排序算法是为了让一串数据能够按照要求排列的方法。
主要的内部排序可看下图,今天主要讲:冒泡排序和选择排序。
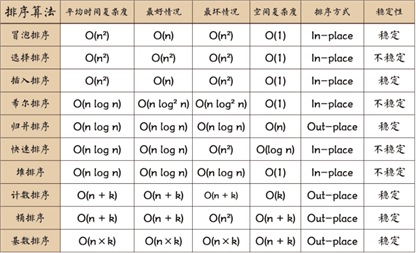
平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。
线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序;
O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。 希尔排序
线性阶 (O(n)) 排序 基数排序,此外还有桶、箱排序。
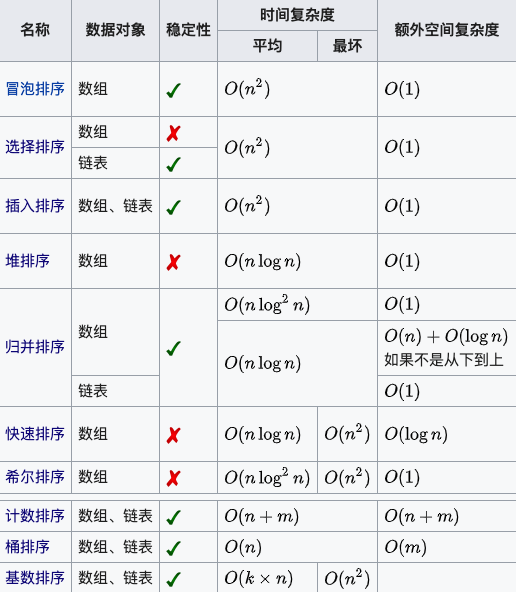
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
名词解释:
n:数据规模
k:"桶"的个数
In-place:占用常数内存,不占用额外内存
Out-place:占用额外内存
稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同
冒泡排序的算法是:相邻的数据比较,较大的值往后移,得出最大值后再重复该过程。冒泡排序也是最简单的排序之一。
技术:
for嵌套
外面的for控制比较的轮次
里面的for控制每一轮比较的次数
nums = [9, 6, 8, 2, 5]
L = len(nums)-1
for x in range(0, L):
for y in range(0, L - x):
if nums[y] > nums[y + 1]:
nums[y], nums[y + 1] = nums[y + 1], nums[y]
print(nums)
概念:第一个数据依次和后面比较,小的数据往前移,得到最小值后,再将第二个数据依次和后面对比,以此类推。
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n2) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处就是不占用额外的内存空间。
nums = [9, 6, 10, 12, 5] l = len(nums) for x in range(l): min = x for y in range(x + 1, l): if nums[y] < nums[min]: min = y nums[x], nums[min] = nums[min], nums[x] print(nums)
在进行排序之前,一定要保证数据时有序的,数据需要从小到大进行排序。[2,5,6,8,9,12,25,456]
def href_find(nums, search_num): max_index = len(nums)-1 min_index = 0 mid_index = (min_index + max_index) // 2 while True: # 无限循环 # 查询 if nums[mid_index] == search_num: return True if nums[mid_index] > search_num: max_index = mid_index - 1 mid_index = (min_index + max_index) // 2 elif nums[mid_index] < search_num: min_index = mid_index + 1 mid_index = (min_index + max_index) // 2 # 如果出现交叉,说明没有该数据 if max_index < min_index: return False
原文:https://www.cnblogs.com/wddwyw-jyb/p/15038759.html