复习:在前面我们已经学习了Pandas基础,第二章我们开始进入数据分析的业务部分,在第二章第一节的内容中,我们学习了数据的清洗,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。而这一节,我们要做的是数据重构,数据重构依旧属于数据理解(准备)的范围。
# 导入基本库 import numpy as np import pandas as pd # 载入data文件中的:train-left-up.csv df = pd.read_csv(‘./data/train-left-up.csv‘) df.head()
text_left_up = pd.read_csv("./data/train-left-up.csv") text_left_down = pd.read_csv("./data/train-left-down.csv") text_right_up = pd.read_csv("./data/train-right-up.csv") text_right_down = pd.read_csv("./data/train-right-down.csv")
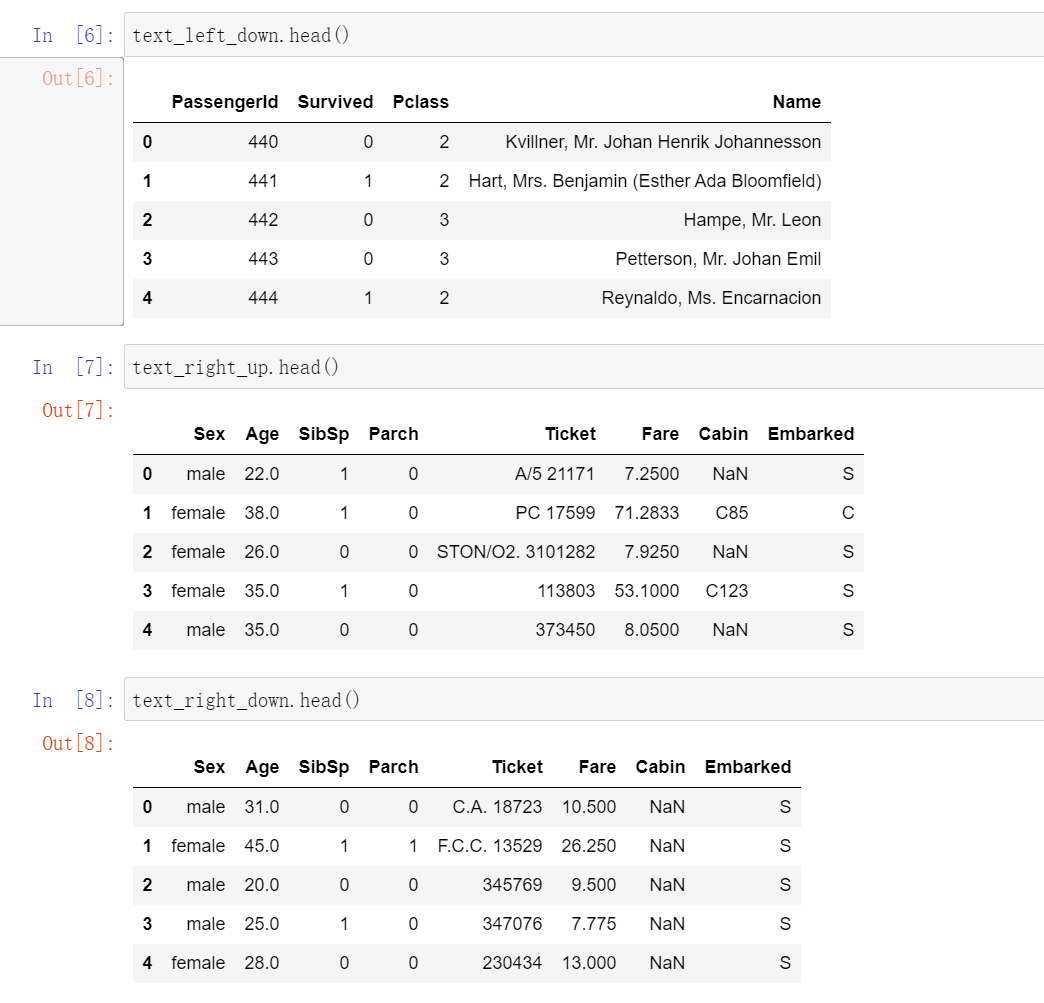
up_list = [text_left_up,text_right_up] result_up = pd.concat(up_list, axis=1) result_up.head()

down_list = [text_left_down,text_right_down] result_down = pd.concat(down_list,axis=1) result = pd.concat([result_up,result_down]) result.head()

result_up = text_left_up.join(text_right_up) result_down = text_left_down.join(text_right_down) result = result_up.append(result_down) result.head()

result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True) result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True) result = result_up.append(result_down) result.head()

result.to_csv(‘result.csv‘)
df = pd.read_csv(‘result.csv‘) df.head() unit_result = df.stack() unit_result.head()

unit_result.to_csv(‘unit_result.csv‘) test = pd.read_csv(‘unit_result.csv‘) test.head()
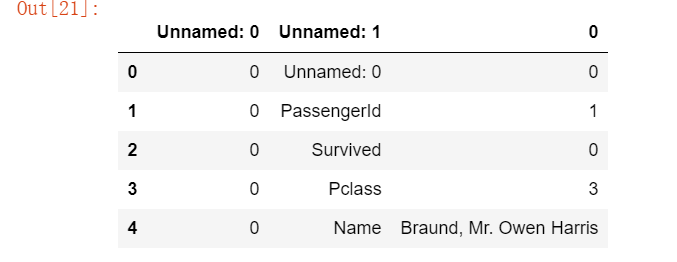
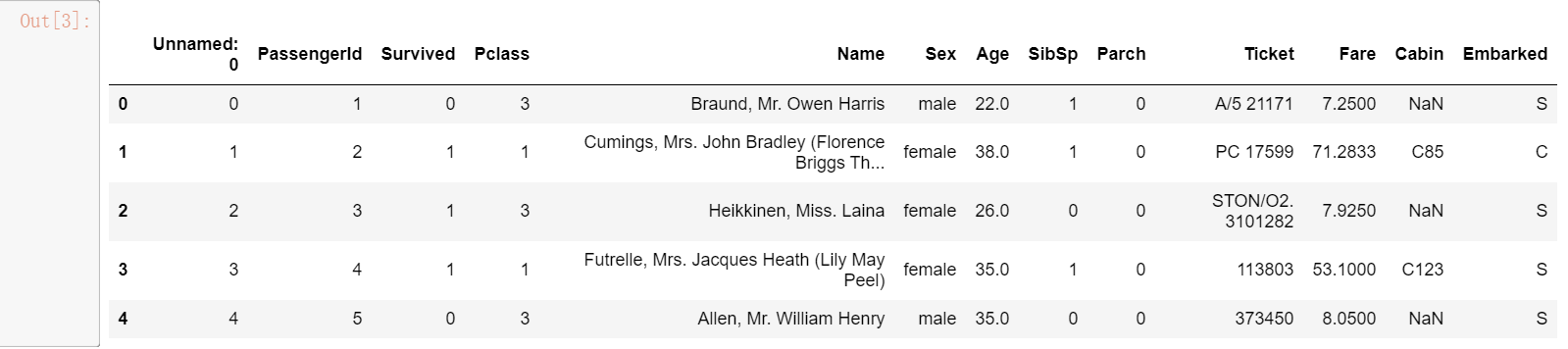
# 载入上一个任务人保存的文件中:result.csv,并查看这个文件 df = pd.read_csv(‘result.csv‘) df.head()
groupby的操作可以被分为3部分:
第一步,存储于series或DataFrame中的数据,根据不同的keys会被split(分割)为多个组。(这个分组可以按照不同的轴进行划分,axis=0按照行;axis=1按照列)
第二步,我们可以把函数例如mean等,apply在每一个组上,产生一个新的值。
第三步,函数产生的结果被combine(结合)为一个结果对象(result object)。
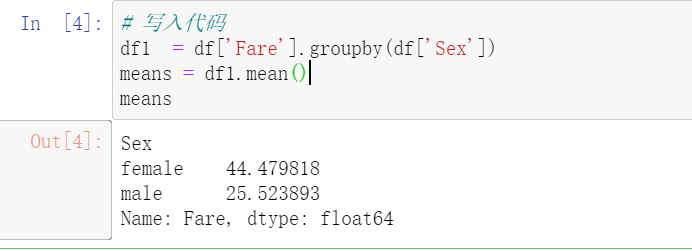
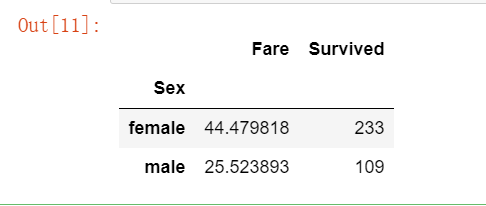
df1 = df[‘Fare‘].groupby(df[‘Sex‘]) means = df1.mean() means
survived_nums = df[‘Survived‘].groupby(df[‘Sex‘]).sum() survived_nums.head()

survived_pclass_nums = df[‘Survived‘].groupby(df[‘Pclass‘]).sum() survived_pclass_nums.head()

【思考】从任务二到任务三中,这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名。
df.groupby(‘Sex‘).agg({‘Fare‘: ‘mean‘, ‘Pclass‘: ‘count‘}).rename(columns= {‘Fare‘: ‘mean_fare‘, ‘Pclass‘: ‘count_pclass‘})
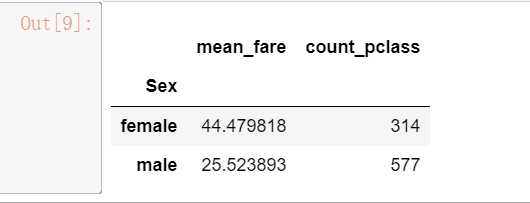
df.groupby([‘Pclass‘,‘Age‘])[‘Fare‘].mean().head()
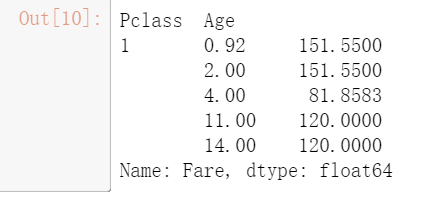
result = pd.merge(means,survived_nums,on=‘Sex‘) result
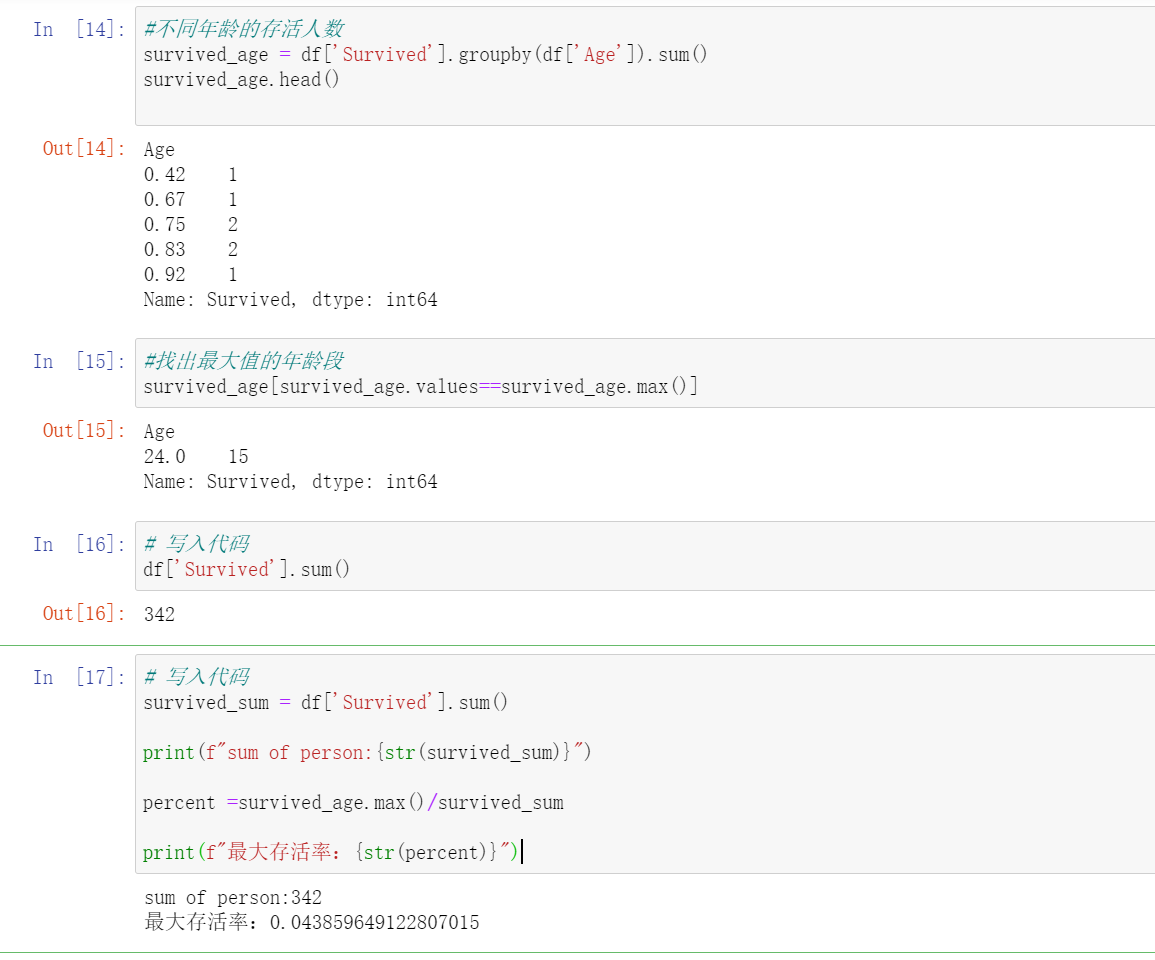
#不同年龄的存活人数 survived_age = df[‘Survived‘].groupby(df[‘Age‘]).sum() survived_age.head() #找出最大值的年龄段 survived_age[survived_age.values==survived_age.max()] survived_sum = df[‘Survived‘].sum() print(f"sum of person:{str(survived_sum)}")
percent =survived_age.max()/survived_sum print(f"最大存活率:{str(percent)}")
原文:https://www.cnblogs.com/learncode123/p/15012904.html