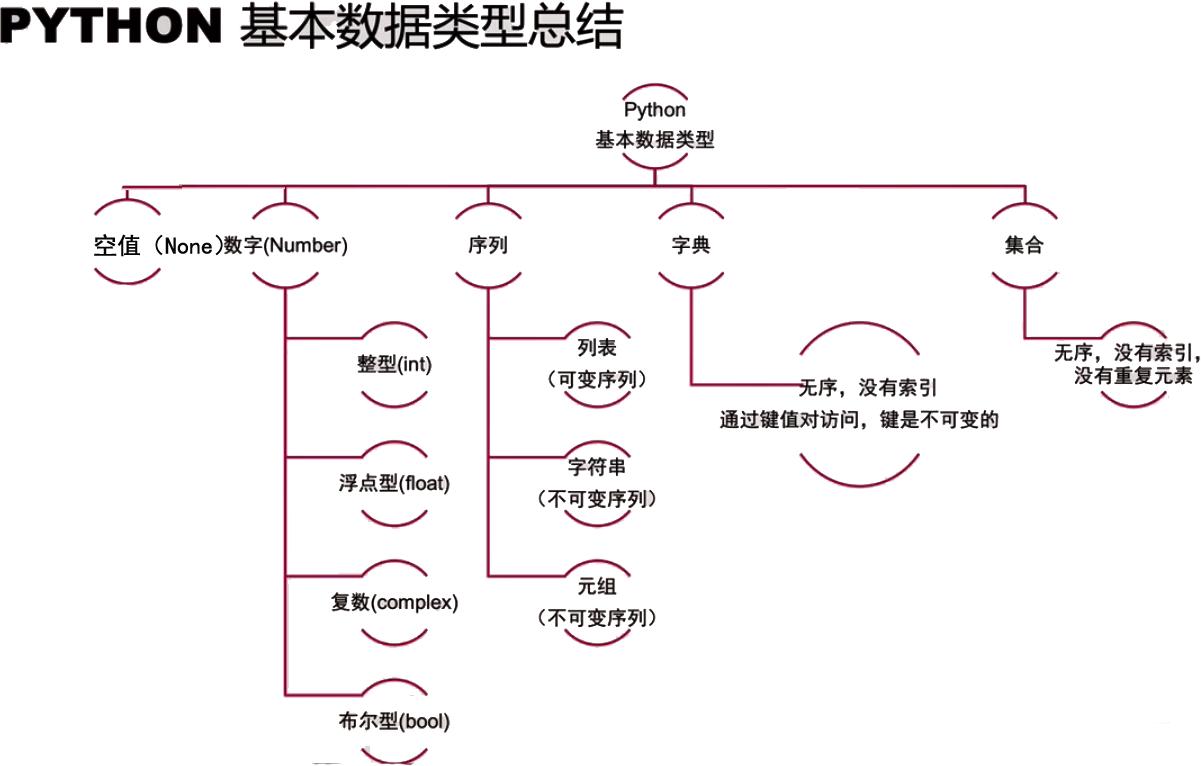
demo = None # 空值
demo1 = 1234 # 整形
demo2 = 12.34 # 浮点型
demo3 = True or False # 布尔型
# 序列
demo4 = "苹果橙子芒果李子桃子" # 字符串
demo5 = ["白菜", "番茄", 111, ["白萝卜", "胡萝卜"]] # 列表
demo6 = ("aaa", "bbb", 222, "ccc", "ddd") # 元祖
demo7 = {"菊花", "樱花", "油菜花", "兰花", "月季花"} # 集合
demo8 = {"丹尼": "小狗", "佩琪": "小猪", "佩德罗": "小马"} # 字典
二、数字的运算(整形、浮点型、复数、布尔型)
单词:【 int:整形;float:浮点型;Complex:复数;bool:布尔型;randint:整数部分】
1)整形:正整数、负整数与零;如12、-12、0。
进制转换:将十进制数(29)转换成二进制数。把给定的十进制数29除以2,商为14,所得的余数1是二进制数的最低位的数码,再将14除以2,商为7,余数为0。再将7除以2,商为3,余数为1,再将3除以2,商为1,余数为1,再将1除以2,商为0,余数为1是二进制数的最高位的数码,其结果为:11101,再在前面增加0b,用来识别是哪个进制数字,最终为0b11101(八进制在加0o,十六进制加0x,十进制不需要加代号)。HEX,Hexadecimal,十六进制。 DEC,Decimal,十进制。 OCT,Octal,八进制。 BIN,Binary,二进制。

num1=bin(10) #十进制转二进制
num2=oct(10) #十进制转八进制
num3=hex(10) #十进制转十六进制
num4=int(0b0110) #二进制转十进制,其他进制若想相互转换,可先转成十进制。
print(num1)
print(num2)
print(num3)
print(num4)
>>0b1010
>>0o12
>>0xa
>>6
2)浮点型:带小数的数字;如3.14、-3.14。
浮点型后面保留2位小数,使用round()函数,或使用%格式化输出。
3)复数:complex([real[,imag]])
complex(3,4).real 3.0
complex(3,4).imaf 4.0
4)布尔型:True 和 False。布尔值可以进行and、or和not运算,and和or分别用&和 | 表示;在数字类型下,当布尔类型为0、None的时候,返回False。
三、序列的(增删改查+其他内置函数用法)
1)“序列”的运算
2)“列表(list)”的常用内置函数用法
demo = ["hp", "dell", "thinkpad", "hp", "lenovo", "mac", "神州"]
# 增(append,extend,insert)
demo.append("华为") # 在列表的末端增加单个元素。
# demo.extend("轻轻的我来了!") # 将元素中的内容拆分后,作为增加的元素,在列表的末端增加元素。
# demo.insert(2, "133") # 在具体位置处增加元素,“2”插入元素的位置序号。
# 删(del,pop,remove)
# demo.pop() # 括号中无位置序号时,在列表末端删除掉一个元素。
# demo.pop(3) # 括号中有位置序号时,在列表指定序号处删除掉一个元素。
# demo.remove("hp") # 删除指定的元素。
# del demo[4] # 删除指定序号元素
# 补充:pop函数有返回值
# fhz = demo.pop(3) # 通过索引,删除位置序号为3的“元素”,并且返回删除的“值”,通过fhz变量接收。
# print(fhz)
>> hp
# 改 # demo[1] = "变变变" # 1)改变指定位置元素为新元素。 # # for i in range(len(demo)): #2)在不知道位置的情况下,改变某元素的值。 # if "lenovo" in demo[i]: # demo[i] = "悟空" # 查/切片---用新变量去接收返回值 j = demo[4] # 查找出列表中位置序号为4的元素。 j = demo[1:3] # 查找出列表中位置序号为1至3的元素 j = demo[1:6:2] # 查找出列表中位置序号为1至6的元素,并隔1个元素输出 j = demo[::-1] # 倒序输出,-1为步长
print(demo) print(j)
>>[‘hp‘, ‘dell‘, ‘thinkpad‘, ‘hp‘, ‘lenovo‘, ‘mac‘, ‘神州‘, ‘华为‘] >>[‘hp‘, ‘dell‘, ‘thinkpad‘, ‘hp‘, ‘lenovo‘, ‘mac‘, ‘神州‘, ‘轻‘, ‘轻‘, ‘的‘, ‘我‘, ‘来‘, ‘了‘, ‘!‘] >>[‘hp‘, ‘dell‘, ‘133‘, ‘thinkpad‘, ‘hp‘, ‘lenovo‘, ‘mac‘, ‘神州‘] >>[‘hp‘, ‘dell‘, ‘thinkpad‘, ‘hp‘, ‘lenovo‘, ‘mac‘] >>[‘hp‘, ‘dell‘, ‘thinkpad‘, ‘lenovo‘, ‘mac‘, ‘神州‘] >>[‘dell‘, ‘thinkpad‘, ‘hp‘, ‘lenovo‘, ‘mac‘, ‘神州‘] >>[‘hp‘, ‘dell‘, ‘thinkpad‘, ‘hp‘, ‘mac‘, ‘神州‘] >>[‘hp‘, ‘变变变‘, ‘thinkpad‘, ‘hp‘, ‘lenovo‘, ‘mac‘, ‘神州‘] >>[‘hp‘, ‘dell‘, ‘thinkpad‘, ‘hp‘, ‘悟空‘, ‘mac‘, ‘神州‘] >>lenovo >>[‘dell‘, ‘thinkpad‘] >>[‘dell‘, ‘hp‘, ‘mac‘] >>[‘华为‘, ‘神州‘, ‘mac‘, ‘lenovo‘, ‘hp‘, ‘thinkpad‘, ‘dell‘, ‘hp‘]
demo = ["hp", "dell", "thinkpad", "hp", "lenovo", "mac", "神州"] # 其他内置函数: # 无返回值(reverse,sort) # demo.reverse() # 将列表中的元素倒序输出。 # demo.sort() # 将列表中的元素按照ASCII码表中顺序排列(1-9,a-z,A-Z)
# demo.sort(reverse=True) # 将上面的序列反过来
# 有返回值(count,index)
qt = demo.count("hp") # 计算它的参数在列表中出现的次数,并将次数返回。
qt = demo.index("hp") # 返回它的参数在列表中的位置,返回元素序号;#若有多个元素相同,此为只返回首端起第一个。
qt = demo.index("hp", 1, 6) # 在序号1和序号2范围内,返回列表中元素位置。 #若有多个元素相同,此为只返回首端起第一个。
print(demo) print(qt) >>[‘神州‘, ‘mac‘, ‘lenovo‘, ‘hp‘, ‘thinkpad‘, ‘dell‘, ‘hp‘] >>[‘dell‘, ‘hp‘, ‘hp‘, ‘lenovo‘, ‘mac‘, ‘thinkpad‘, ‘神州‘]
>>[‘神州‘,‘thinkpad‘,‘mac‘,‘lenovo‘,‘hp‘,‘hp‘, ‘dell‘]
>>2
>>0
>>3
3)“字符串(str)”的常用内置函数用法
4)“元祖(tuple)”的常用内置函数用法
四、字典
五、集合
原文:https://www.cnblogs.com/lovezhuzhu1314/p/14845108.html