概要:提取数据的基本特征

更多参考: http://pandas.pydata.org/
Pandas是Python第三方库,提供高性能易用数据类型和分析工具,Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。
常用引用方法:
import pandas as pd
[/code]
### 7.1对pandas库的理解
与numpy的区别

该库基于numpy提供了两个新的数据类型:Series, DataFrame
基于上述数据类型有各类操作:基本操作、运算操作、特征类操作、关联类操作
### 7.2 Series类型(一维)
Series类型由一组 **数据及与之相关的数据索引** 组成

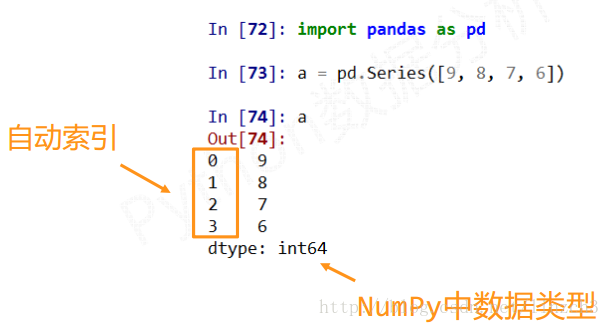
实例1:
实例2:
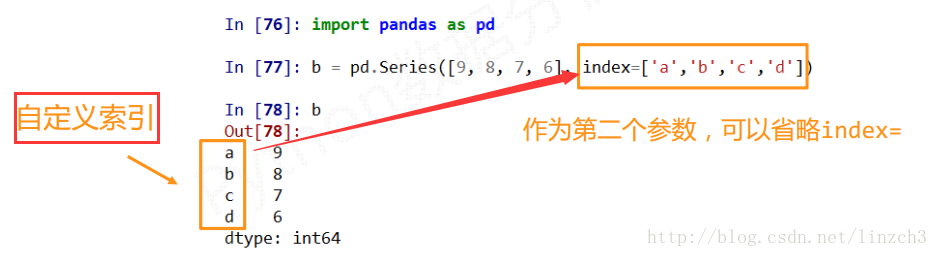
Series类型可以由如下类型创建:
? Python列表,index与列表元素个数一致
? 标量值,index表达Series类型的尺寸
? Python字典,键值对中的“键”是索引,index从字典中进行选择操作
? ndarray,索引和数据都可以通过ndarray类型创建
? 其他函数,range()函数等
实例:



**如何理解该类型**
Series是 **一维带“标签”数组** (Series类型包括 **index和values** 两部分)
index_0 —–> data_a**(索引 与 值 一一对应)**
Series基本操作类似 **ndarray和字典** ,根据 **索引对齐** 进行运算(而不是像numpy一般基于维度进行运算)
**Series类型的基本操作**
1. 使用 .index 获取索引,使用 .value 获取数据

2.自动索引 与 自定义索引并存(但 **不能混合使用** )

3.Series类型的操作类似ndarray类型:
? 索引方法相同,采用[]
? NumPy中运算和操作可用于Series类型 **(运算和操作结果仍然是Series类型)**
? 可以通过自定义索引的列表进行切片( **切片后的结果仍然是Series类型)**
? 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片( **切片后的结果仍然是Series类型)**

4.Series类型的操作类似Python字典类型:
? 通过自定义索引访问
? 保留字in操作(只会判断自定义索引,不会判断自动索引)
? 使用.get()方法

5.Series类型的对齐问题:

Series类型在运算中会 **自动对齐不同索引** 的数据
6.Series类型的.name属性:
Series对象和索引都可以有一个名字,存储在属性.name中
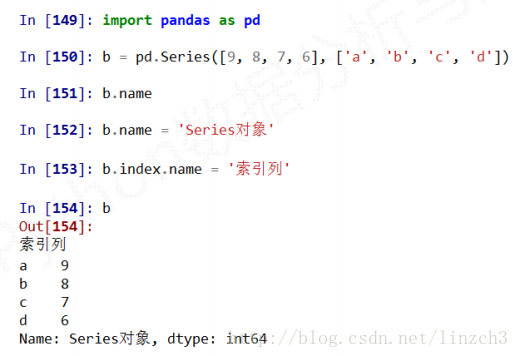
7.Series类型的修改:
Series对象可以随时修改并即刻生效

### 7.3 DataFrame类型(二维)
DataFrame类型由 **共用相同索引** 的一组列组成

**axis =0 /axis = 1的介绍**

DataFrame是一个 **表格型** 的数据类型, **每列值类型** 可以不同 **(类似于Excel)**
DataFrame既有 **行索引、也有列索引**
DataFrame常用于表达 **二维数据** ,但可以表达多维数据
**创建DataFrame类型**
DataFrame类型可以由如下类型创建:
? 二维ndarray对象
? 由一维ndarray、列表、字典、元组或Series构成的字典
? Series类型
? 其他的DataFrame类型



实例分析:
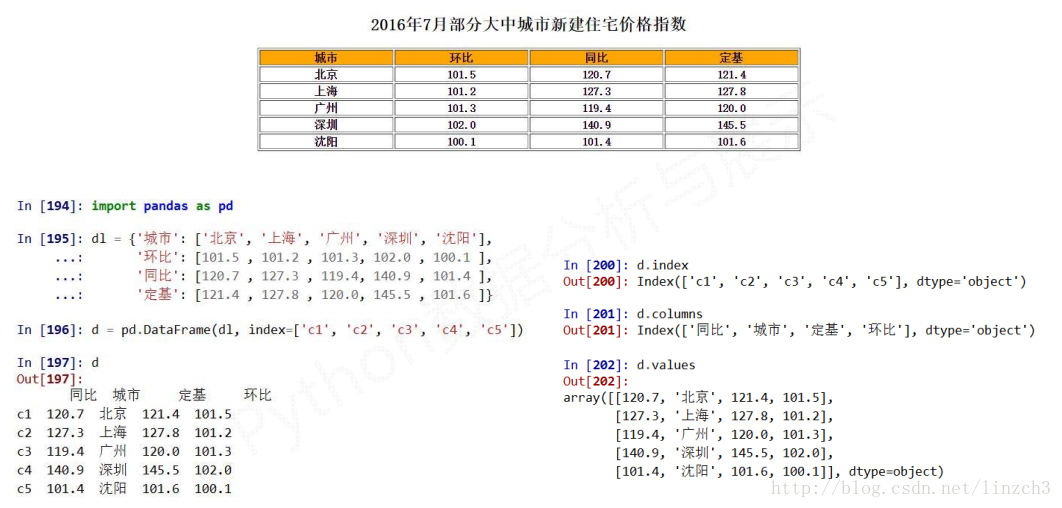
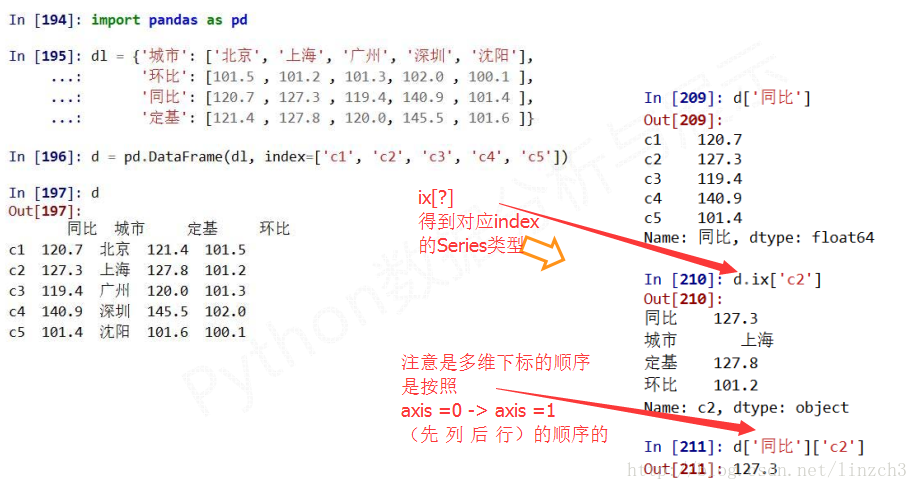
**对DataFrame的理解**
DataFrame是 **二维带“标签”数组** ,DataFrame基本操作类似Series, **依据行列索引**

### 7.4 pandas的数据类型操作
数据类型操作 <– 等价–> **如何改变Series和DataFrame对象?**
->增加或重排:重新索引
->删除:drop
#### **重新索引**
**.reindex()** 能够改变或重排Series和DataFrame索引
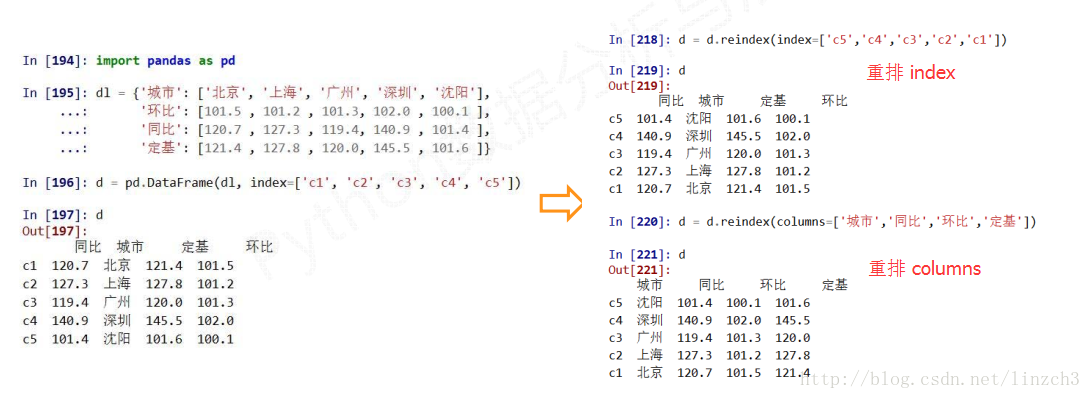
参数解释

**关于索引**
Series和DataFrame的索引是Index类型,Index对象是 **不可修改类型**

index类型的常用方法
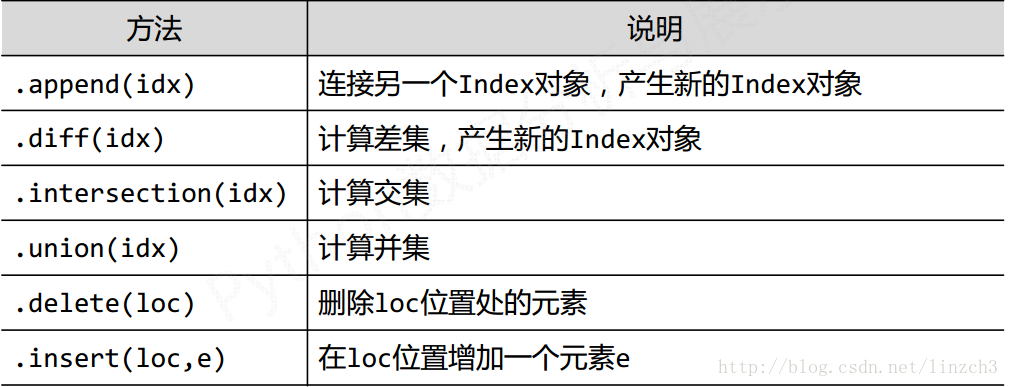

pandas通过操作索引来操作dataframe的数据集。
panda通过索引来实现对一组数据的操作。
#### **删除指定索引对象**
.drop()能够删除Series和DataFrame指定行或列索引
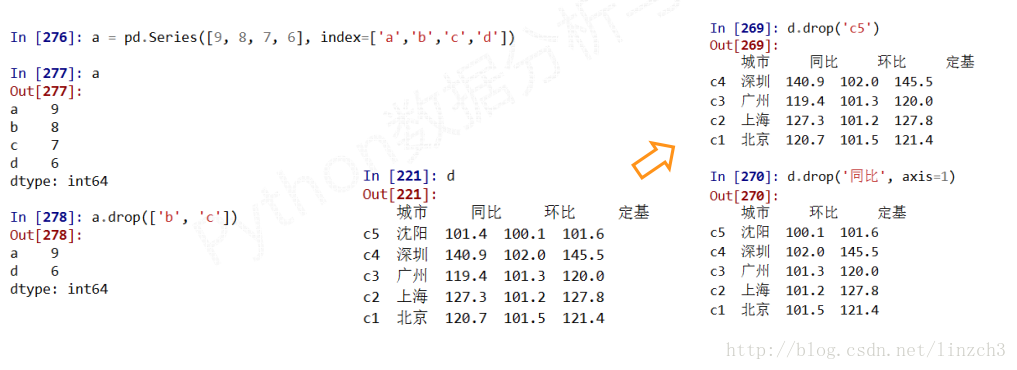
删除列时要指定axis=1(默认axis=0)
### 7.5 pandas的数据类型运算
#### 算术运算法则:
算术运算根据行列索引,补齐后运算,运算默认产生浮点数
补齐时缺项填充NaN (空值)
二维和一维、一维和零维间为 **广播运算 _*_ ** (低维对象元素会作用到高维对象的每一个元素)*
采用+ ‐ * /符号进行的二元运算产生 **新的对象**

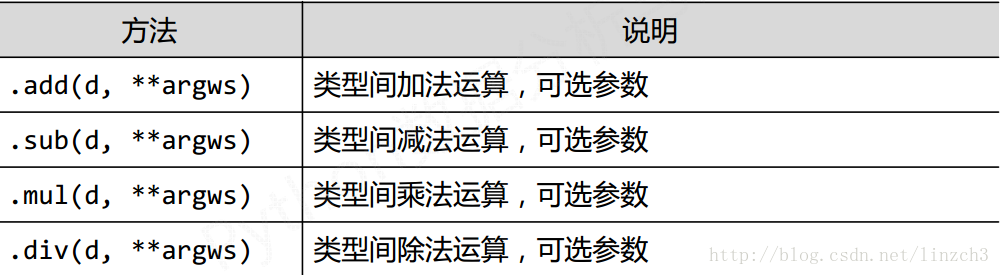
**方法形式的运算**
方法形式的运算可通过指定参数避免上面的NaN的产生

广播运算实例:


#### 比较运算法则:
比较运算只能比较相同索引的元素,不进行补齐
二维和一维、一维和零维间为广播运算
采用> < >= <= == !=等符号进行的二元运算产生布尔对象


### 单元小结

## 单元8:pandas数据特征分析
### 8.1数据排序
**.sort_index()** 方法在指定轴上 **根据索引进行排序** ,默认 **升序**


.sort_values()方法在指定轴上 **根据数值进行排序** ,默认 **升序**
使用方式:
```code
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
#by : axis轴上的某个索引或索引列表
[/code]

排序时,NaN永远都是在排序结果末尾(不管是升序 还是 降序)

### 8.2 数据的基本统计
基本统计函数
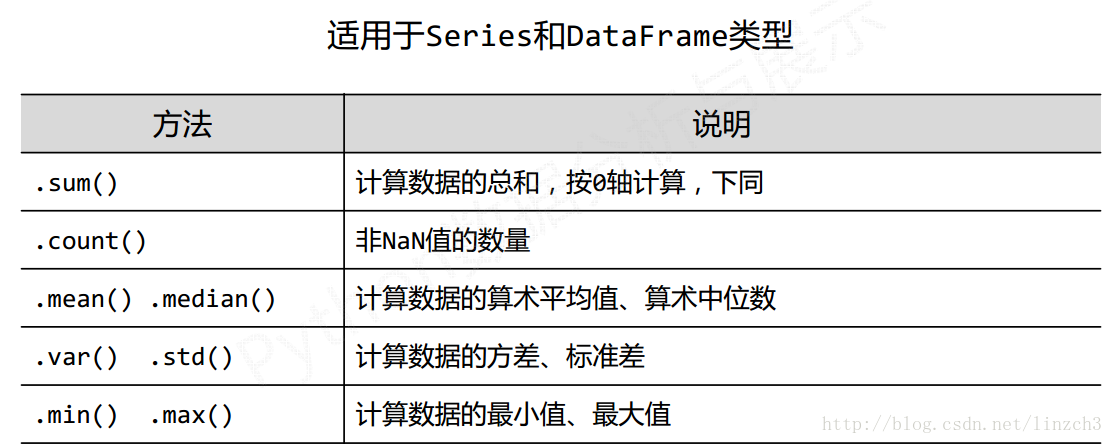


describe函数实例


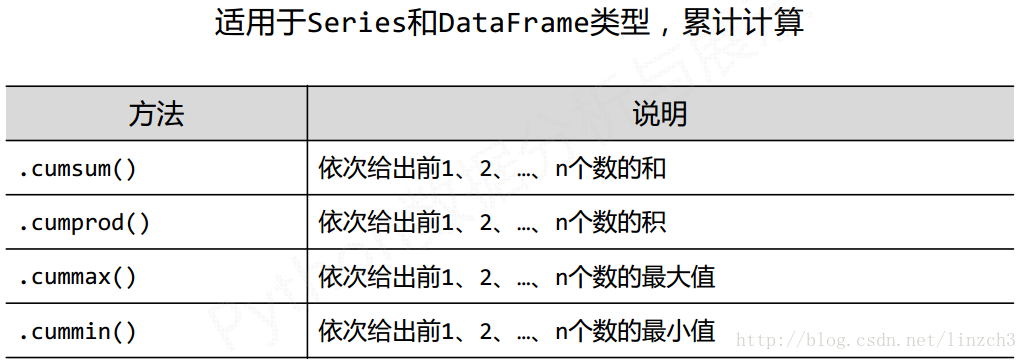
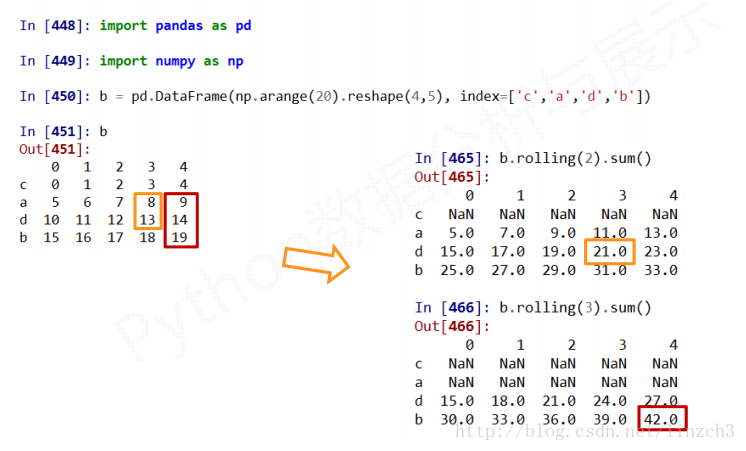
### 8.3 数据的累计统计分析
基本函数1:

基本函数2:
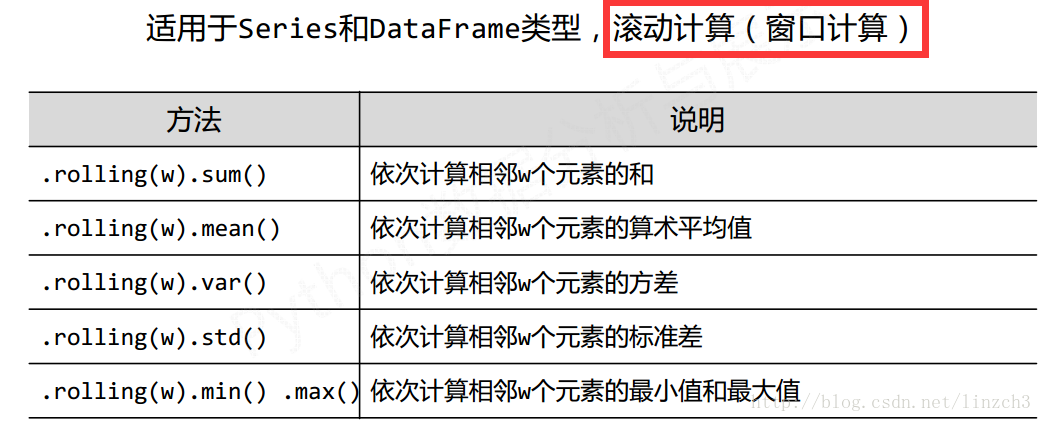
### 8.4 数据的相关分析
两个事物,表示为X和Y,协方差可判断它们之间的相关性:
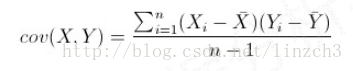
? 协方差>0, X和Y正相关( X增大,Y增大)
? 协方差<0, X和Y负相关(X增大,Y减小)
? 协方差=0, X和Y独立无关(X增大,Y无视)
两个事物,表示为X和Y,如何判断它们之间的存在相关性?
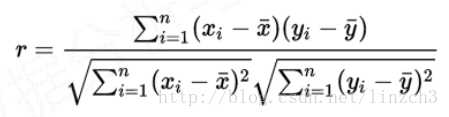
r取值范围[‐1,1]
…….r …………相关性
? 0.8‐1.0 极强相关
? 0.6‐0.8 强相关
? 0.4‐0.6 中等程度相关
? 0.2‐0.4 弱相关
? 0.0‐0.2 极弱相关或无相关

实例:房价增幅与M2增幅的相关性

### 单元小结

【MOOC】Python数据分析与展示-北京理工大学-【第三周】数据分析之概要
原文:https://www.cnblogs.com/nigulasiximegn/p/14977804.html