? Recurrent Neural NetWork (RNN) 用于处理序列数据,序列数据预测模型的特点是某一步的输出不仅依赖于这一步的输入,还依赖于其他步的输入或输出。传统的序列数据机器学习模型有Hidden Markov Model (隐马尔可夫模型)、Conditional Random Field (条件随机场)。近年来,深度学习模型又带来了RNN,标准RNN结构极为简单,只有一个tanh层,其模型结构见图1。
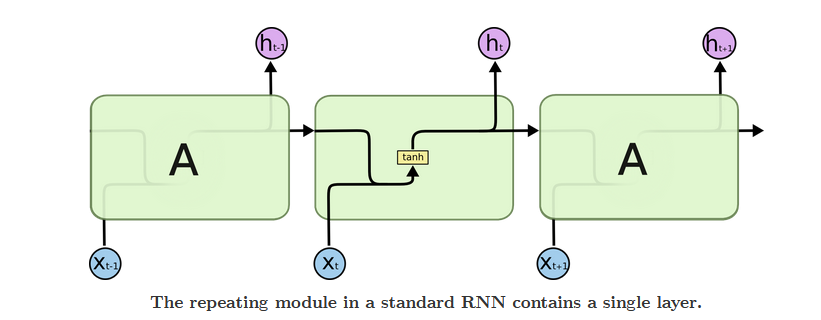
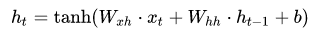
? Fig 1 The structure of RNN model
但传统的RNN存在着一个缺点:
? 当预测信息距离参考信息的时间跨度较远的时候,RNN就容易出现梯度消失的问题,之前的信息逐渐丢失,其保存的信息通常都是短期信息。反向传播过程中,当序列非常长的时候,RNN就会出现梯度消失的问题,导致前面的神经元权重不发生变化,没有训练效果;此外,当每项的偏导数都很大的时候,RNN也会出现梯度爆炸的现象。
? Long short term memory(LSTM)是一种特殊的RNN,可以解决梯度消失的问题,能学习到长期依赖关系。LSTM也是相同的链式结构,但他有四个神经网络层相互作用,模型见图2。
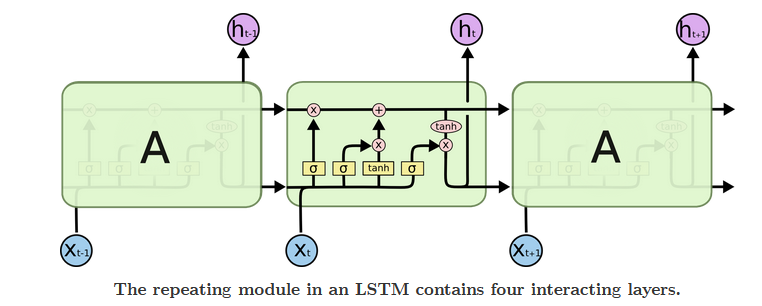
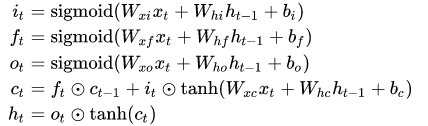
? Fig 2 The structure of LSTM model
? LSTM的核心是cell state,即贯穿顶部的水平线。它像传送带一样输送着长期信息,见图3。LSTM可以往这条线中添加或是移除信息,这都是由几种门结构控制,包括sigmoid(0不通过,1全部通过)、点乘运算。LSTM把训练信息分成长期信息 Ct 和短期信息 ht ,长期信息可以不受影响地传递很远。
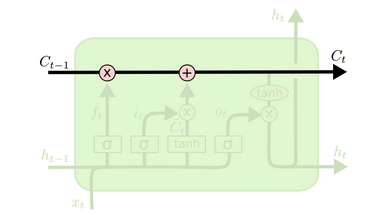
? Fig 3 The cell state of LSTM
下面介绍LSTM的核心神经网络层,即四大门。
? 遗忘门的输入是ht-1、Xt,它通过一个sigmoid激活函数来决定对长期信息 cell state 的保留和删除,随后输出一个介于0-1之间的值与Ct-1点乘,结构见图4。
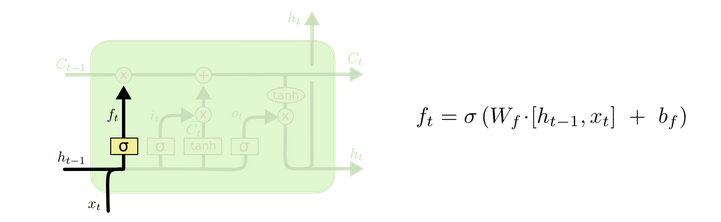
? Fig 4 The forget gate
? 下一步是决定应该往 cell state 中添加什么样的信息,由两部分组成。1. sigmoid layer负责决定更新的值 it,主要涉及更新哪些值及更新程度。2. tanh layer负责创建即将加入cell state的 新Ct。结构见图5。
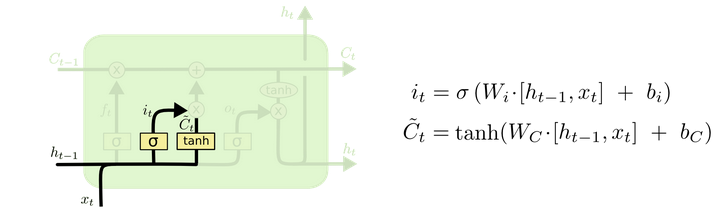
? Fig 5 The Input gate
? 对以上的信息进行更新,其中 ft 决定长期信息 Ct 的保留程度,it 决定本次更新的值,新Ct决定即将加入cell state的cell value。这里主要负责更新长期记忆 cell state 的信息,结构见图6。
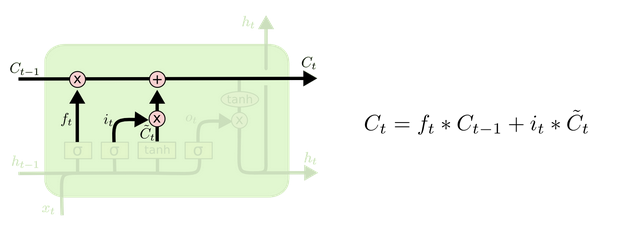
? Fig 6 The Update gate
? 最后是输出门,首先通过sigmoid层决定输出信息,然后通过tanh层激活cell state 及点乘前者输出来得到当前时刻的预测值ht,结构见图7。
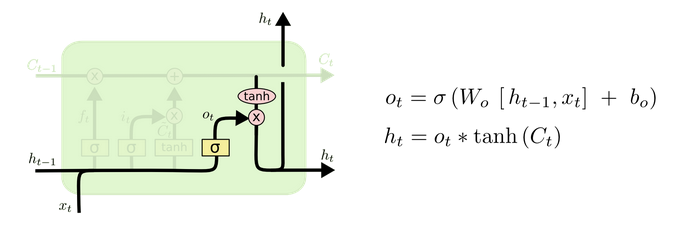
? Fig 7 The output gate
? 综合来看,更新门负责更新长期记忆,cell state;输出门结合当前时刻输入信息和 cell state 预测当前时刻的输出;而遗忘门、输入门则是给更新门打工(帮助更新长期记忆信息cell state)。
LSTM模型的Pytorch实现及输入/输出数据说明
nn.LSTM(input_size, hidden_size, num_layer, bias=True, batch_first=False, dropout=0, bidirectional=false)
self.lstm(input, (h_o, c_0))
‘‘‘ input description
输入数据按如下形式传入 (input, (h_0,c_0))
input: 序列数据格式
(seq, batch_size, input_size)
Default: 如果不提供h_0, c_0,那么默认为 0
h_0: 每个元素的初始隐藏状态
(num_layers * num_directions, batch_size, hidden_size)
c_0: 每个元素的初始单元格状态
(num_layers * num_directions, batch_size, hidden_size)
end ‘‘‘
class LSTM(nn.Module):
def __init__(self, input_size=2, hidden_layer_size=100, output_size=1):
super().__init__()
self.lstm = nn.LSTM(input_size,hidden_size,num_layer)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, input_seq):
# lstm处理序列数据,并传递到hidden_cell,输出lstm_out
# 输入数据格式:input(seq_len, batch, input_size)
# seq_len:每个序列的长度(time_step)
# batch_size:...
# input_size:输入矩阵特征数(即有几个类型的变量)
x, (h_n, c_n) = self.lstm(x) # h_0/c_0默认0
s,b,h = x.size()
x = x.reshape(s*b,h)
x = self.linear(x)
x = x.view(s,b,-1)
return predictions # 此处输出seq_len个时刻的输出,可以取索引/也可以用h_n选最后一个值
nn.LSTM(input_size,hidden_size,num_layer)
‘‘‘ output description
输出数据形式: output, (h_n, c_n)
output: (seq_len, batch_size, input_size) 包含所有time step的输出
h_n: 最后一个time_step的输出结果, (num_layers * num_directions, batch, hidden_size)
(default: num_directions==1)
c_n: 最后一个time_step的cell状态结果,一般用不到
(num_layers * num_directions, batch, hidden_size)
如果lstm双向,那么h_n\c_n第一维加倍
如果lstm不双向则代表各层数对应的c_n/h_n
end ‘‘‘
基于LSTM的股票价格预测(多个输入数据特征、每次预测一个time_step)
? 内容是基于股票的开盘价、关盘价、最高价、最低价、售卖量来预测每天的开盘价。具体是根据每五天的开盘价、关盘价、最高价、最低价、售卖量,预测下一天的开盘价。滑动选取训练集(间隔为1),进行训练和预测。原文取自https://blog.csdn.net/qq_31267769/article/details/111561678?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-8.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-8.control,现稍作改动。
? 这是一个多对一的问题,由5个时间序列的数据(特征数为5)预测下一个时间点的开盘价,对所有数据滑动预测下一个时间点的开盘价。其中模型部分,可以用h_n直接得出最后一个time_step的预测值,也可以用output取最后一个time_step的索引达到同样的目的。代码中特征数、时序长度都可以改动来满足自己的需要,如果想预测得到下面多个时序的值,那么对output需要多取一些值。label也要作相应的改动。
class GetData:
def __init__(self, stock_id, save_path):
self.stock_id = stock_id
self.save_path = save_path
self.data = None
def getData(self):
self.data = ts.get_hist_data(self.stock_id).iloc[::-1]
self.data = self.data[["open", "close", "high", "low", "volume"]]
self.open_min = self.data[‘open‘].min()
self.open_max = self.data["open"].max()
self.data = self.data.apply(lambda x: (x - min(x)) / (max(x) - min(x)))
self.data.to_csv(self.save_path)
return self.data
def process_data(self, n):
if self.data is None:
self.getData()
feature = [
self.data.iloc[i: i + n].values.tolist()
for i in range(len(self.data) - n + 2)
if i + n < len(self.data)
]
label = [
self.data.open.values[i + n]
for i in range(len(self.data) - n + 2)
if i + n < len(self.data)
]
train_x = feature[:500]
test_x = feature[500:]
train_y = label[:500]
test_y = label[500:]
return train_x, test_x, train_y, test_y
class Model(nn.Module):
def __init__(self, n):
super(Model, self).__init__()
self.lstm_layer = nn.LSTM(input_size=n, hidden_size=128, batch_first=True)
self.linear_layer = nn.Linear(in_features=128, out_features=1, bias=True)
def forward(self, x):
out1, (h_n, h_c) = self.lstm_layer(x)
a, b, c = h_n.shape
# 或者用 h_n 输出最后一次time_step 20 X 1
# out2 = self.linear_layer(h_n.reshape(a*b, c))
a, b, c = out1.shape
# 取out的最后一个time_step 100 X 1
out2 = self.linear_layer(out1.reshape(a*b, c))
out2 = out2.view(a,b,-1) # 20 X 5 X 1
out2 = out2[:,-1,:] # 20 X 1
return out2
def train_model(epoch, train_dataLoader, test_dataLoader):
train_loss = 0
test_loss = 0
for _ in range(epoch):
total_train_loss = 0
total_train_num = 0
total_test_loss = 0
total_test_num = 0
for x, y in tqdm(train_dataLoader, desc=‘Epoch: {}| Train Loss: {}| Test Loss: {}‘.format(_, train_loss, test_loss)):
x_num = len(x)
out = model(x)
loss = loss_func(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
total_train_num += x_num
train_loss = total_train_loss / total_train_num
torch.save(model.state_dict(), ‘E:/Tablefile/lstm_.pth‘)
def test_model(test_dataLoader_):
pred = []
label = []
model_ = Model(5)
model_.load_state_dict(torch.load(‘E:/Tablefile/lstm_.pth‘))
model_.eval()
total_test_loss = 0
total_test_num = 0
for x, y in test_dataLoader_:
x_num = len(x)
out = model_(x)
print(‘##‘, out.shape, y.shape)
loss = loss_func(out, y)
total_test_loss += loss.item()
total_test_num += x_num
pred.extend(out.data.squeeze(1).tolist())
label.extend(y.tolist())
test_loss = total_test_loss / total_test_num
return pred, label, test_loss
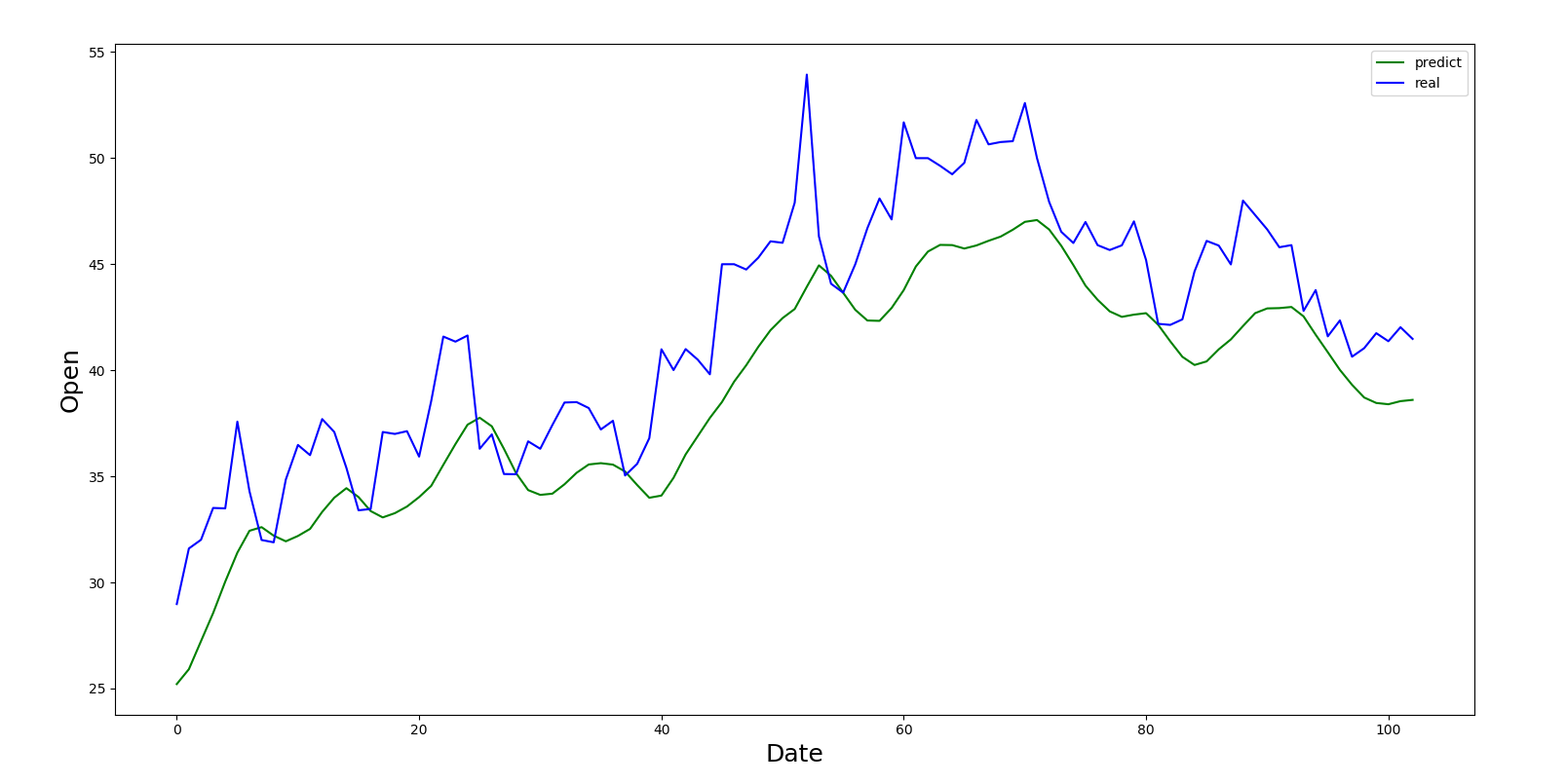
def plot_img(data, pred):
plt.figure(figsize=(18, 9))
plt.plot(range(len(pred)), pred, color=‘green‘)
plt.plot(range(len(data)), data, color=‘b‘)
plt.xlabel(‘Date‘, fontsize=18)
plt.ylabel(‘Open‘, fontsize=18)
plt.legend((‘predict‘, ‘real‘))
plt.show()
if __name__ == ‘__main__‘:
epoch = 10
days_num = 5 # 时序长度,可调整
feature = 5 # 变量特征数,可调整
batch_size = 20
# 数据读取
GD = GetData(stock_id=‘000963‘, save_path=‘E:/Tablefile/data.csv‘)
x_train, x_test, y_train, y_test = GD.process_data(days_num)
x_train = torch.tensor(x_train).float()
x_test = torch.tensor(x_test).float()
y_train = torch.tensor(y_train).float()
y_test = torch.tensor(y_test).float()
train_data = TensorDataset(x_train, y_train)
train_dataLoader = DataLoader(train_data, batch_size=batch_size)
test_data = TensorDataset(x_test, y_test)
test_dataLoader = DataLoader(test_data, batch_size=batch_size)
# 模型训练
model = Model(feature)
loss_func = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_model(epoch, train_dataLoader, test_dataLoader)
# 预测出图
pre, y, test_loss = test_model(test_dataLoader)
pred = [ele * (GD.open_max - GD.open_min) + GD.open_min for ele in pre] # 反归一化
data = [ele * (GD.open_max - GD.open_min) + GD.open_min for ele in y] # 反归一化
plot_img(data, pred)
LSTM可以通过输入门、遗忘门、更新门实现 cell state 长时期记忆的更新,通过输出门实现短期的输出,从而避免了RNN在长序列预测中长出现的梯度消失/梯度爆炸现象。
可以自由设置seq_len(时序长度)、input_size(特征数),输出1个time_step或者是多个time_step的值,有兴趣可以自行改动一下输出的time_step个数及其标签,自行测试。
本实战每次使用前5个time_step来预测下一个时刻的值,虽然预测出了较长时段的值,但是却完全依赖于前5个时间点的数据,即所有预测值都有实测值,该实验只有检验意义,而没有预报意义;可在通过前5个时间点预测出新值后,再将新值加入序列中进行循环预测,从而实现完全的预测,如有兴趣可以考虑不断加入预测值进行预报。
这里有LSTM的手撕代码,有兴趣可参考:https://blog.csdn.net/jining11/article/details/90675276
原文:https://www.cnblogs.com/ljwgis/p/15028502.html