1 基本数据管理
1.1一个示例
(1)定义向量,造数据框
manage<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","US","UK","UK","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,24,34,88)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,2,NA,1)
lendership<-data.frame(manager,country,gender,age,q1,q2,q3,q4,q5)
(2)创建新变量
方法一:使用$
q6<-q4+q5
lendership$q6<-lendership$q4+lendership$q5
方法二:transform()为数据表添加列
lendership<-transform(lendership,q7=q4+q5,q8=q1+q2)
(3)变量重编码
方式一:使用$
lendership$age[lendership$age==88]<-NA
lendership$agecat[lendership$age>50]<-"Elder"
lendership$agecat[lendership$age>40 & lendership$age<=50]<-"Middle Aged"
lendership$agecat[lendership$age<40]<-"Young"
方式二:使用within
lendership1<-within(lendership,{
agecat<-NA
agecat[age>50]<-"Elder"
agecat[age>40 & age<=50]<-"Middle Aged"
agecat[age<=40]<-"Young"
})

(4)变量重命名
方式一:弹出数据编辑器
fix(lendership)
方式二:使用names(),只能索引一列一列的改,不方便
names(lendership)[1]<-"manager1"
解释:names里面是表名,[1]代表修改第一列
方式三:导入编辑包plyr,使用函数rename()
library(plyr)
lendership<-rename(lendership,c(manager1="ID",q1="qq1"))

2 缺失值
2.1 识别缺失值函数is.na()
y<-c(1,2,NA)
is.na(y)
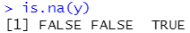
2.2 重编码某些值为缺失值
lendership$age[lendership$age==88]<-NA
2.3 缺失值参与计算会怎样
y<-c(1,2,NA)
z<-y[1]+y[2]+y[3]
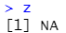
z<-sum(y,na.rm = T) #na.rm = T意思是有缺失值就移除
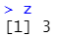
2.4 移除含有缺失值的观测(行)
newdata<-na.omit(lendership) #删除含有缺失值的行

3 日期值
3.1 日期值的读入 as.Date
mydata<-as.Date(c("2008-06-11","2018-08-08"))

3.2 日期值的格式
strdata<-c("01/05/1996","08/22/1998")
mydata1<-as.Date(strdata,"%m/%d/%Y") #指定日期格式
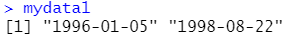
3.3 系统日期与当前日期
系统日期:Sys.Date()
当前日期:date()

3.4 日期值的输出格式
today<-Sys.Date()
format(today,format="%B %d %Y") #调整日期输出格式format,%B表示月份文字输出

3.5 日期值的间隔计算
方式一:按天计算
startdata<-as.Date("1996-11-22")
enddata<-as.Date("2021-07-02")
days<-enddata-startdata

方式二:按周计算,使用函数difftim()
difftime(enddata,startdata,units = "weeks")

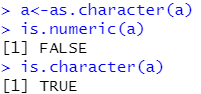
4 类型转换
4.1 is.xxx()函数,用来判断类型

4.2 as.xxx()函数,用来转换
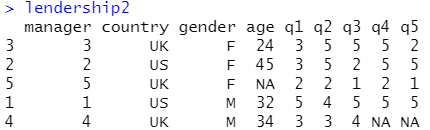
5 数据排序
lendership2<-lendership[order(lendership$gender,lendership$age),]
6 数据集操作
数据输入:
manage<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","US","UK","UK","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,24,34,88)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,2,NA,1)
lendership<-data.frame(manager,country,gender,age,q1,q2,q3,q4,q5)
leader_a<-data.frame(manage,country,gender,age)
leader_b<-data.frame(manage,q1,q2,q3,q4,q5)
leader_b<-leader_b[order(-leader_b$manage),]


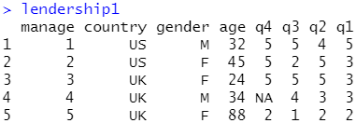
6.1 数据集(框)的合并 merge()
lendership1<-merge(leader_a,leader_b,by="manage") #通过主键manage合并
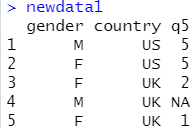
6.2 数据集(框)取子集
(1)保留变量
方式一:newdata<-lendership[,c(5:9)]

方式二: myvar<-c("gender","country","q5")
newdata1<-lendership[myvar]
(2)删除变量
方式一:前面加负号 -
newdata<-newdata[c(-2,-3)]
方式二:赋值NULL
newdata$q3<-NULL

(3)选入观测(保留行)
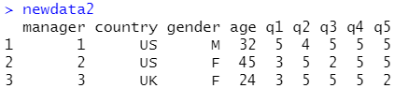
newdata2<-lendership[1:3,] #选择1到3行
newdata3<-lendership[lendership$gender=="M" & lendership$age>30,]
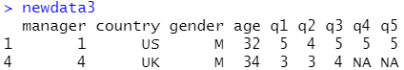
(4)subset函数
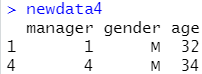
newdata4<-subset(lendership,gender=="M" & age>25,select=c("manager","gender","age"))
解释:gender=="M" & age>25这是选择保留的行,select是选择保留的列
若出现了错误:选择了未定义的列

修正:检查自己的列变量名字是否写错
(5)使用SQL语句操作数据集(框)
加载包:library(sqldf)
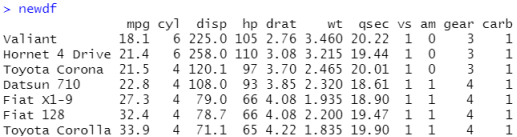
语句:newdf<-sqldf("select * from mtcars where carb=1 order by mpg",row.names = T)
R语言--基本数据管理(变量、缺失值、日期值、数据类型转换、数据框)
原文:https://www.cnblogs.com/YY-zhang/p/14964699.html